 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIM -- General User and Item Embedding with Mixture of Representation in E-commerce
Paper and Code
Jul 02, 2022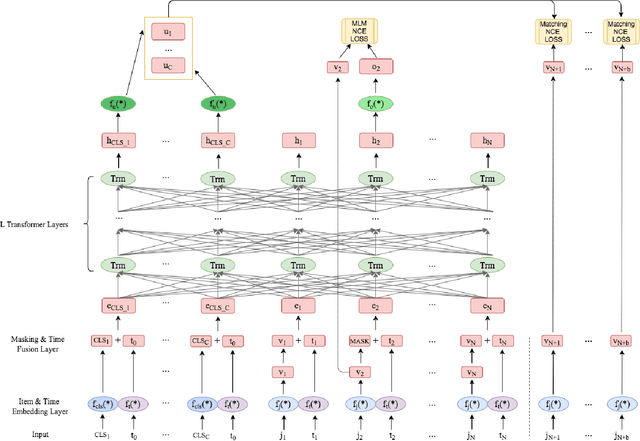

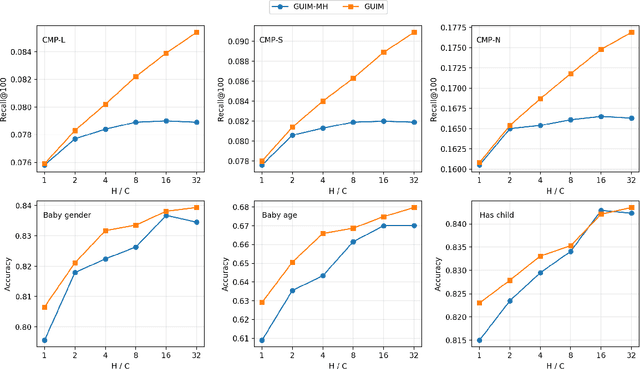
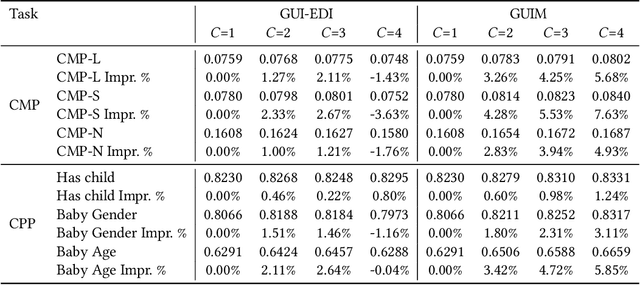
Our goal is to build general representation (embedding) for each user and each product item across Alibaba's businesses, including Taobao and Tmall which are among the world's biggest e-commerce websites. The representation of users and items has been playing a critical role in various downstream applications, including recommendation system, search, marketing, demand forecasting and so on. Inspired from the BERT model in natural language processing (NLP) domain, we propose a GUIM (General User Item embedding with Mixture of representation) model to achieve the goal with massive, structured, multi-modal data including the interactions among hundreds of millions of users and items. We utilize mixture of representation (MoR) as a novel representation form to model the diverse interests of each user. In addition, we use the InfoNCE from contrastive learning to avoid intractable computational costs due to the numerous size of item (token) vocabulary. Finally, we propose a set of representative downstream tasks to serve as a standard benchmark to evaluate the quality of the learned user and/or item embeddings, analogous to the GLUE benchmark in NLP domain. Our experimental results in these downstream tasks clearly show the comparative value of embeddings learned from our GUIM model.