 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIM -- General User and Item Embedding with Mixture of Representation in E-commerce
Jul 02, 2022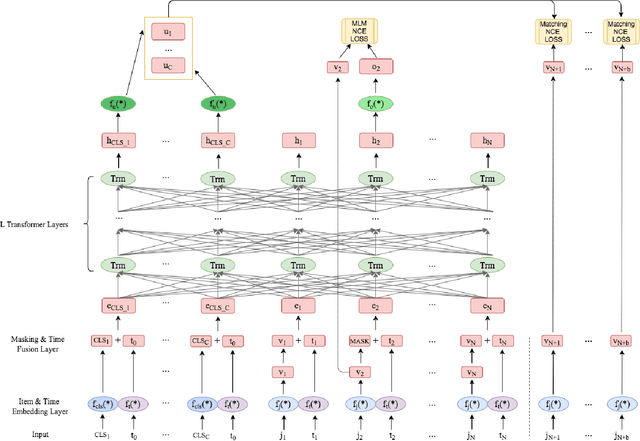

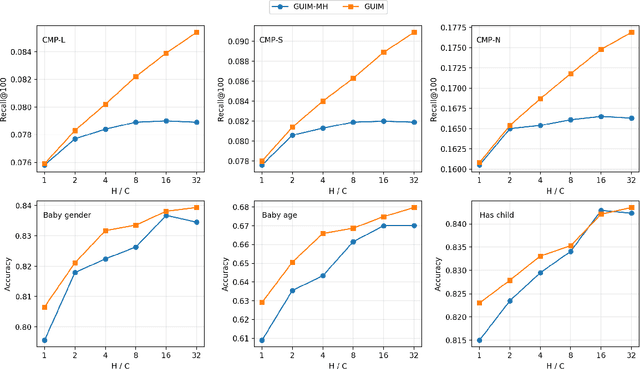
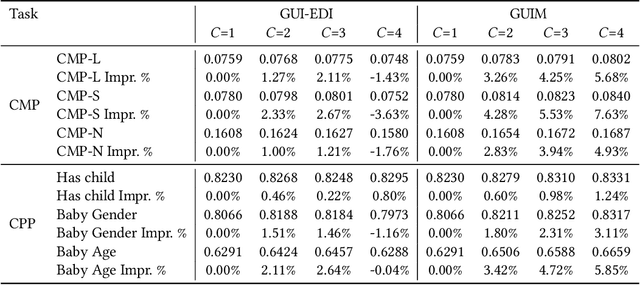
Our goal is to build general representation (embedding) for each user and each product item across Alibaba's businesses, including Taobao and Tmall which are among the world's biggest e-commerce websites. The representation of users and items has been playing a critical role in various downstream applications, including recommendation system, search, marketing, demand forecasting and so on. Inspired from the BERT model in natural language processing (NLP) domain, we propose a GUIM (General User Item embedding with Mixture of representation) model to achieve the goal with massive, structured, multi-modal data including the interactions among hundreds of millions of users and items. We utilize mixture of representation (MoR) as a novel representation form to model the diverse interests of each user. In addition, we use the InfoNCE from contrastive learning to avoid intractable computational costs due to the numerous size of item (token) vocabulary. Finally, we propose a set of representative downstream tasks to serve as a standard benchmark to evaluate the quality of the learned user and/or item embeddings, analogous to the GLUE benchmark in NLP domain. Our experimental results in these downstream tasks clearly show the comparative value of embeddings learned from our GUIM model.
Improving Contrastive Learning of Sentence Embeddings with Case-Augmented Positives and Retrieved Negatives
Jun 06, 2022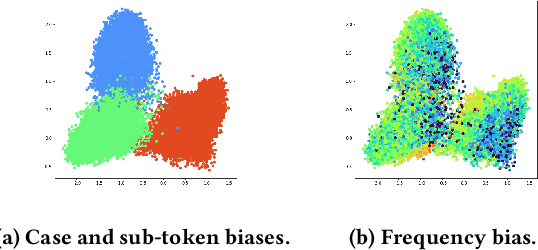

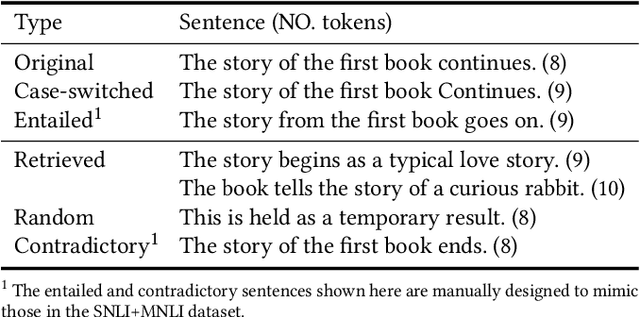
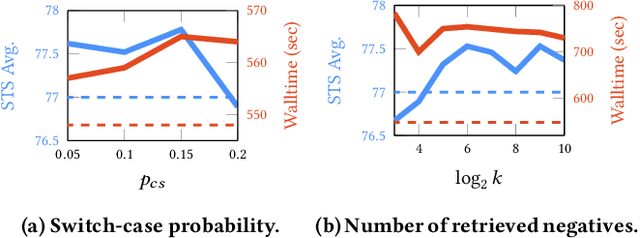
Following SimCSE, contrastive learning based methods have achieved the state-of-the-art (SOTA) performance in learning sentence embeddings. However, the unsupervised contrastive learning methods still lag far behind the supervised counterparts. We attribute this to the quality of positive and negative samples, and aim to improve both. Specifically, for positive samples, we propose switch-case augmentation to flip the case of the first letter of randomly selected words in a sentence. This is to counteract the intrinsic bias of pre-trained token embeddings to frequency, word cases and subwords. For negative samples, we sample hard negatives from the whole dataset based on a pre-trained language model. Combining the above two methods with SimCSE, our proposed Contrastive learning with Augmented and Retrieved Data for Sentence embedding (CARDS) method significantly surpasses the current SOTA on STS benchmarks in the unsupervised setting.
SAS: Self-Augmented Strategy for Language Model Pre-training
Jun 14, 2021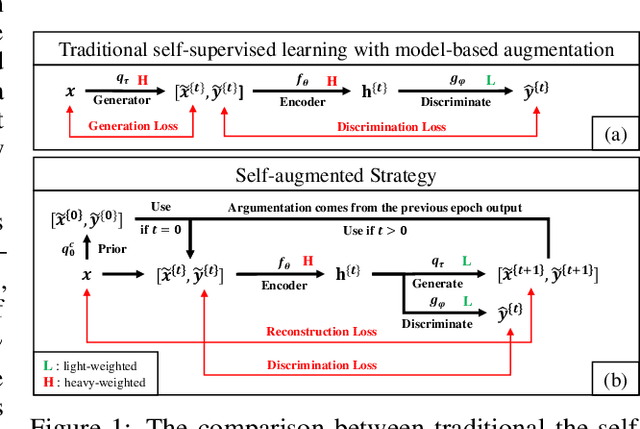
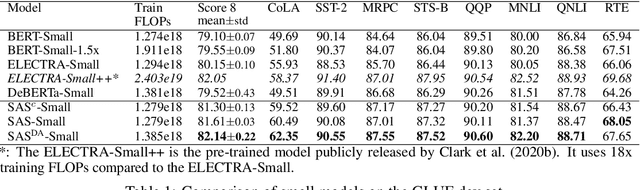
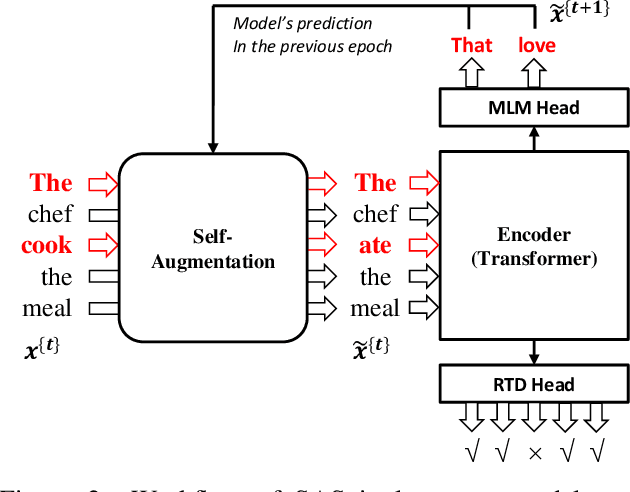

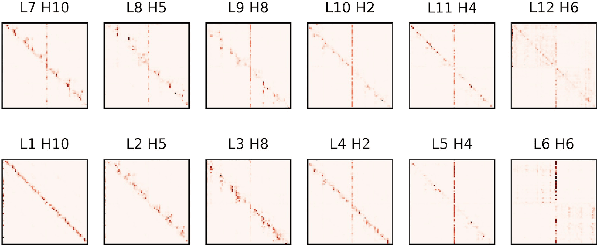
The core of a self-supervised learning method for pre-training language models includes the design of appropriate data augmentation and corresponding pre-training task(s). Most data augmentations in language model pre-training are context-independent. The seminal contextualized augmentation recently proposed by the ELECTRA requires a separate generator, which leads to extra computation cost as well as the challenge in adjusting the capability of its generator relative to that of the other model component(s). We propose a self-augmented strategy (SAS) that uses a single forward pass through the model to augment the input data for model training in the next epoch. Essentially our strategy eliminates a separate generator network and uses only one network to generate the data augmentation and undertake two pre-training tasks (the MLM task and the RTD task) jointly, which naturally avoids the challenge in adjusting the generator's capability as well as reduces the computation cost. Additionally, our SAS is a general strategy such that it can seamlessly incorporate many new techniques emerging recently or in the future, such as the disentangled attention mechanism recently proposed by the DeBERTa model. Our experiments show that our SAS is able to outperform the ELECTRA and other state-of-the-art models in the GLUE tasks with the same or less computation cost.
Progressively Stacking 2.0: A Multi-stage Layerwise Training Method for BERT Training Speedup
Nov 27, 2020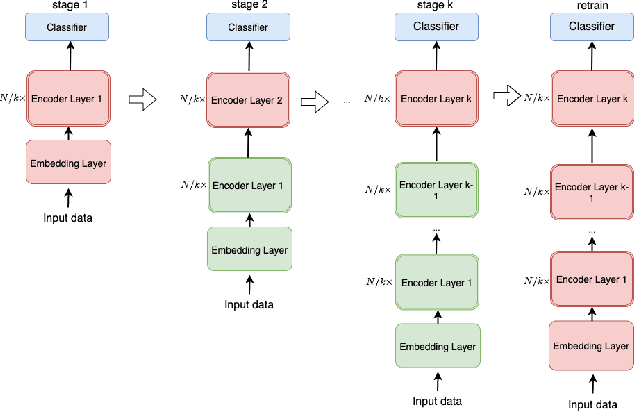
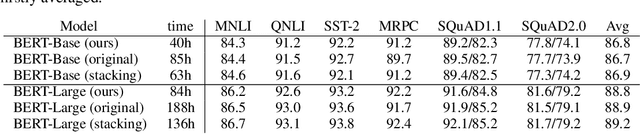
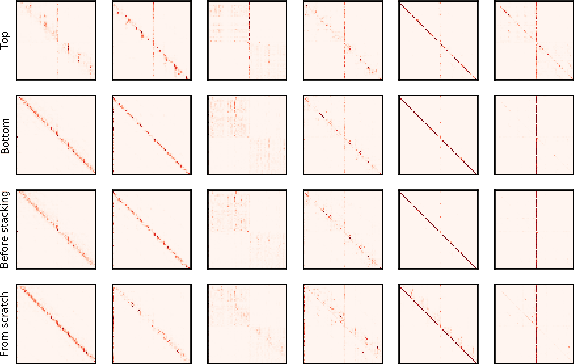
Pre-trained language models, such as BERT, have achieved significant accuracy gain in many natural language processing tasks. Despite its effectiveness, the huge number of parameters makes training a BERT model computationally very challenging. In this paper, we propose an efficient multi-stage layerwise training (MSLT) approach to reduce the training time of BERT. We decompose the whole training process into several stages. The training is started from a small model with only a few encoder layers and we gradually increase the depth of the model by adding new encoder layers. At each stage, we only train the top (near the output layer) few encoder layers which are newly added. The parameters of the other layers which have been trained in the previous stages will not be updated in the current stage. In BERT training, the backward computation is much more time-consuming than the forward computation, especially in the distributed training setting in which the backward computation time further includes the communication time for gradient synchronization. In the proposed training strategy, only top few layers participate in backward computation, while most layers only participate in forward computation. Hence both the computation and communication efficiencies are greatly improved. Experimental results show that the proposed method can achieve more than 110% training speedup without significant performance degradation.
CoRe: An Efficient Coarse-refined Training Framework for BERT
Nov 27, 2020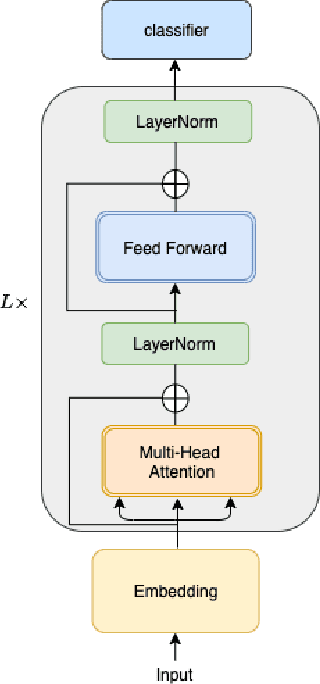
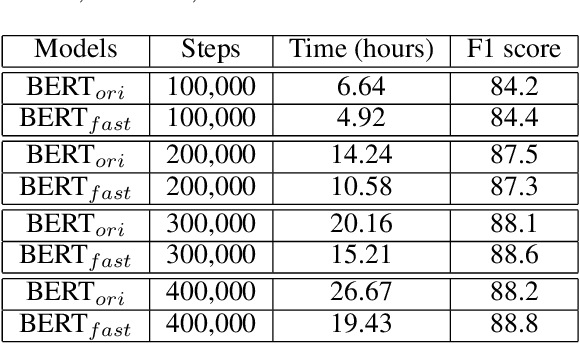
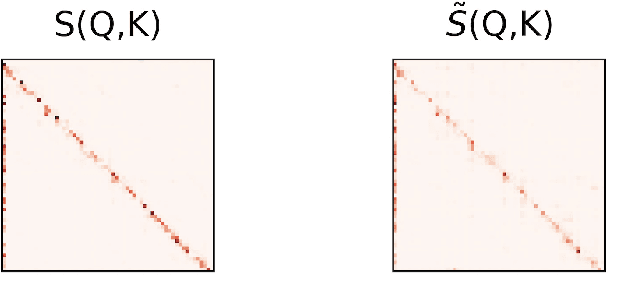
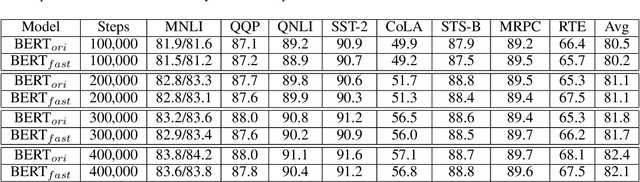
In recent years, BERT has made significant breakthroughs on many natural language processing tasks and attracted great attentions. Despite its accuracy gains, the BERT model generally involves a huge number of parameters and needs to be trained on massive datasets, so training such a model is computationally very challenging and time-consuming. Hence, training efficiency should be a critical issue. In this paper, we propose a novel coarse-refined training framework named CoRe to speed up the training of BERT. Specifically, we decompose the training process of BERT into two phases. In the first phase, by introducing fast attention mechanism and decomposing the large parameters in the feed-forward network sub-layer, we construct a relaxed BERT model which has much less parameters and much lower model complexity than the original BERT, so the relaxed model can be quickly trained. In the second phase, we transform the trained relaxed BERT model into the original BERT and further retrain the model. Thanks to the desired initialization provided by the relaxed model, the retraining phase requires much less training steps, compared with training an original BERT model from scratch with a random initialization. Experimental results show that the proposed CoRe framework can greatly reduce the training time without reducing the performance.