 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Transfers Safety? Identifying and Targeting Cross-Lingual Shared Safety Neurons
Feb 01, 2026Multilingual safety remains significantly imbalanced, leaving non-high-resource (NHR) languages vulnerable compared to robust high-resource (HR) ones. Moreover, the neural mechanisms driving safety alignment remain unclear despite observed cross-lingual representation transfer. In this paper, we find that LLMs contain a set of cross-lingual shared safety neurons (SS-Neurons), a remarkably small yet critical neuronal subset that jointly regulates safety behavior across languages. We first identify monolingual safety neurons (MS-Neurons) and validate their causal role in safety refusal behavior through targeted activation and suppression. Our cross-lingual analyses then identify SS-Neurons as the subset of MS-Neurons shared between HR and NHR languages, serving as a bridge to transfer safety capabilities from HR to NHR domains. We observe that suppressing these neurons causes concurrent safety drops across NHR languages, whereas reinforcing them improves cross-lingual defensive consistency. Building on these insights, we propose a simple neuron-oriented training strategy that targets SS-Neurons based on language resource distribution and model architecture. Experiments demonstrate that fine-tuning this tiny neuronal subset outperforms state-of-the-art methods, significantly enhancing NHR safety while maintaining the model's general capabilities. The code and dataset will be available athttps://github.com/1518630367/SS-Neuron-Expansion.
PASs-MoE: Mitigating Misaligned Co-drift among Router and Experts via Pathway Activation Subspaces for Continual Learning
Jan 19, 2026Continual instruction tuning (CIT) requires multimodal large language models (MLLMs) to adapt to a stream of tasks without forgetting prior capabilities. A common strategy is to isolate updates by routing inputs to different LoRA experts. However, existing LoRA-based Mixture-of-Experts (MoE) methods often jointly update the router and experts in an indiscriminate way, causing the router's preferences to co-drift with experts' adaptation pathways and gradually deviate from early-stage input-expert specialization. We term this phenomenon Misaligned Co-drift, which blurs expert responsibilities and exacerbates forgetting.To address this, we introduce the pathway activation subspace (PASs), a LoRA-induced subspace that reflects which low-rank pathway directions an input activates in each expert, providing a capability-aligned coordinate system for routing and preservation. Based on PASs, we propose a fixed-capacity PASs-based MoE-LoRA method with two components: PAS-guided Reweighting, which calibrates routing using each expert's pathway activation signals, and PAS-aware Rank Stabilization, which selectively stabilizes rank directions important to previous tasks. Experiments on a CIT benchmark show that our approach consistently outperforms a range of conventional continual learning baselines and MoE-LoRA variants in both accuracy and anti-forgetting without adding parameters. Our code will be released upon acceptance.
BalDRO: A Distributionally Robust Optimization based Framework for Large Language Model Unlearning
Jan 14, 2026As Large Language Models (LLMs) increasingly shape online content, removing targeted information from well-trained LLMs (also known as LLM unlearning) has become critical for web governance. A key challenge lies in sample-wise imbalance within the forget set: different samples exhibit widely varying unlearning difficulty, leading to asynchronous forgetting where some knowledge remains insufficiently erased while others become over-forgotten. To address this, we propose BalDRO, a novel and efficient framework for balanced LLM unlearning. BalDRO formulates unlearning as a min-sup process: an inner step identifies a worst-case data distribution that emphasizes hard-to-unlearn samples, while an outer step updates model parameters under this distribution. We instantiate BalDRO via two efficient variants: BalDRO-G, a discrete GroupDRO-based approximation focusing on high-loss subsets, and BalDRO-DV, a continuous Donsker-Varadhan dual method enabling smooth adaptive weighting within standard training pipelines. Experiments on TOFU and MUSE show that BalDRO significantly improves both forgetting quality and model utility over existing methods, and we release code for reproducibility.
VisPlay: Self-Evolving Vision-Language Models from Images
Nov 19, 2025Reinforcement learning (RL) provides a principled framework for improving Vision-Language Models (VLMs) on complex reasoning tasks. However, existing RL approaches often rely on human-annotated labels or task-specific heuristics to define verifiable rewards, both of which are costly and difficult to scale. We introduce VisPlay, a self-evolving RL framework that enables VLMs to autonomously improve their reasoning abilities using large amounts of unlabeled image data. Starting from a single base VLM, VisPlay assigns the model into two interacting roles: an Image-Conditioned Questioner that formulates challenging yet answerable visual questions, and a Multimodal Reasoner that generates silver responses. These roles are jointly trained with Group Relative Policy Optimization (GRPO), which incorporates diversity and difficulty rewards to balance the complexity of generated questions with the quality of the silver answers. VisPlay scales efficiently across two model families. When trained on Qwen2.5-VL and MiMo-VL, VisPlay achieves consistent improvements in visual reasoning, compositional generalization, and hallucination reduction across eight benchmarks, including MM-Vet and MMMU, demonstrating a scalable path toward self-evolving multimodal intelligence. The project page is available at https://bruno686.github.io/VisPlay/
Debate over Mixed-knowledge: A Robust Multi-Agent Framework for Incomplete Knowledge Graph Question Answering
Nov 15, 2025Knowledge Graph Question Answering (KGQA) aims to improve factual accuracy by leveraging structured knowledge. However, real-world Knowledge Graphs (KGs) are often incomplete, leading to the problem of Incomplete KGQA (IKGQA). A common solution is to incorporate external data to fill knowledge gaps, but existing methods lack the capacity to adaptively and contextually fuse multiple sources, failing to fully exploit their complementary strengths. To this end, we propose Debate over Mixed-knowledge (DoM), a novel framework that enables dynamic integration of structured and unstructured knowledge for IKGQA. Built upon the Multi-Agent Debate paradigm, DoM assigns specialized agents to perform inference over knowledge graphs and external texts separately, and coordinates their outputs through iterative interaction. It decomposes the input question into sub-questions, retrieves evidence via dual agents (KG and Retrieval-Augmented Generation, RAG), and employs a judge agent to evaluate and aggregate intermediate answers. This collaboration exploits knowledge complementarity and enhances robustness to KG incompleteness. In addition, existing IKGQA datasets simulate incompleteness by randomly removing triples, failing to capture the irregular and unpredictable nature of real-world knowledge incompleteness. To address this, we introduce a new dataset, Incomplete Knowledge Graph WebQuestions, constructed by leveraging real-world knowledge updates. These updates reflect knowledge beyond the static scope of KGs, yielding a more realistic and challenging benchmark. Through extensive experiments, we show that DoM consistently outperforms state-of-the-art baselines.
A Survey on Generative Recommendation: Data, Model, and Tasks
Oct 31, 2025Recommender systems serve as foundational infrastructure in modern information ecosystems, helping users navigate digital content and discover items aligned with their preferences. At their core, recommender systems address a fundamental problem: matching users with items. Over the past decades, the field has experienced successive paradigm shifts, from collaborative filtering and matrix factorization in the machine learning era to neural architectures in the deep learning era. Recently, the emergence of generative models, especially large language models (LLMs) and diffusion models, have sparked a new paradigm: generative recommendation, which reconceptualizes recommendation as a generation task rather than discriminative scoring. This survey provides a comprehensive examination through a unified tripartite framework spanning data, model, and task dimensions. Rather than simply categorizing works, we systematically decompose approaches into operational stages-data augmentation and unification, model alignment and training, task formulation and execution. At the data level, generative models enable knowledge-infused augmentation and agent-based simulation while unifying heterogeneous signals. At the model level, we taxonomize LLM-based methods, large recommendation models, and diffusion approaches, analyzing their alignment mechanisms and innovations. At the task level, we illuminate new capabilities including conversational interaction, explainable reasoning, and personalized content generation. We identify five key advantages: world knowledge integration, natural language understanding, reasoning capabilities, scaling laws, and creative generation. We critically examine challenges in benchmark design, model robustness, and deployment efficiency, while charting a roadmap toward intelligent recommendation assistants that fundamentally reshape human-information interaction.
Understanding Embedding Scaling in Collaborative Filtering
Sep 19, 2025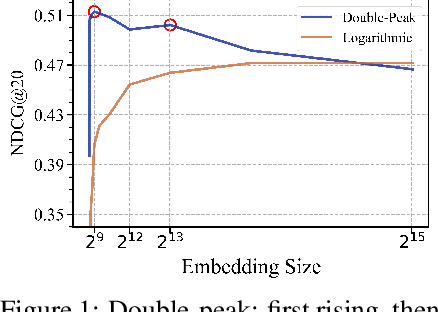

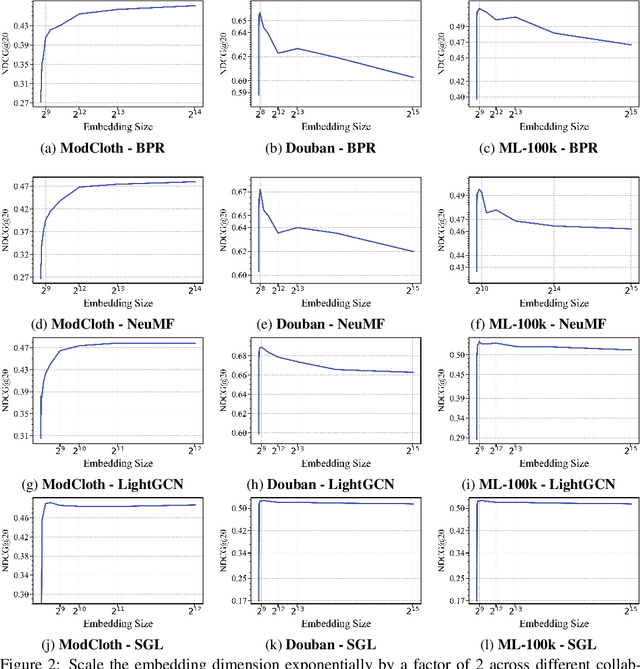

Scaling recommendation models into large recommendation models has become one of the most widely discussed topics. Recent efforts focus on components beyond the scaling embedding dimension, as it is believed that scaling embedding may lead to performance degradation. Although there have been some initial observations on embedding, the root cause of their non-scalability remains unclear. Moreover, whether performance degradation occurs across different types of models and datasets is still an unexplored area. Regarding the effect of embedding dimensions on performance, we conduct large-scale experiments across 10 datasets with varying sparsity levels and scales, using 4 representative classical architectures. We surprisingly observe two novel phenomenon: double-peak and logarithmic. For the former, as the embedding dimension increases, performance first improves, then declines, rises again, and eventually drops. For the latter, it exhibits a perfect logarithmic curve. Our contributions are threefold. First, we discover two novel phenomena when scaling collaborative filtering models. Second, we gain an understanding of the underlying causes of the double-peak phenomenon. Lastly, we theoretically analyze the noise robustness of collaborative filtering models, with results matching empirical observations.
Align-for-Fusion: Harmonizing Triple Preferences via Dual-oriented Diffusion for Cross-domain Sequential Recommendation
Aug 07, 2025Personalized sequential recommendation aims to predict appropriate items for users based on their behavioral sequences. To alleviate data sparsity and interest drift issues, conventional approaches typically incorporate auxiliary behaviors from other domains via cross-domain transition. However, existing cross-domain sequential recommendation (CDSR) methods often follow an align-then-fusion paradigm that performs representation-level alignment across multiple domains and combines them mechanically for recommendation, overlooking the fine-grained fusion of domain-specific preferences. Inspired by recent advances in diffusion models (DMs) for distribution matching, we propose an align-for-fusion framework for CDSR to harmonize triple preferences via dual-oriented DMs, termed HorizonRec. Specifically, we investigate the uncertainty injection of DMs and identify stochastic noise as a key source of instability in existing DM-based recommenders. To address this, we introduce a mixed-conditioned distribution retrieval strategy that leverages distributions retrieved from users' authentic behavioral logic as semantic bridges across domains, enabling consistent multi-domain preference modeling. Furthermore, we propose a dual-oriented preference diffusion method to suppress potential noise and emphasize target-relevant interests during multi-domain user representation fusion. Extensive experiments on four CDSR datasets from two distinct platforms demonstrate the effectiveness and robustness of HorizonRec in fine-grained triple-domain preference fusion.
Invariance Matters: Empowering Social Recommendation via Graph Invariant Learning
Apr 14, 2025Graph-based social recommendation systems have shown significant promise in enhancing recommendation performance, particularly in addressing the issue of data sparsity in user behaviors. Typically, these systems leverage Graph Neural Networks (GNNs) to capture user preferences by incorporating high-order social influences from observed social networks. However, existing graph-based social recommendations often overlook the fact that social networks are inherently noisy, containing task-irrelevant relationships that can hinder accurate user preference learning. The removal of these redundant social relations is crucial, yet it remains challenging due to the lack of ground truth. In this paper, we approach the social denoising problem from the perspective of graph invariant learning and propose a novel method, Social Graph Invariant Learning(SGIL). Specifically,SGIL aims to uncover stable user preferences within the input social graph, thereby enhancing the robustness of graph-based social recommendation systems. To achieve this goal, SGIL first simulates multiple noisy social environments through graph generators. It then seeks to learn environment-invariant user preferences by minimizing invariant risk across these environments. To further promote diversity in the generated social environments, we employ an adversarial training strategy to simulate more potential social noisy distributions. Extensive experimental results demonstrate the effectiveness of the proposed SGIL. The code is available at https://github.com/yimutianyang/SIGIR2025-SGIL.
Less is More: Information Bottleneck Denoised Multimedia Recommendation
Jan 21, 2025Empowered by semantic-rich content information, multimedia recommendation has emerged as a potent personalized technique. Current endeavors center around harnessing multimedia content to refine item representation or uncovering latent item-item structures based on modality similarity. Despite the effectiveness, we posit that these methods are usually suboptimal due to the introduction of irrelevant multimedia features into recommendation tasks. This stems from the fact that generic multimedia feature extractors, while well-designed for domain-specific tasks, can inadvertently introduce task-irrelevant features, leading to potential misguidance of recommenders. In this work, we propose a denoised multimedia recommendation paradigm via the Information Bottleneck principle (IB). Specifically, we propose a novel Information Bottleneck denoised Multimedia Recommendation (IBMRec) model to tackle the irrelevant feature issue. IBMRec removes task-irrelevant features from both feature and item-item structure perspectives, which are implemented by two-level IB learning modules: feature-level (FIB) and graph-level (GIB). In particular, FIB focuses on learning the minimal yet sufficient multimedia features. This is achieved by maximizing the mutual information between multimedia representation and recommendation tasks, while concurrently minimizing it between multimedia representation and pre-trained multimedia features. Furthermore, GIB is designed to learn the robust item-item graph structure, it refines the item-item graph based on preference affinity, then minimizes the mutual information between the original graph and the refined one. Extensive experiments across three benchmarks validate the effectiveness of our proposed model, showcasing high performance, and applicability to various multimedia recommenders.