 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Disentangle Causal Model: Enhancing Causal Inference in Networked Observational Data
Dec 05, 2024



Estimating individual treatment effects (ITE) from observational data is a critical task across various domains. However, many existing works on ITE estimation overlook the influence of hidden confounders, which remain unobserved at the individual unit level. To address this limitation, researchers have utilized graph neural networks to aggregate neighbors' features to capture the hidden confounders and mitigate confounding bias by minimizing the discrepancy of confounder representations between the treated and control groups. Despite the success of these approaches, practical scenarios often treat all features as confounders and involve substantial differences in feature distributions between the treated and control groups. Confusing the adjustment and confounder and enforcing strict balance on the confounder representations could potentially undermine the effectiveness of outcome prediction. To mitigate this issue, we propose a novel framework called the \textit{Graph Disentangle Causal model} (GDC) to conduct ITE estimation in the network setting. GDC utilizes a causal disentangle module to separate unit features into adjustment and confounder representations. Then we design a graph aggregation module consisting of three distinct graph aggregators to obtain adjustment, confounder, and counterfactual confounder representations. Finally, a causal constraint module is employed to enforce the disentangled representations as true causal factors. The effectiveness of our proposed method is demonstrated by conducting comprehensive experiments on two networked datasets.
TS3IM: Unveiling Structural Similarity in Time Series through Image Similarity Assessment Insights
May 10, 2024



In the realm of time series analysis, accurately measuring similarity is crucial for applications such as forecasting, anomaly detection, and clustering. However, existing metrics often fail to capture the complex, multidimensional nature of time series data, limiting their effectiveness and application. This paper introduces the Structured Similarity Index Measure for Time Series (TS3IM), a novel approach inspired by the success of the Structural Similarity Index Measure (SSIM) in image analysis, tailored to address these limitations by assessing structural similarity in time series. TS3IM evaluates multiple dimensions of similarity-trend, variability, and structural integrity-offering a more nuanced and comprehensive measure. This metric represents a significant leap forward, providing a robust tool for analyzing temporal data and offering more accurate and comprehensive sequence analysis and decision support in fields such as monitoring power consumption, analyzing traffic flow, and adversarial recognition. Our extensive experimental results also show that compared with traditional methods that rely heavily on computational correlation, TS3IM is 1.87 times more similar to Dynamic Time Warping (DTW) in evaluation results and improves by more than 50% in adversarial recognition.
Conditional Attention Networks for Distilling Knowledge Graphs in Recommendation
Nov 03, 2021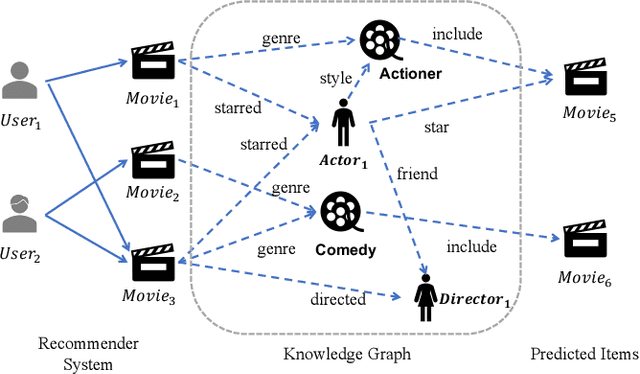
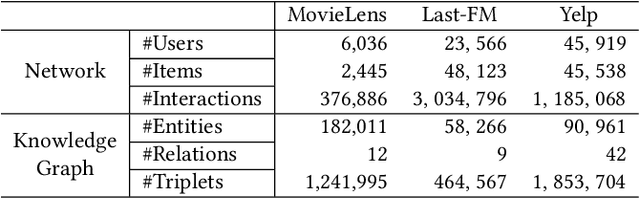
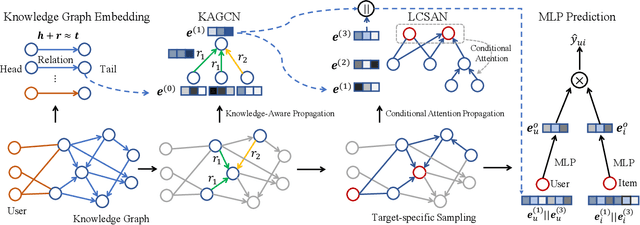
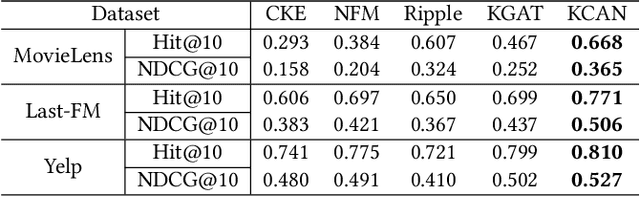
Knowledge graph is generally incorporated into recommender systems to improve overall performance. Due to the generalization and scale of the knowledge graph, most knowledge relationships are not helpful for a target user-item prediction. To exploit the knowledge graph to capture target-specific knowledge relationships in recommender systems, we need to distill the knowledge graph to reserve the useful information and refine the knowledge to capture the users' preferences. To address the issues, we propose Knowledge-aware Conditional Attention Networks (KCAN), which is an end-to-end model to incorporate knowledge graph into a recommender system. Specifically, we use a knowledge-aware attention propagation manner to obtain the node representation first, which captures the global semantic similarity on the user-item network and the knowledge graph. Then given a target, i.e., a user-item pair, we automatically distill the knowledge graph into the target-specific subgraph based on the knowledge-aware attention. Afterward, by applying a conditional attention aggregation on the subgraph, we refine the knowledge graph to obtain target-specific node representations. Therefore, we can gain both representability and personalization to achieve overall performance. Experimental results on real-world datasets demonstrate the effectiveness of our framework over the state-of-the-art algorithms.