 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Embedding Scaling in Collaborative Filtering
Sep 19, 2025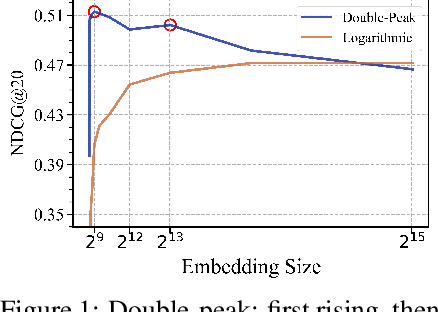

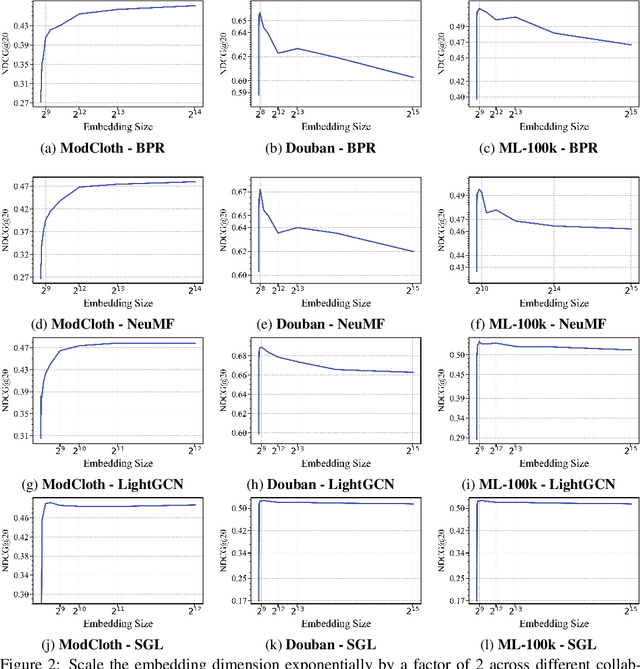

Scaling recommendation models into large recommendation models has become one of the most widely discussed topics. Recent efforts focus on components beyond the scaling embedding dimension, as it is believed that scaling embedding may lead to performance degradation. Although there have been some initial observations on embedding, the root cause of their non-scalability remains unclear. Moreover, whether performance degradation occurs across different types of models and datasets is still an unexplored area. Regarding the effect of embedding dimensions on performance, we conduct large-scale experiments across 10 datasets with varying sparsity levels and scales, using 4 representative classical architectures. We surprisingly observe two novel phenomenon: double-peak and logarithmic. For the former, as the embedding dimension increases, performance first improves, then declines, rises again, and eventually drops. For the latter, it exhibits a perfect logarithmic curve. Our contributions are threefold. First, we discover two novel phenomena when scaling collaborative filtering models. Second, we gain an understanding of the underlying causes of the double-peak phenomenon. Lastly, we theoretically analyze the noise robustness of collaborative filtering models, with results matching empirical observations.
Invariance Matters: Empowering Social Recommendation via Graph Invariant Learning
Apr 14, 2025Graph-based social recommendation systems have shown significant promise in enhancing recommendation performance, particularly in addressing the issue of data sparsity in user behaviors. Typically, these systems leverage Graph Neural Networks (GNNs) to capture user preferences by incorporating high-order social influences from observed social networks. However, existing graph-based social recommendations often overlook the fact that social networks are inherently noisy, containing task-irrelevant relationships that can hinder accurate user preference learning. The removal of these redundant social relations is crucial, yet it remains challenging due to the lack of ground truth. In this paper, we approach the social denoising problem from the perspective of graph invariant learning and propose a novel method, Social Graph Invariant Learning(SGIL). Specifically,SGIL aims to uncover stable user preferences within the input social graph, thereby enhancing the robustness of graph-based social recommendation systems. To achieve this goal, SGIL first simulates multiple noisy social environments through graph generators. It then seeks to learn environment-invariant user preferences by minimizing invariant risk across these environments. To further promote diversity in the generated social environments, we employ an adversarial training strategy to simulate more potential social noisy distributions. Extensive experimental results demonstrate the effectiveness of the proposed SGIL. The code is available at https://github.com/yimutianyang/SIGIR2025-SGIL.
Less is More: Information Bottleneck Denoised Multimedia Recommendation
Jan 21, 2025Empowered by semantic-rich content information, multimedia recommendation has emerged as a potent personalized technique. Current endeavors center around harnessing multimedia content to refine item representation or uncovering latent item-item structures based on modality similarity. Despite the effectiveness, we posit that these methods are usually suboptimal due to the introduction of irrelevant multimedia features into recommendation tasks. This stems from the fact that generic multimedia feature extractors, while well-designed for domain-specific tasks, can inadvertently introduce task-irrelevant features, leading to potential misguidance of recommenders. In this work, we propose a denoised multimedia recommendation paradigm via the Information Bottleneck principle (IB). Specifically, we propose a novel Information Bottleneck denoised Multimedia Recommendation (IBMRec) model to tackle the irrelevant feature issue. IBMRec removes task-irrelevant features from both feature and item-item structure perspectives, which are implemented by two-level IB learning modules: feature-level (FIB) and graph-level (GIB). In particular, FIB focuses on learning the minimal yet sufficient multimedia features. This is achieved by maximizing the mutual information between multimedia representation and recommendation tasks, while concurrently minimizing it between multimedia representation and pre-trained multimedia features. Furthermore, GIB is designed to learn the robust item-item graph structure, it refines the item-item graph based on preference affinity, then minimizes the mutual information between the original graph and the refined one. Extensive experiments across three benchmarks validate the effectiveness of our proposed model, showcasing high performance, and applicability to various multimedia recommenders.
Boosting Multimedia Recommendation via Separate Generic and Unique Awareness
Jun 12, 2024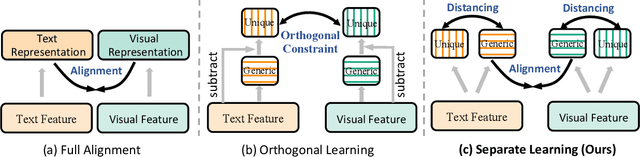
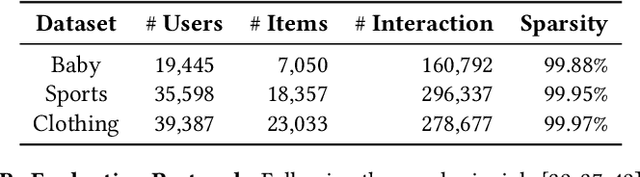
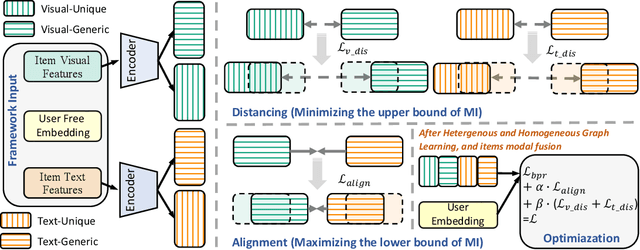
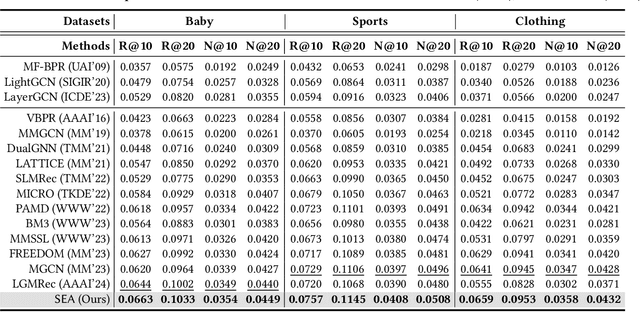
Multimedia recommendation, which incorporates various modalities (e.g., images, texts, etc.) into user or item representation to improve recommendation quality, has received widespread attention. Recent methods mainly focus on cross-modal alignment with self-supervised learning to obtain higher quality representation. Despite remarkable performance, we argue that there is still a limitation: completely aligning representation undermines modality-unique information. We consider that cross-modal alignment is right, but it should not be the entirety, as different modalities contain generic information between them, and each modality also contains unique information. Simply aligning each modality may ignore modality-unique features, thus degrading the performance of multimedia recommendation. To tackle the above limitation, we propose a Separate Alignment aNd Distancing framework (SAND) for multimedia recommendation, which concurrently learns both modal-unique and -generic representation to achieve more comprehensive items representation. First, we split each modal feature into generic and unique part. Then, in the alignment module, for better integration of semantic information between different modalities , we design a SoloSimLoss to align generic modalities. Furthermore, in the distancing module, we aim to distance the unique modalities from the modal-generic so that each modality retains its unique and complementary information. In the light of the flexibility of our framework, we give two technical solutions, the more capable mutual information minimization and the simple negative l2 distance. Finally, extensive experimental results on three popular datasets demonstrate the effectiveness and generalization of our proposed framework.
Graph Bottlenecked Social Recommendation
Jun 12, 2024



With the emergence of social networks, social recommendation has become an essential technique for personalized services. Recently, graph-based social recommendations have shown promising results by capturing the high-order social influence. Most empirical studies of graph-based social recommendations directly take the observed social networks into formulation, and produce user preferences based on social homogeneity. Despite the effectiveness, we argue that social networks in the real-world are inevitably noisy~(existing redundant social relations), which may obstruct precise user preference characterization. Nevertheless, identifying and removing redundant social relations is challenging due to a lack of labels. In this paper, we focus on learning the denoised social structure to facilitate recommendation tasks from an information bottleneck perspective. Specifically, we propose a novel Graph Bottlenecked Social Recommendation (GBSR) framework to tackle the social noise issue.GBSR is a model-agnostic social denoising framework, that aims to maximize the mutual information between the denoised social graph and recommendation labels, meanwhile minimizing it between the denoised social graph and the original one. This enables GBSR to learn the minimal yet sufficient social structure, effectively reducing redundant social relations and enhancing social recommendations. Technically, GBSR consists of two elaborate components, preference-guided social graph refinement, and HSIC-based bottleneck learning. Extensive experimental results demonstrate the superiority of the proposed GBSR, including high performances and good generality combined with various backbones. Our code is available at: https://github.com/yimutianyang/KDD24-GBSR.
Double Correction Framework for Denoising Recommendation
May 18, 2024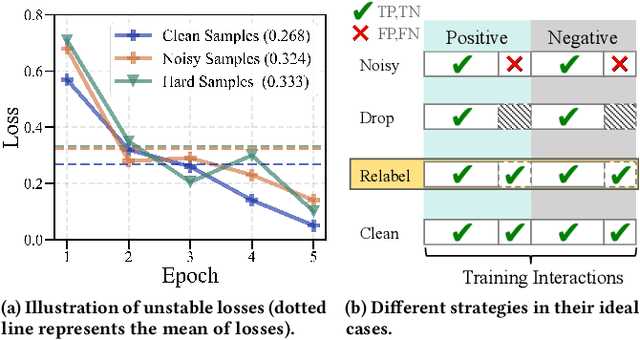

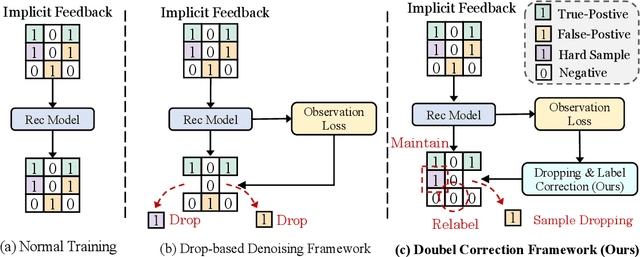
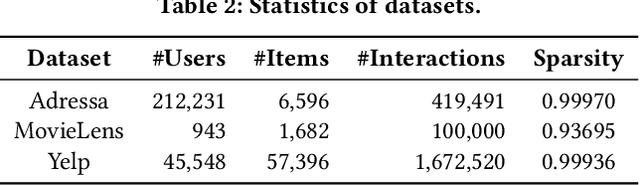
As its availability and generality in online services, implicit feedback is more commonly used in recommender systems. However, implicit feedback usually presents noisy samples in real-world recommendation scenarios (such as misclicks or non-preferential behaviors), which will affect precise user preference learning. To overcome the noisy samples problem, a popular solution is based on dropping noisy samples in the model training phase, which follows the observation that noisy samples have higher training losses than clean samples. Despite the effectiveness, we argue that this solution still has limits. (1) High training losses can result from model optimization instability or hard samples, not just noisy samples. (2) Completely dropping of noisy samples will aggravate the data sparsity, which lacks full data exploitation. To tackle the above limitations, we propose a Double Correction Framework for Denoising Recommendation (DCF), which contains two correction components from views of more precise sample dropping and avoiding more sparse data. In the sample dropping correction component, we use the loss value of the samples over time to determine whether it is noise or not, increasing dropping stability. Instead of averaging directly, we use the damping function to reduce the bias effect of outliers. Furthermore, due to the higher variance exhibited by hard samples, we derive a lower bound for the loss through concentration inequality to identify and reuse hard samples. In progressive label correction, we iteratively re-label highly deterministic noisy samples and retrain them to further improve performance. Finally, extensive experimental results on three datasets and four backbones demonstrate the effectiveness and generalization of our proposed framework.