 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressively Stacking 2.0: A Multi-stage Layerwise Training Method for BERT Training Speedup
Nov 27, 2020
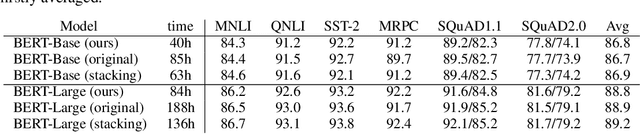
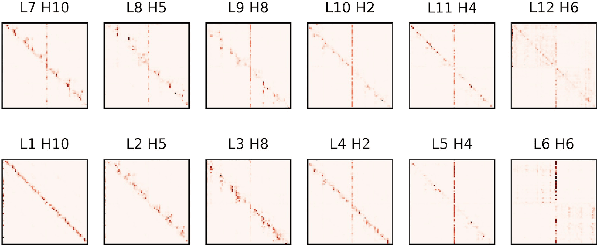
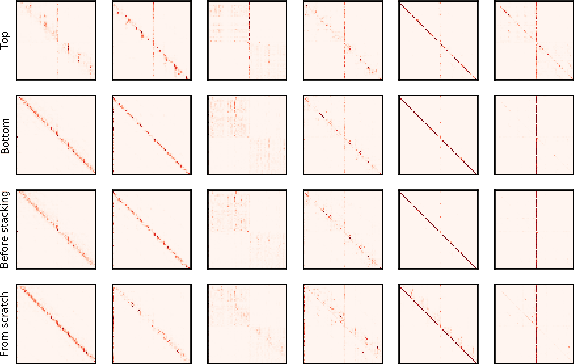
Pre-trained language models, such as BERT, have achieved significant accuracy gain in many natural language processing tasks. Despite its effectiveness, the huge number of parameters makes training a BERT model computationally very challenging. In this paper, we propose an efficient multi-stage layerwise training (MSLT) approach to reduce the training time of BERT. We decompose the whole training process into several stages. The training is started from a small model with only a few encoder layers and we gradually increase the depth of the model by adding new encoder layers. At each stage, we only train the top (near the output layer) few encoder layers which are newly added. The parameters of the other layers which have been trained in the previous stages will not be updated in the current stage. In BERT training, the backward computation is much more time-consuming than the forward computation, especially in the distributed training setting in which the backward computation time further includes the communication time for gradient synchronization. In the proposed training strategy, only top few layers participate in backward computation, while most layers only participate in forward computation. Hence both the computation and communication efficiencies are greatly improved. Experimental results show that the proposed method can achieve more than 110% training speedup without significant performance degradation.
CoRe: An Efficient Coarse-refined Training Framework for BERT
Nov 27, 2020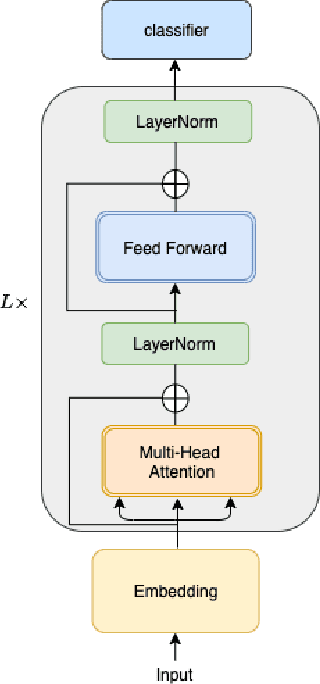
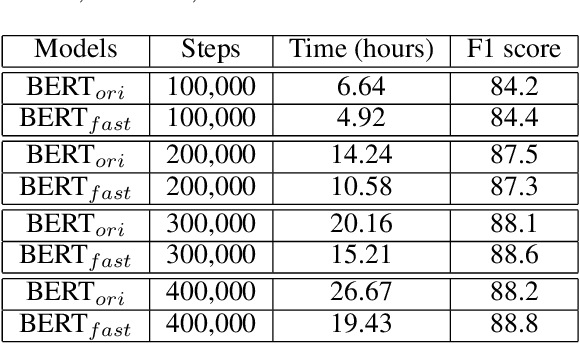
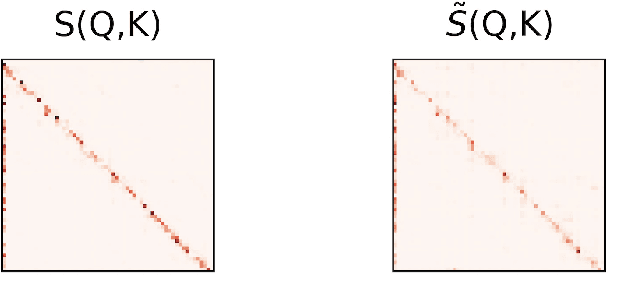
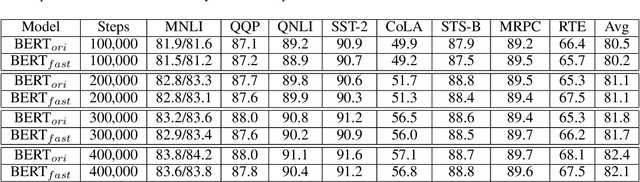
In recent years, BERT has made significant breakthroughs on many natural language processing tasks and attracted great attentions. Despite its accuracy gains, the BERT model generally involves a huge number of parameters and needs to be trained on massive datasets, so training such a model is computationally very challenging and time-consuming. Hence, training efficiency should be a critical issue. In this paper, we propose a novel coarse-refined training framework named CoRe to speed up the training of BERT. Specifically, we decompose the training process of BERT into two phases. In the first phase, by introducing fast attention mechanism and decomposing the large parameters in the feed-forward network sub-layer, we construct a relaxed BERT model which has much less parameters and much lower model complexity than the original BERT, so the relaxed model can be quickly trained. In the second phase, we transform the trained relaxed BERT model into the original BERT and further retrain the model. Thanks to the desired initialization provided by the relaxed model, the retraining phase requires much less training steps, compared with training an original BERT model from scratch with a random initialization. Experimental results show that the proposed CoRe framework can greatly reduce the training time without reducing the performance.
Learning and Transferring IDs Representation in E-commerce
May 22, 2018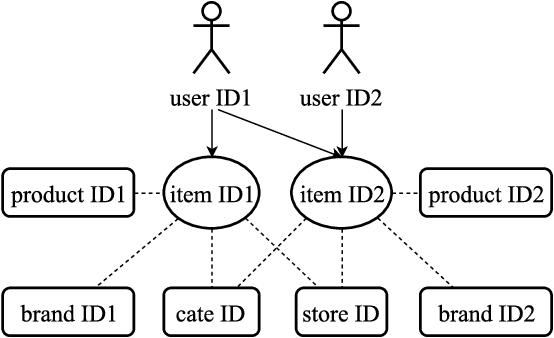


Many machine intelligence techniques are developed in E-commerce and one of the most essential components is the representation of IDs, including user ID, item ID, product ID, store ID, brand ID, category ID etc. The classical encoding based methods (like one-hot encoding) are inefficient in that it suffers sparsity problems due to its high dimension, and it cannot reflect the relationships among IDs, either homogeneous or heterogeneous ones. In this paper, we propose an embedding based framework to learn and transfer the representation of IDs. As the implicit feedbacks of users, a tremendous amount of item ID sequences can be easily collected from the interactive sessions. By jointly using these informative sequences and the structural connections among IDs, all types of IDs can be embedded into one low-dimensional semantic space. Subsequently, the learned representations are utilized and transferred in four scenarios: (i) measuring the similarity between items, (ii) transferring from seen items to unseen items, (iii) transferring across different domains, (iv) transferring across different tasks. We deploy and evaluate the proposed approach in Hema App and the results validate its effectiveness.
Adaptive Recurrent Neural Network via Persistent Memory
May 18, 2018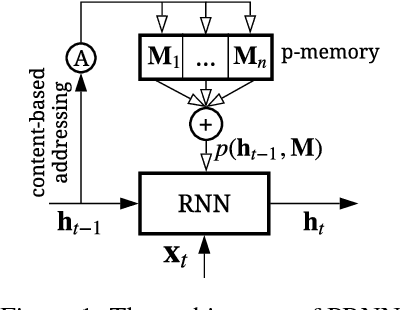

Although Recurrent Neural Network (RNN) has been a powerful tool for modeling sequential data, its performance is inadequate when processing sequences with multiple patterns. In this paper, we address this challenge by introducing a persistent memory and constructing an adaptive RNN. The persistent memory augmented RNN (termed as PRNN) captures the principle patterns in training sequences and stores them in an external memory. By leveraging the persistent memory, the proposed method can adaptively update states according to the similarities between encoded inputs and memory slots, leading to a stronger capacity in assimilating sequences with multiple patterns. Content-based addressing is suggested in memory accessing, and gradient descent is utilized for implicitly updating the memory. Our approach can be further extended by combining the prior knowledge of data. Experiments on several datasets demonstrate the effectiveness of our method.