 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Correction Framework for Denoising Recommendation
May 18, 2024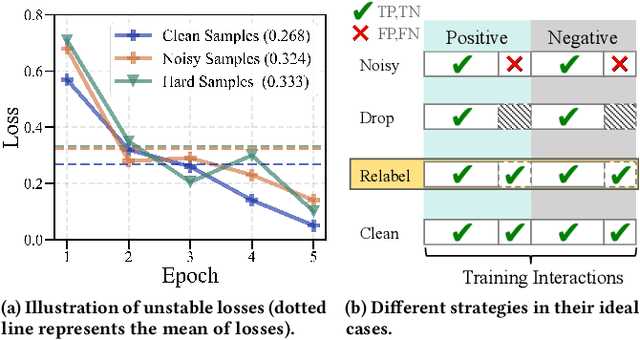

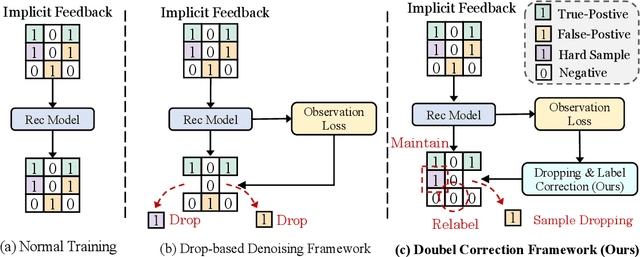
As its availability and generality in online services, implicit feedback is more commonly used in recommender systems. However, implicit feedback usually presents noisy samples in real-world recommendation scenarios (such as misclicks or non-preferential behaviors), which will affect precise user preference learning. To overcome the noisy samples problem, a popular solution is based on dropping noisy samples in the model training phase, which follows the observation that noisy samples have higher training losses than clean samples. Despite the effectiveness, we argue that this solution still has limits. (1) High training losses can result from model optimization instability or hard samples, not just noisy samples. (2) Completely dropping of noisy samples will aggravate the data sparsity, which lacks full data exploitation. To tackle the above limitations, we propose a Double Correction Framework for Denoising Recommendation (DCF), which contains two correction components from views of more precise sample dropping and avoiding more sparse data. In the sample dropping correction component, we use the loss value of the samples over time to determine whether it is noise or not, increasing dropping stability. Instead of averaging directly, we use the damping function to reduce the bias effect of outliers. Furthermore, due to the higher variance exhibited by hard samples, we derive a lower bound for the loss through concentration inequality to identify and reuse hard samples. In progressive label correction, we iteratively re-label highly deterministic noisy samples and retrain them to further improve performance. Finally, extensive experimental results on three datasets and four backbones demonstrate the effectiveness and generalization of our proposed framework.