 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Credit Limit Management in Consumer Loans Based on Causal Inference
Jul 10, 2020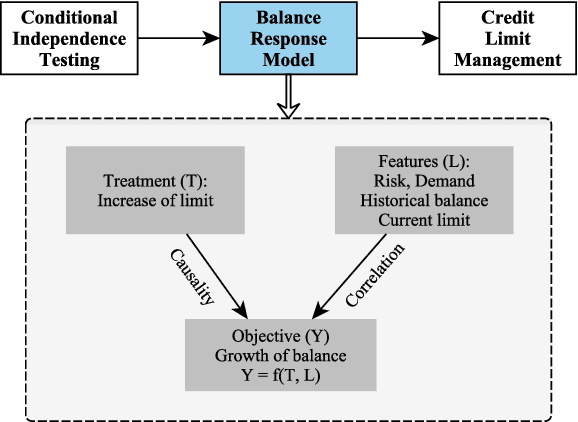
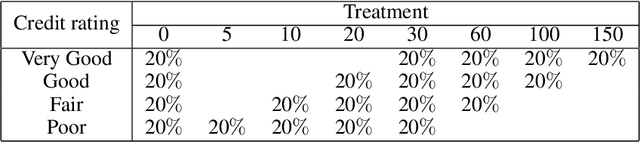

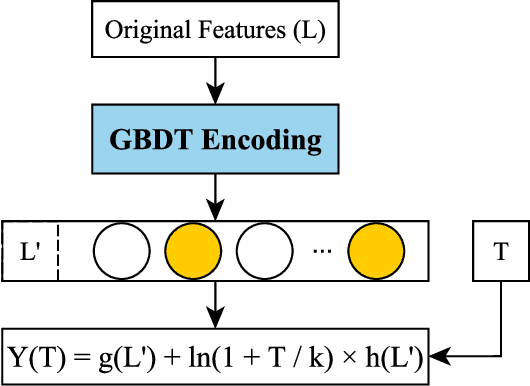
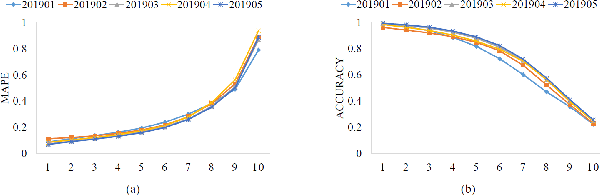
Nowadays consumer loan plays an important role in promoting the economic growth, and credit cards are the most popular consumer loan. One of the most essential parts in credit cards is the credit limit management. Traditionally, credit limits are adjusted based on limited heuristic strategies, which are developed by experienced professionals. In this paper, we present a data-driven approach to manage the credit limit intelligently. Firstly, a conditional independence testing is conducted to acquire the data for building models. Based on these testing data, a response model is then built to measure the heterogeneous treatment effect of increasing credit limits (i.e. treatments) for different customers, who are depicted by several control variables (i.e. features). In order to incorporate the diminishing marginal effect, a carefully selected log transformation is introduced to the treatment variable. Moreover, the model's capability can be further enhanced by applying a non-linear transformation on features via GBDT encoding. Finally, a well-designed metric is proposed to properly measure the performances of compared methods. The experimental results demonstrate the effectiveness of the proposed approach.
Large-scale Uncertainty Estimation and Its Application in Revenue Forecast of SMEs
May 02, 2020

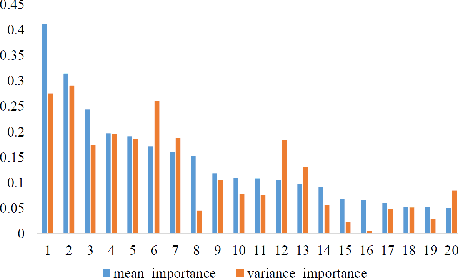
The economic and banking importance of the small and medium enterprise (SME) sector is well recognized in contemporary society. Business credit loans are very important for the operation of SMEs, and the revenue is a key indicator of credit limit management. Therefore, it is very beneficial to construct a reliable revenue forecasting model. If the uncertainty of an enterprise's revenue forecasting can be estimated, a more proper credit limit can be granted. Natural gradient boosting approach, which estimates the uncertainty of prediction by a multi-parameter boosting algorithm based on the natural gradient. However, its original implementation is not easy to scale into big data scenarios, and computationally expensive compared to state-of-the-art tree-based models (such as XGBoost). In this paper, we propose a Scalable Natural Gradient Boosting Machines that is simple to implement, readily parallelizable, interpretable and yields high-quality predictive uncertainty estimates. According to the characteristics of revenue distribution, we derive an uncertainty quantification function. We demonstrate that our method can distinguish between samples that are accurate and inaccurate on revenue forecasting of SMEs. What's more, interpretability can be naturally obtained from the model, satisfying the financial needs.
A Unified Framework for Marketing Budget Allocation
Feb 04, 2019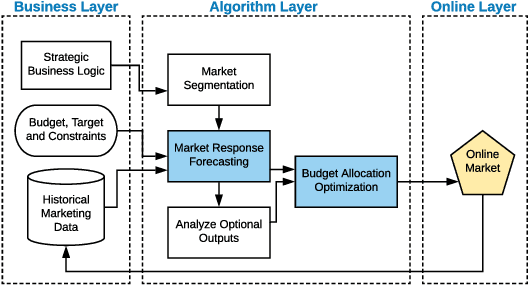
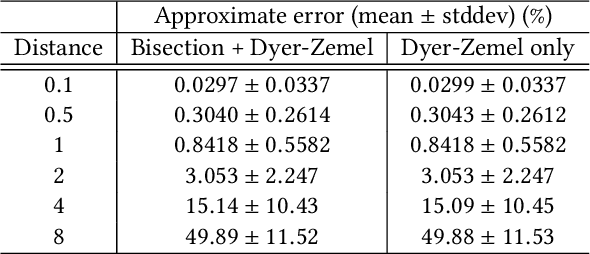
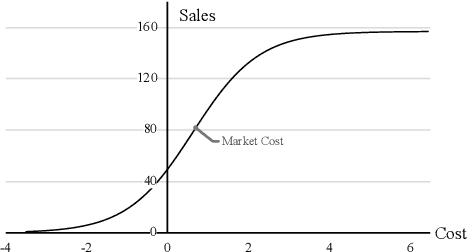
While marketing budget allocation has been studied for decades in traditional business, nowadays online business brings much more challenges due to the dynamic environment and complex decision-making process. In this paper, we present a novel unified framework for marketing budget allocation. By leveraging abundant data, the proposed data-driven approach can help us to overcome the challenges and make more informed decisions. In our approach, a semi-black-box model is built to forecast the dynamic market response and an efficient optimization method is proposed to solve the complex allocation task. First, the response in each market-segment is forecasted by exploring historical data through a semi-black-box model, where the capability of logit demand curve is enhanced by neural networks. The response model reveals relationship between sales and marketing cost. Based on the learned model, budget allocation is then formulated as an optimization problem, and we design efficient algorithms to solve it in both continuous and discrete settings. Several kinds of business constraints are supported in one unified optimization paradigm, including cost upper bound, profit lower bound, or ROI lower bound. The proposed framework is easy to implement and readily to handle large-scale problems. It has been successfully applied to many scenarios in Alibaba Group. The results of both offline experiments and online A/B testing demonstrate its effectiveness.
Learning and Transferring IDs Representation in E-commerce
May 22, 2018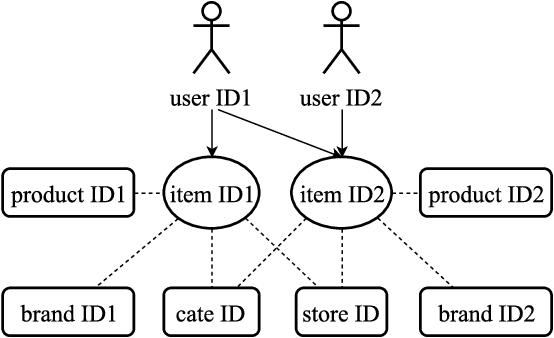


Many machine intelligence techniques are developed in E-commerce and one of the most essential components is the representation of IDs, including user ID, item ID, product ID, store ID, brand ID, category ID etc. The classical encoding based methods (like one-hot encoding) are inefficient in that it suffers sparsity problems due to its high dimension, and it cannot reflect the relationships among IDs, either homogeneous or heterogeneous ones. In this paper, we propose an embedding based framework to learn and transfer the representation of IDs. As the implicit feedbacks of users, a tremendous amount of item ID sequences can be easily collected from the interactive sessions. By jointly using these informative sequences and the structural connections among IDs, all types of IDs can be embedded into one low-dimensional semantic space. Subsequently, the learned representations are utilized and transferred in four scenarios: (i) measuring the similarity between items, (ii) transferring from seen items to unseen items, (iii) transferring across different domains, (iv) transferring across different tasks. We deploy and evaluate the proposed approach in Hema App and the results validate its effectiveness.
Adaptive Recurrent Neural Network via Persistent Memory
May 18, 2018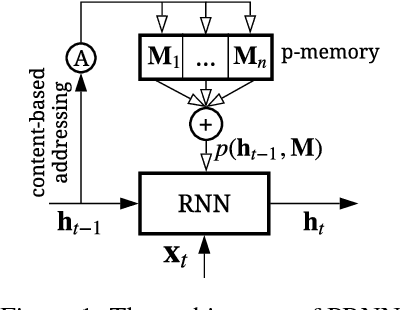

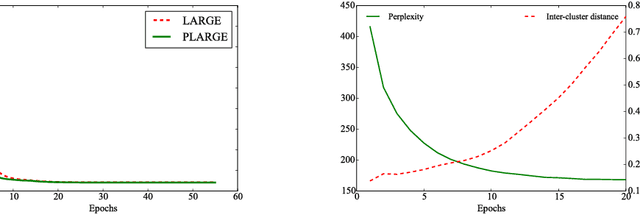
Although Recurrent Neural Network (RNN) has been a powerful tool for modeling sequential data, its performance is inadequate when processing sequences with multiple patterns. In this paper, we address this challenge by introducing a persistent memory and constructing an adaptive RNN. The persistent memory augmented RNN (termed as PRNN) captures the principle patterns in training sequences and stores them in an external memory. By leveraging the persistent memory, the proposed method can adaptively update states according to the similarities between encoded inputs and memory slots, leading to a stronger capacity in assimilating sequences with multiple patterns. Content-based addressing is suggested in memory accessing, and gradient descent is utilized for implicitly updating the memory. Our approach can be further extended by combining the prior knowledge of data. Experiments on several datasets demonstrate the effectiveness of our method.
Sales Forecast in E-commerce using Convolutional Neural Network
Aug 26, 2017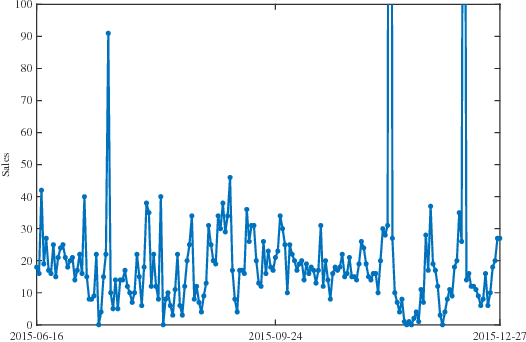
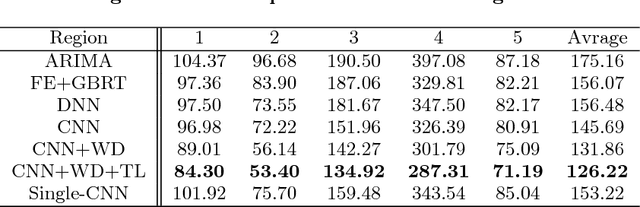

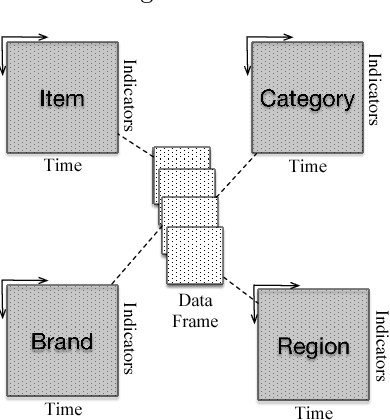
Sales forecast is an essential task in E-commerce and has a crucial impact on making informed business decisions. It can help us to manage the workforce, cash flow and resources such as optimizing the supply chain of manufacturers etc. Sales forecast is a challenging problem in that sales is affected by many factors including promotion activities, price changes, and user preferences etc. Traditional sales forecast techniques mainly rely on historical sales data to predict future sales and their accuracies are limited. Some more recent learning-based methods capture more information in the model to improve the forecast accuracy. However, these methods require case-by-case manual feature engineering for specific commercial scenarios, which is usually a difficult, time-consuming task and requires expert knowledge. To overcome the limitations of existing methods, we propose a novel approach in this paper to learn effective features automatically from the structured data using the Convolutional Neural Network (CNN). When fed with raw log data, our approach can automatically extract effective features from that and then forecast sales using those extracted features. We test our method on a large real-world dataset from CaiNiao.com and the experimental results validate the effectiveness of our method.
Navigation Objects Extraction for Better Content Structure Understanding
Aug 26, 2017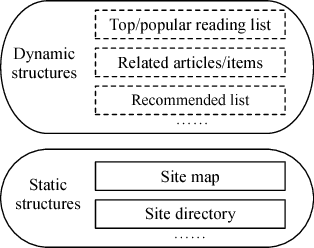
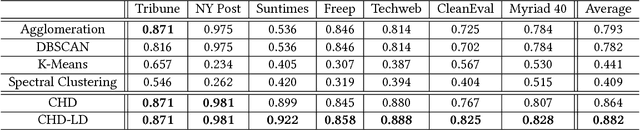
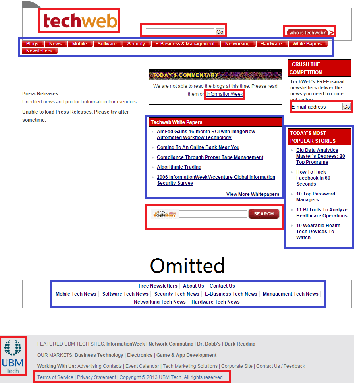
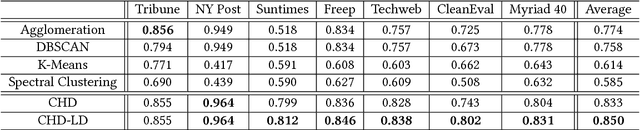
Existing works for extracting navigation objects from webpages focus on navigation menus, so as to reveal the information architecture of the site. However, web 2.0 sites such as social networks, e-commerce portals etc. are making the understanding of the content structure in a web site increasingly difficult. Dynamic and personalized elements such as top stories, recommended list in a webpage are vital to the understanding of the dynamic nature of web 2.0 sites. To better understand the content structure in web 2.0 sites, in this paper we propose a new extraction method for navigation objects in a webpage. Our method will extract not only the static navigation menus, but also the dynamic and personalized page-specific navigation lists. Since the navigation objects in a webpage naturally come in blocks, we first cluster hyperlinks into different blocks by exploiting spatial locations of hyperlinks, the hierarchical structure of the DOM-tree and the hyperlink density. Then we identify navigation objects from those blocks using the SVM classifier with novel features such as anchor text lengths etc. Experiments on real-world data sets with webpages from various domains and styles verified the effectiveness of our method.
Deep Style Match for Complementary Recommendation
Aug 26, 2017


Humans develop a common sense of style compatibility between items based on their attributes. We seek to automatically answer questions like "Does this shirt go well with that pair of jeans?" In order to answer these kinds of questions, we attempt to model human sense of style compatibility in this paper. The basic assumption of our approach is that most of the important attributes for a product in an online store are included in its title description. Therefore it is feasible to learn style compatibility from these descriptions. We design a Siamese Convolutional Neural Network architecture and feed it with title pairs of items, which are either compatible or incompatible. Those pairs will be mapped from the original space of symbolic words into some embedded style space. Our approach takes only words as the input with few preprocessing and there is no laborious and expensive feature engineering.