 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Multimedia Recommendation via Separate Generic and Unique Awareness
Paper and Code
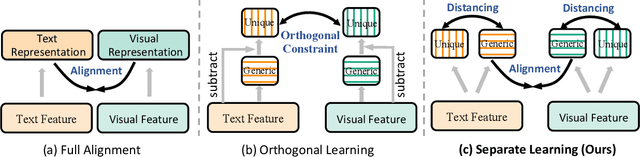
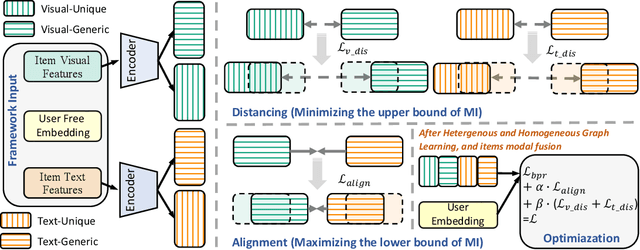
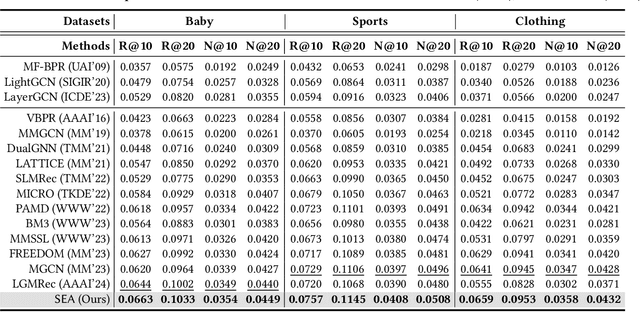
Multimedia recommendation, which incorporates various modalities (e.g., images, texts, etc.) into user or item representation to improve recommendation quality, has received widespread attention. Recent methods mainly focus on cross-modal alignment with self-supervised learning to obtain higher quality representation. Despite remarkable performance, we argue that there is still a limitation: completely aligning representation undermines modality-unique information. We consider that cross-modal alignment is right, but it should not be the entirety, as different modalities contain generic information between them, and each modality also contains unique information. Simply aligning each modality may ignore modality-unique features, thus degrading the performance of multimedia recommendation. To tackle the above limitation, we propose a Separate Alignment aNd Distancing framework (SAND) for multimedia recommendation, which concurrently learns both modal-unique and -generic representation to achieve more comprehensive items representation. First, we split each modal feature into generic and unique part. Then, in the alignment module, for better integration of semantic information between different modalities , we design a SoloSimLoss to align generic modalities. Furthermore, in the distancing module, we aim to distance the unique modalities from the modal-generic so that each modality retains its unique and complementary information. In the light of the flexibility of our framework, we give two technical solutions, the more capable mutual information minimization and the simple negative l2 distance. Finally, extensive experimental results on three popular datasets demonstrate the effectiveness and generalization of our proposed framework.