 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Credit Limit Management in Consumer Loans Based on Causal Inference
Jul 10, 2020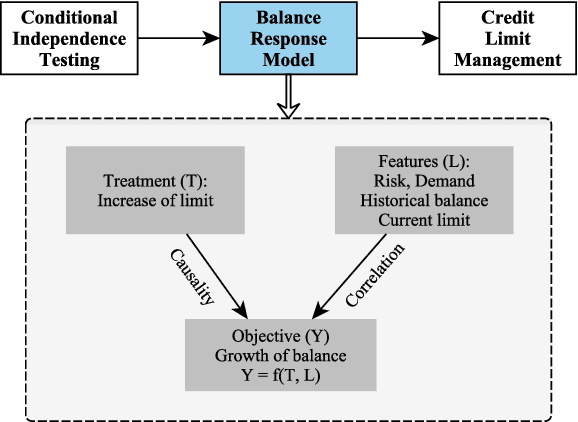
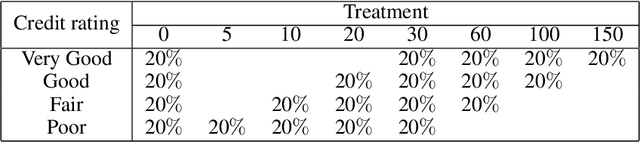

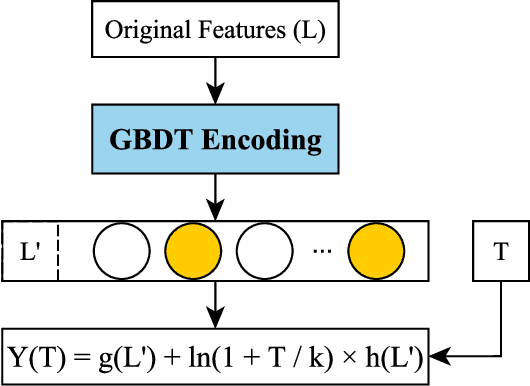
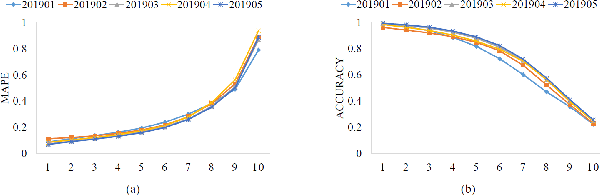
Nowadays consumer loan plays an important role in promoting the economic growth, and credit cards are the most popular consumer loan. One of the most essential parts in credit cards is the credit limit management. Traditionally, credit limits are adjusted based on limited heuristic strategies, which are developed by experienced professionals. In this paper, we present a data-driven approach to manage the credit limit intelligently. Firstly, a conditional independence testing is conducted to acquire the data for building models. Based on these testing data, a response model is then built to measure the heterogeneous treatment effect of increasing credit limits (i.e. treatments) for different customers, who are depicted by several control variables (i.e. features). In order to incorporate the diminishing marginal effect, a carefully selected log transformation is introduced to the treatment variable. Moreover, the model's capability can be further enhanced by applying a non-linear transformation on features via GBDT encoding. Finally, a well-designed metric is proposed to properly measure the performances of compared methods. The experimental results demonstrate the effectiveness of the proposed approach.
Large-scale Uncertainty Estimation and Its Application in Revenue Forecast of SMEs
May 02, 2020

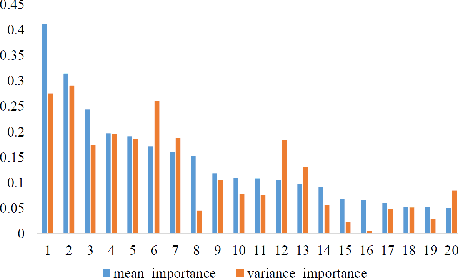
The economic and banking importance of the small and medium enterprise (SME) sector is well recognized in contemporary society. Business credit loans are very important for the operation of SMEs, and the revenue is a key indicator of credit limit management. Therefore, it is very beneficial to construct a reliable revenue forecasting model. If the uncertainty of an enterprise's revenue forecasting can be estimated, a more proper credit limit can be granted. Natural gradient boosting approach, which estimates the uncertainty of prediction by a multi-parameter boosting algorithm based on the natural gradient. However, its original implementation is not easy to scale into big data scenarios, and computationally expensive compared to state-of-the-art tree-based models (such as XGBoost). In this paper, we propose a Scalable Natural Gradient Boosting Machines that is simple to implement, readily parallelizable, interpretable and yields high-quality predictive uncertainty estimates. According to the characteristics of revenue distribution, we derive an uncertainty quantification function. We demonstrate that our method can distinguish between samples that are accurate and inaccurate on revenue forecasting of SMEs. What's more, interpretability can be naturally obtained from the model, satisfying the financial needs.
A Semi-supervised Graph Attentive Network for Financial Fraud Detection
Feb 28, 2020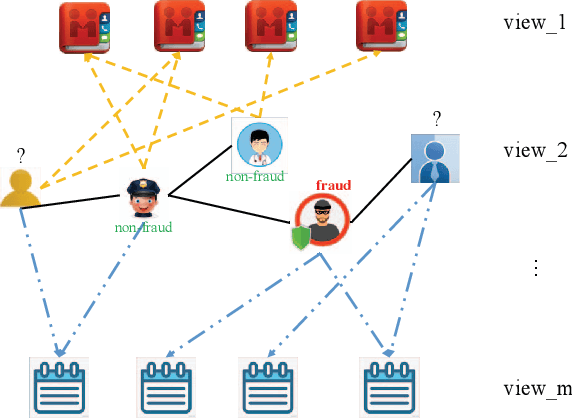
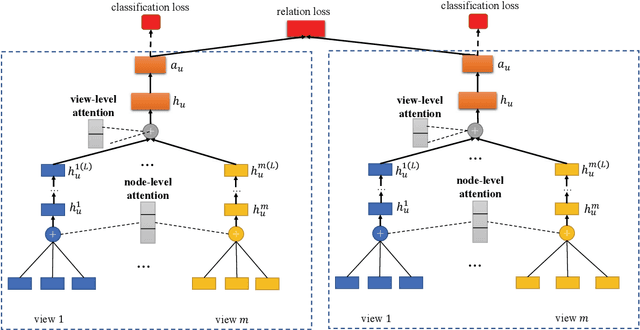

With the rapid growth of financial services, fraud detection has been a very important problem to guarantee a healthy environment for both users and providers. Conventional solutions for fraud detection mainly use some rule-based methods or distract some features manually to perform prediction. However, in financial services, users have rich interactions and they themselves always show multifaceted information. These data form a large multiview network, which is not fully exploited by conventional methods. Additionally, among the network, only very few of the users are labelled, which also poses a great challenge for only utilizing labeled data to achieve a satisfied performance on fraud detection. To address the problem, we expand the labeled data through their social relations to get the unlabeled data and propose a semi-supervised attentive graph neural network, namedSemiGNN to utilize the multi-view labeled and unlabeled data for fraud detection. Moreover, we propose a hierarchical attention mechanism to better correlate different neighbors and different views. Simultaneously, the attention mechanism can make the model interpretable and tell what are the important factors for the fraud and why the users are predicted as fraud. Experimentally, we conduct the prediction task on the users of Alipay, one of the largest third-party online and offline cashless payment platform serving more than 4 hundreds of million users in China. By utilizing the social relations and the user attributes, our method can achieve a better accuracy compared with the state-of-the-art methods on two tasks. Moreover, the interpretable results also give interesting intuitions regarding the tasks.