 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAT: RunAnyThing via Fully Automated Environment Configuration
Apr 25, 2026Automating repository-level software engineering tasks is a foundational challenge for autonomous code agents, largely due to the difficulty of configuring executable environments. However, manual configuration remains a labor-intensive bottleneck, necessitating a transition toward fully automated environment configuration. Existing approaches often rely on pre-defined artifacts or are restricted to specific programming languages, limiting their applicability to real-world repositories. In this paper, we first propose RAT (RunAnyThing), a language-agnostic framework for automated environment configuration on arbitrary repositories. RAT features a multi-stage pipeline that integrates semantic initialization, a planning mechanism, specialized toolset, and a robust sandbox for configuration. Furthermore, to enable rigorous evaluation, we propose RATBench, a benchmark that reflects the the distribution and heterogeneity of real-world repositories. Extensive experiments demonstrate that RAT achieves state-of-the-art performance, improving the Environment Setup Success Rate (ESSR) by an average of 29.6% over strong baselines.
When Sharpening Becomes Collapse: Sampling Bias and Semantic Coupling in RL with Verifiable Rewards
Jan 26, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is a central paradigm for turning large language models (LLMs) into reliable problem solvers, especially in logic-heavy domains. Despite its empirical success, it remains unclear whether RLVR elicits novel capabilities or merely sharpens the distribution over existing knowledge. We study this by formalizing over-sharpening, a phenomenon where the policy collapses onto limited modes, suppressing valid alternatives. At a high level, we discover finite-batch updates intrinsically bias learning toward sampled modes, triggering a collapse that propagates globally via semantic coupling. To mitigate this, we propose inverse-success advantage calibration to prioritize difficult queries and distribution-level calibration to diversify sampling via a memory network. Empirical evaluations validate that our strategies can effectively improve generalization.
Mix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging
Feb 13, 2025
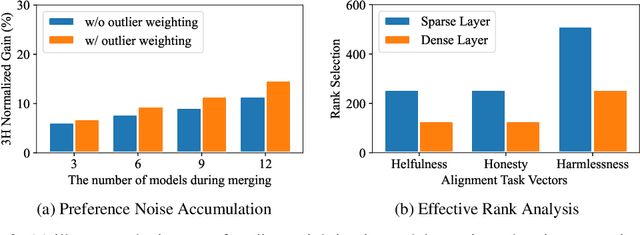

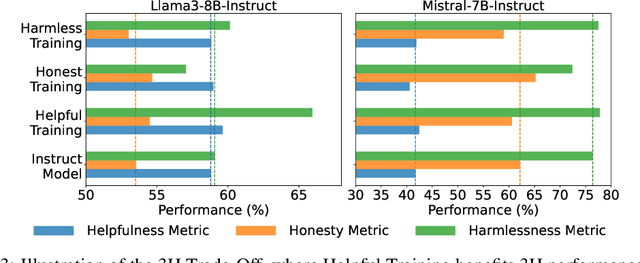
Achieving balanced alignment of large language models (LLMs) in terms of Helpfulness, Honesty, and Harmlessness (3H optimization) constitutes a cornerstone of responsible AI, with existing methods like data mixture strategies facing limitations including reliance on expert knowledge and conflicting optimization signals. While model merging offers a promising alternative by integrating specialized models, its potential for 3H optimization remains underexplored. This paper establishes the first comprehensive benchmark for model merging in 3H-aligned LLMs, systematically evaluating 15 methods (12 training-free merging and 3 data mixture techniques) across 10 datasets associated with 5 annotation dimensions, 2 LLM families, and 2 training paradigms. Our analysis reveals three pivotal insights: (i) previously overlooked collaborative/conflicting relationships among 3H dimensions, (ii) the consistent superiority of model merging over data mixture approaches in balancing alignment trade-offs, and (iii) the critical role of parameter-level conflict resolution through redundant component pruning and outlier mitigation. Building on these findings, we propose R-TSVM, a Reweighting-enhanced Task Singular Vector Merging method that incorporates outlier-aware parameter weighting and sparsity-adaptive rank selection strategies adapted to the heavy-tailed parameter distribution and sparsity for LLMs, further improving LLM alignment across multiple evaluations. We release our trained models for further exploration.
IceBerg: Debiased Self-Training for Class-Imbalanced Node Classification
Feb 10, 2025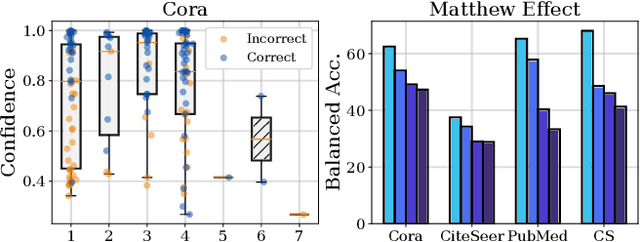
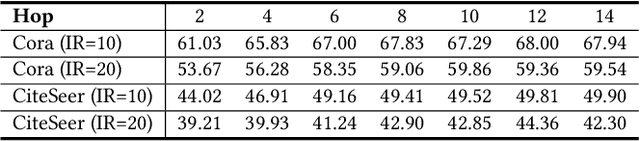
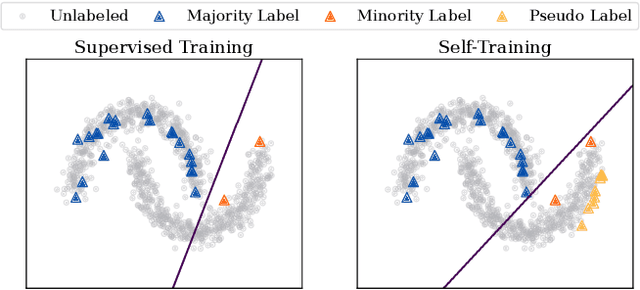
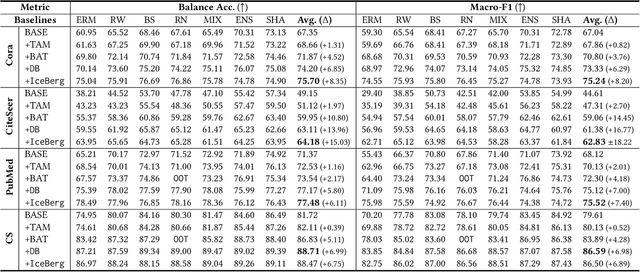
Graph Neural Networks (GNNs) have achieved great success in dealing with non-Euclidean graph-structured data and have been widely deployed in many real-world applications. However, their effectiveness is often jeopardized under class-imbalanced training sets. Most existing studies have analyzed class-imbalanced node classification from a supervised learning perspective, but they do not fully utilize the large number of unlabeled nodes in semi-supervised scenarios. We claim that the supervised signal is just the tip of the iceberg and a large number of unlabeled nodes have not yet been effectively utilized. In this work, we propose IceBerg, a debiased self-training framework to address the class-imbalanced and few-shot challenges for GNNs at the same time. Specifically, to figure out the Matthew effect and label distribution shift in self-training, we propose Double Balancing, which can largely improve the performance of existing baselines with just a few lines of code as a simple plug-and-play module. Secondly, to enhance the long-range propagation capability of GNNs, we disentangle the propagation and transformation operations of GNNs. Therefore, the weak supervision signals can propagate more effectively to address the few-shot issue. In summary, we find that leveraging unlabeled nodes can significantly enhance the performance of GNNs in class-imbalanced and few-shot scenarios, and even small, surgical modifications can lead to substantial performance improvements. Systematic experiments on benchmark datasets show that our method can deliver considerable performance gain over existing class-imbalanced node classification baselines. Additionally, due to IceBerg's outstanding ability to leverage unsupervised signals, it also achieves state-of-the-art results in few-shot node classification scenarios. The code of IceBerg is available at: https://github.com/ZhixunLEE/IceBerg.
Optimizing Long-tailed Link Prediction in Graph Neural Networks through Structure Representation Enhancement
Jul 30, 2024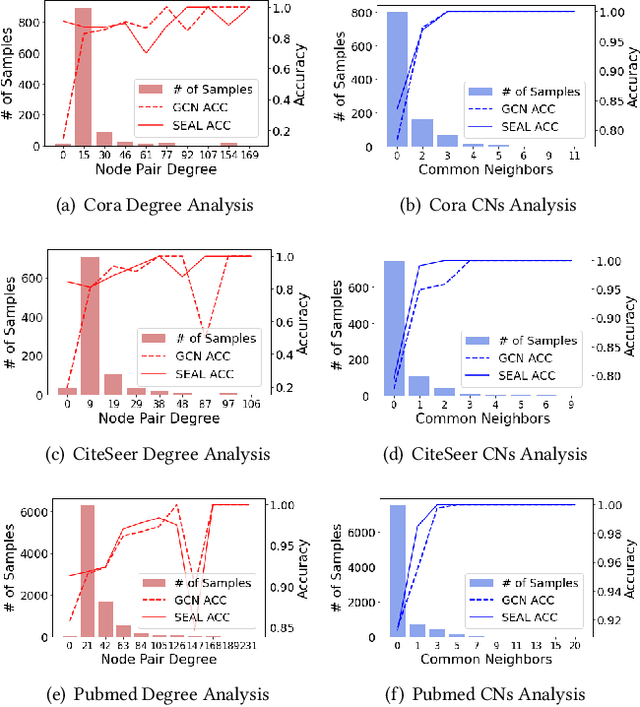
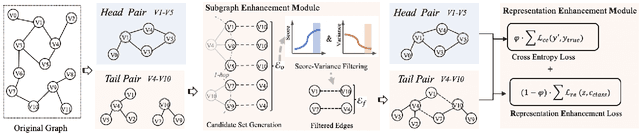
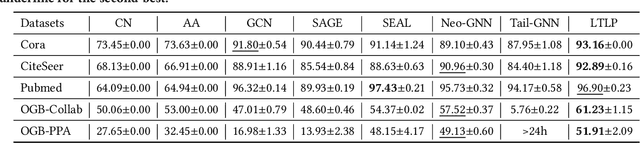
Link prediction, as a fundamental task for graph neural networks (GNNs), has boasted significant progress in varied domains. Its success is typically influenced by the expressive power of node representation, but recent developments reveal the inferior performance of low-degree nodes owing to their sparse neighbor connections, known as the degree-based long-tailed problem. Will the degree-based long-tailed distribution similarly constrain the efficacy of GNNs on link prediction? Unexpectedly, our study reveals that only a mild correlation exists between node degree and predictive accuracy, and more importantly, the number of common neighbors between node pairs exhibits a strong correlation with accuracy. Considering node pairs with less common neighbors, i.e., tail node pairs, make up a substantial fraction of the dataset but achieve worse performance, we propose that link prediction also faces the long-tailed problem. Therefore, link prediction of GNNs is greatly hindered by the tail node pairs. After knowing the weakness of link prediction, a natural question is how can we eliminate the negative effects of the skewed long-tailed distribution on common neighbors so as to improve the performance of link prediction? Towards this end, we introduce our long-tailed framework (LTLP), which is designed to enhance the performance of tail node pairs on link prediction by increasing common neighbors. Two key modules in LTLP respectively supplement high-quality edges for tail node pairs and enforce representational alignment between head and tail node pairs within the same category, thereby improving the performance of tail node pairs.
Financial Default Prediction via Motif-preserving Graph Neural Network with Curriculum Learning
Mar 11, 2024



User financial default prediction plays a critical role in credit risk forecasting and management. It aims at predicting the probability that the user will fail to make the repayments in the future. Previous methods mainly extract a set of user individual features regarding his own profiles and behaviors and build a binary-classification model to make default predictions. However, these methods cannot get satisfied results, especially for users with limited information. Although recent efforts suggest that default prediction can be improved by social relations, they fail to capture the higher-order topology structure at the level of small subgraph patterns. In this paper, we fill in this gap by proposing a motif-preserving Graph Neural Network with curriculum learning (MotifGNN) to jointly learn the lower-order structures from the original graph and higherorder structures from multi-view motif-based graphs for financial default prediction. Specifically, to solve the problem of weak connectivity in motif-based graphs, we design the motif-based gating mechanism. It utilizes the information learned from the original graph with good connectivity to strengthen the learning of the higher-order structure. And considering that the motif patterns of different samples are highly unbalanced, we propose a curriculum learning mechanism on the whole learning process to more focus on the samples with uncommon motif distributions. Extensive experiments on one public dataset and two industrial datasets all demonstrate the effectiveness of our proposed method.
Graph Neural Network with Two Uplift Estimators for Label-Scarcity Individual Uplift Modeling
Mar 11, 2024



Uplift modeling aims to measure the incremental effect, which we call uplift, of a strategy or action on the users from randomized experiments or observational data. Most existing uplift methods only use individual data, which are usually not informative enough to capture the unobserved and complex hidden factors regarding the uplift. Furthermore, uplift modeling scenario usually has scarce labeled data, especially for the treatment group, which also poses a great challenge for model training. Considering that the neighbors' features and the social relationships are very informative to characterize a user's uplift, we propose a graph neural network-based framework with two uplift estimators, called GNUM, to learn from the social graph for uplift estimation. Specifically, we design the first estimator based on a class-transformed target. The estimator is general for all types of outcomes, and is able to comprehensively model the treatment and control group data together to approach the uplift. When the outcome is discrete, we further design the other uplift estimator based on our defined partial labels, which is able to utilize more labeled data from both the treatment and control groups, to further alleviate the label scarcity problem. Comprehensive experiments on a public dataset and two industrial datasets show a superior performance of our proposed framework over state-of-the-art methods under various evaluation metrics. The proposed algorithms have been deployed online to serve real-world uplift estimation scenarios.
Adversarially Robust Neural Architecture Search for Graph Neural Networks
Apr 09, 2023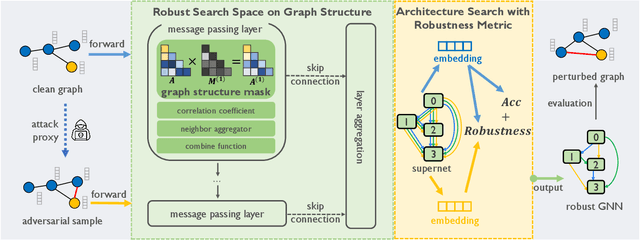

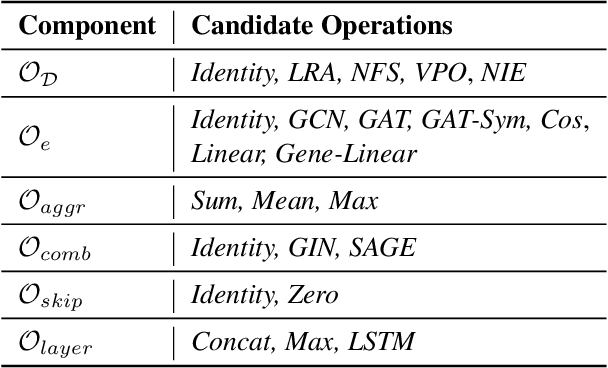
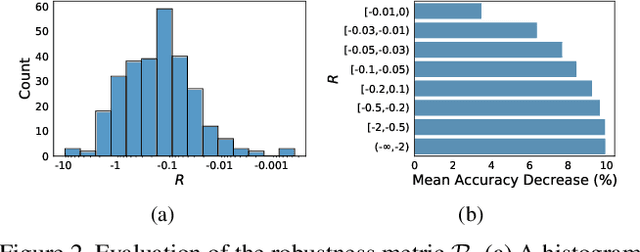
Graph Neural Networks (GNNs) obtain tremendous success in modeling relational data. Still, they are prone to adversarial attacks, which are massive threats to applying GNNs to risk-sensitive domains. Existing defensive methods neither guarantee performance facing new data/tasks or adversarial attacks nor provide insights to understand GNN robustness from an architectural perspective. Neural Architecture Search (NAS) has the potential to solve this problem by automating GNN architecture designs. Nevertheless, current graph NAS approaches lack robust design and are vulnerable to adversarial attacks. To tackle these challenges, we propose a novel Robust Neural Architecture search framework for GNNs (G-RNA). Specifically, we design a robust search space for the message-passing mechanism by adding graph structure mask operations into the search space, which comprises various defensive operation candidates and allows us to search for defensive GNNs. Furthermore, we define a robustness metric to guide the search procedure, which helps to filter robust architectures. In this way, G-RNA helps understand GNN robustness from an architectural perspective and effectively searches for optimal adversarial robust GNNs. Extensive experimental results on benchmark datasets show that G-RNA significantly outperforms manually designed robust GNNs and vanilla graph NAS baselines by 12.1% to 23.4% under adversarial attacks.
Revisiting Adversarial Attacks on Graph Neural Networks for Graph Classification
Aug 13, 2022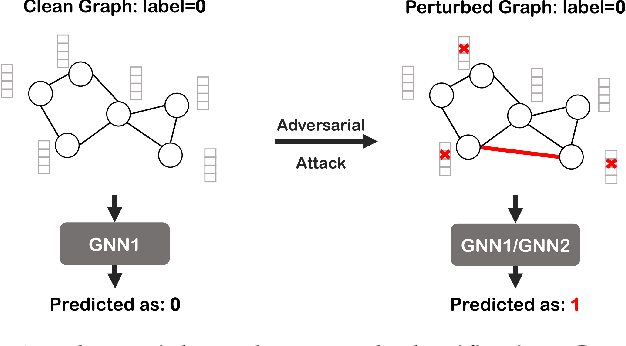
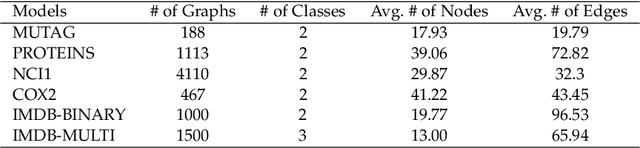
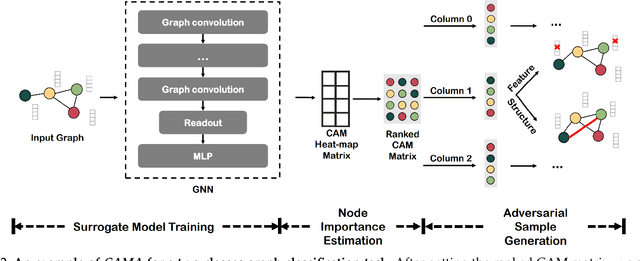
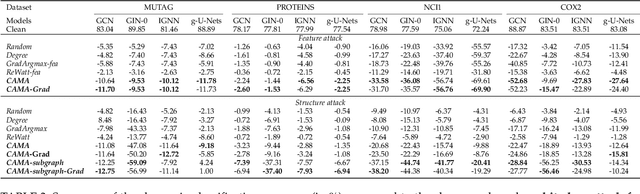
Graph neural networks (GNNs) have achieved tremendous success in the task of graph classification and diverse downstream real-world applications. Despite their success, existing approaches are either limited to structure attacks or restricted to local information. This calls for a more general attack framework on graph classification, which faces significant challenges due to the complexity of generating local-node-level adversarial examples using the global-graph-level information. To address this "global-to-local" problem, we present a general framework CAMA to generate adversarial examples by manipulating graph structure and node features in a hierarchical style. Specifically, we make use of Graph Class Activation Mapping and its variant to produce node-level importance corresponding to the graph classification task. Then through a heuristic design of algorithms, we can perform both feature and structure attacks under unnoticeable perturbation budgets with the help of both node-level and subgraph-level importance. Experiments towards attacking four state-of-the-art graph classification models on six real-world benchmarks verify the flexibility and effectiveness of our framework.
Conditional Attention Networks for Distilling Knowledge Graphs in Recommendation
Nov 03, 2021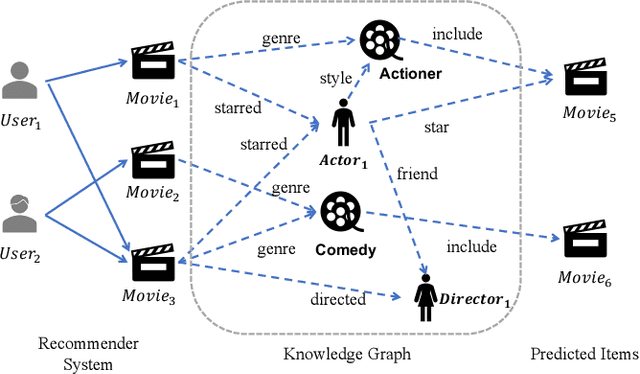
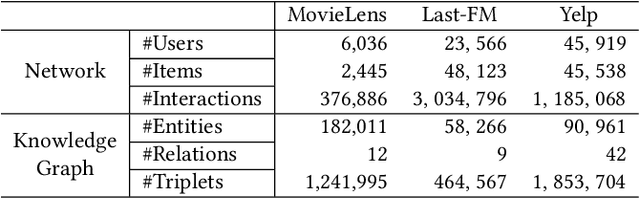
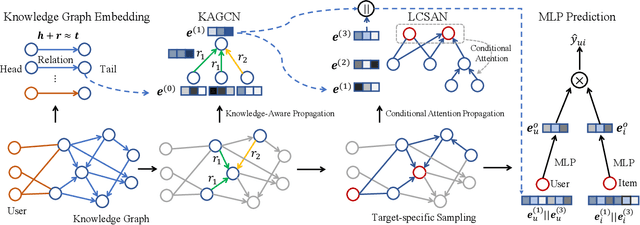
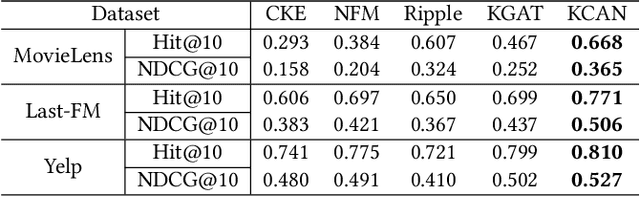
Knowledge graph is generally incorporated into recommender systems to improve overall performance. Due to the generalization and scale of the knowledge graph, most knowledge relationships are not helpful for a target user-item prediction. To exploit the knowledge graph to capture target-specific knowledge relationships in recommender systems, we need to distill the knowledge graph to reserve the useful information and refine the knowledge to capture the users' preferences. To address the issues, we propose Knowledge-aware Conditional Attention Networks (KCAN), which is an end-to-end model to incorporate knowledge graph into a recommender system. Specifically, we use a knowledge-aware attention propagation manner to obtain the node representation first, which captures the global semantic similarity on the user-item network and the knowledge graph. Then given a target, i.e., a user-item pair, we automatically distill the knowledge graph into the target-specific subgraph based on the knowledge-aware attention. Afterward, by applying a conditional attention aggregation on the subgraph, we refine the knowledge graph to obtain target-specific node representations. Therefore, we can gain both representability and personalization to achieve overall performance. Experimental results on real-world datasets demonstrate the effectiveness of our framework over the state-of-the-art algorithms.