 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounded-Compute Multimodal Regression for Product-Rating Prediction
May 26, 2026Vision-language models (VLMs) are increasingly attractive for multimodal quality assessment, but their default reliance on autoregressive text generation and dynamic visual processing is poorly matched to scalar regression under strict latency budgets. We present a bounded-compute adaptation of SmolVLM2-256M-Video-Instruct for product-rating prediction in the LoViF 2026 Efficient VLM challenge. Motivated by recent multimodal engagement-prediction results showing that feature-based regression can outperform token-based score generation, we replace the language-modeling head with a lightweight two-layer MLP fed by pooled decoder states, and we enforce deterministic inputs through fixed 384x384 images and truncated metadata. Across controlled ablations, static global image processing slightly outperforms dynamic tiling, and scaling from 100K to 16M training examples substantially improves validation correlation. Under the official held-out evaluation, our 228M-parameter model achieves 0.39 PLCC and 0.40 CES, providing a strong and reproducible baseline for resource-constrained multimodal regression.
GUIM -- General User and Item Embedding with Mixture of Representation in E-commerce
Jul 02, 2022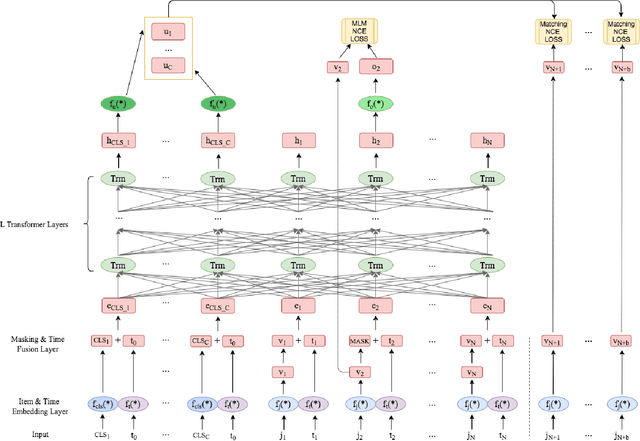

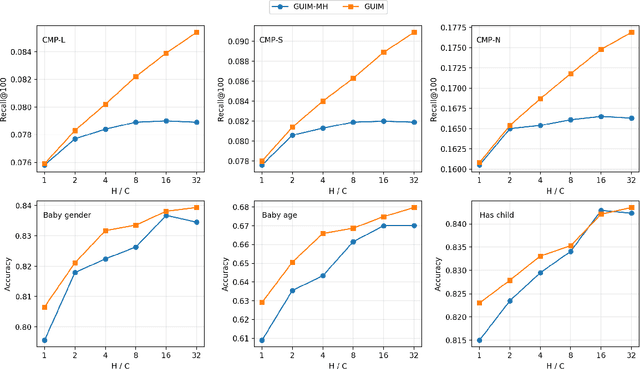
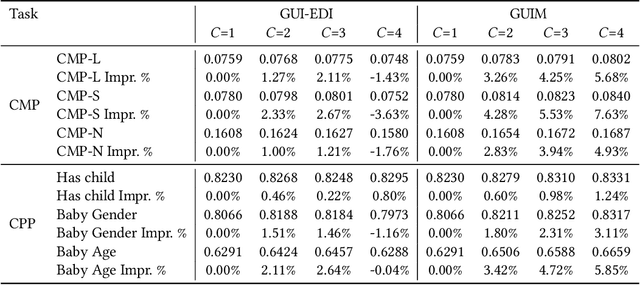
Our goal is to build general representation (embedding) for each user and each product item across Alibaba's businesses, including Taobao and Tmall which are among the world's biggest e-commerce websites. The representation of users and items has been playing a critical role in various downstream applications, including recommendation system, search, marketing, demand forecasting and so on. Inspired from the BERT model in natural language processing (NLP) domain, we propose a GUIM (General User Item embedding with Mixture of representation) model to achieve the goal with massive, structured, multi-modal data including the interactions among hundreds of millions of users and items. We utilize mixture of representation (MoR) as a novel representation form to model the diverse interests of each user. In addition, we use the InfoNCE from contrastive learning to avoid intractable computational costs due to the numerous size of item (token) vocabulary. Finally, we propose a set of representative downstream tasks to serve as a standard benchmark to evaluate the quality of the learned user and/or item embeddings, analogous to the GLUE benchmark in NLP domain. Our experimental results in these downstream tasks clearly show the comparative value of embeddings learned from our GUIM model.
SAS: Self-Augmented Strategy for Language Model Pre-training
Jun 14, 2021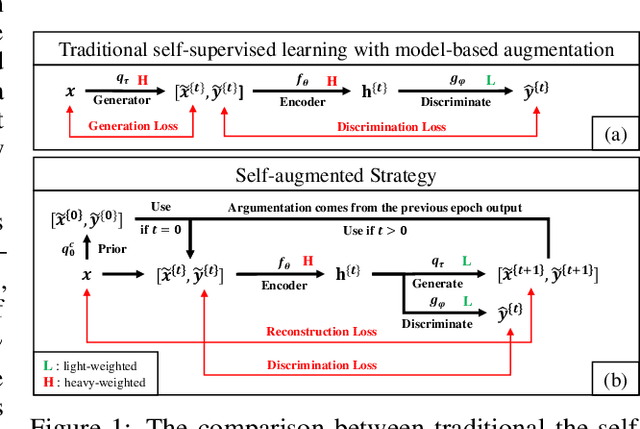
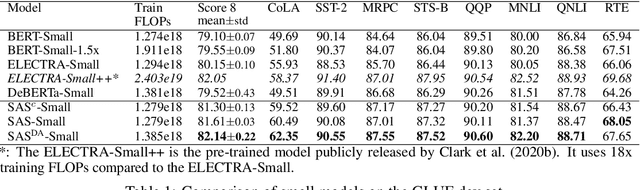
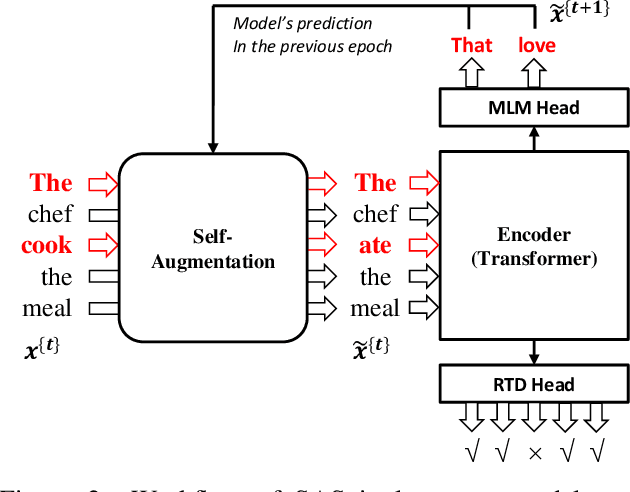

The core of a self-supervised learning method for pre-training language models includes the design of appropriate data augmentation and corresponding pre-training task(s). Most data augmentations in language model pre-training are context-independent. The seminal contextualized augmentation recently proposed by the ELECTRA requires a separate generator, which leads to extra computation cost as well as the challenge in adjusting the capability of its generator relative to that of the other model component(s). We propose a self-augmented strategy (SAS) that uses a single forward pass through the model to augment the input data for model training in the next epoch. Essentially our strategy eliminates a separate generator network and uses only one network to generate the data augmentation and undertake two pre-training tasks (the MLM task and the RTD task) jointly, which naturally avoids the challenge in adjusting the generator's capability as well as reduces the computation cost. Additionally, our SAS is a general strategy such that it can seamlessly incorporate many new techniques emerging recently or in the future, such as the disentangled attention mechanism recently proposed by the DeBERTa model. Our experiments show that our SAS is able to outperform the ELECTRA and other state-of-the-art models in the GLUE tasks with the same or less computation cost.
Progressively Stacking 2.0: A Multi-stage Layerwise Training Method for BERT Training Speedup
Nov 27, 2020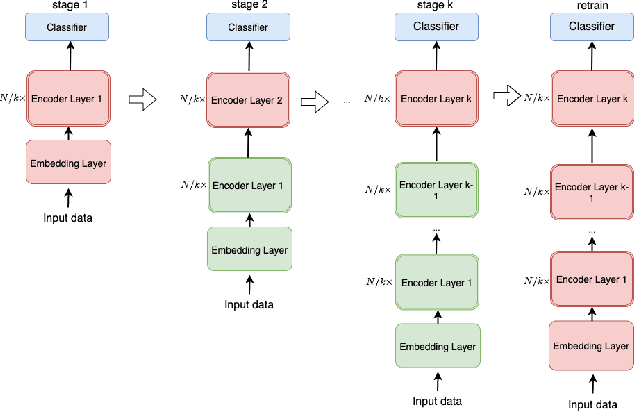
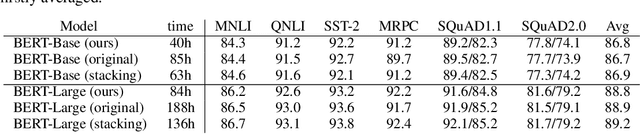
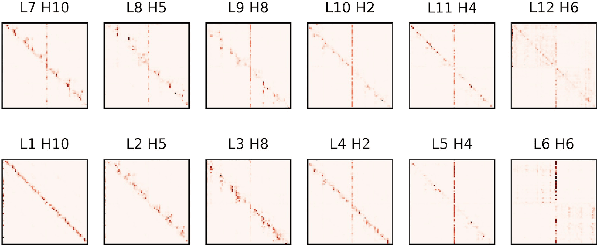
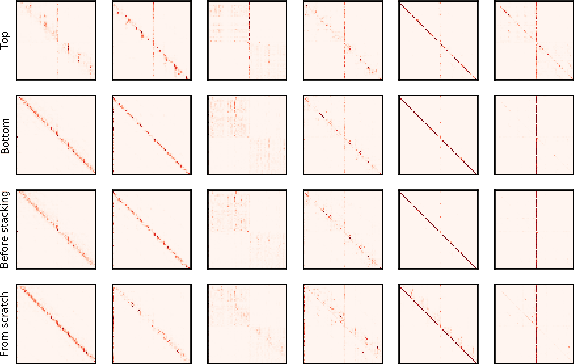
Pre-trained language models, such as BERT, have achieved significant accuracy gain in many natural language processing tasks. Despite its effectiveness, the huge number of parameters makes training a BERT model computationally very challenging. In this paper, we propose an efficient multi-stage layerwise training (MSLT) approach to reduce the training time of BERT. We decompose the whole training process into several stages. The training is started from a small model with only a few encoder layers and we gradually increase the depth of the model by adding new encoder layers. At each stage, we only train the top (near the output layer) few encoder layers which are newly added. The parameters of the other layers which have been trained in the previous stages will not be updated in the current stage. In BERT training, the backward computation is much more time-consuming than the forward computation, especially in the distributed training setting in which the backward computation time further includes the communication time for gradient synchronization. In the proposed training strategy, only top few layers participate in backward computation, while most layers only participate in forward computation. Hence both the computation and communication efficiencies are greatly improved. Experimental results show that the proposed method can achieve more than 110% training speedup without significant performance degradation.
Structure Learning in Bayesian Networks of Moderate Size by Efficient Sampling
Jan 19, 2015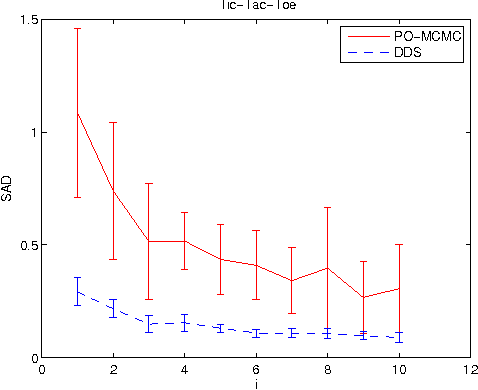
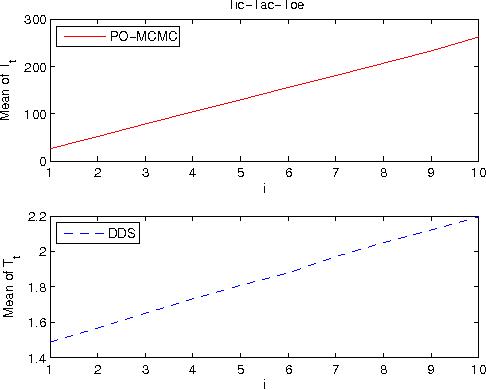
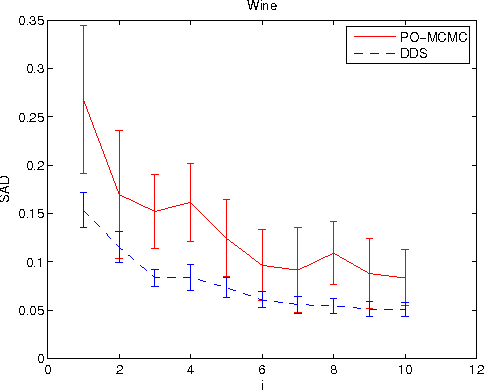
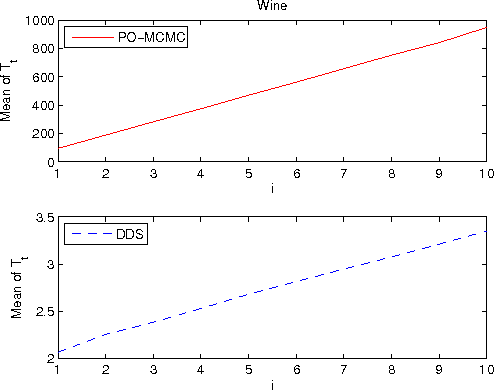
We study the Bayesian model averaging approach to learning Bayesian network structures (DAGs) from data. We develop new algorithms including the first algorithm that is able to efficiently sample DAGs according to the exact structure posterior. The DAG samples can then be used to construct estimators for the posterior of any feature. We theoretically prove good properties of our estimators and empirically show that our estimators considerably outperform the estimators from the previous state-of-the-art methods.
Computing Posterior Probabilities of Structural Features in Bayesian Networks
May 09, 2012
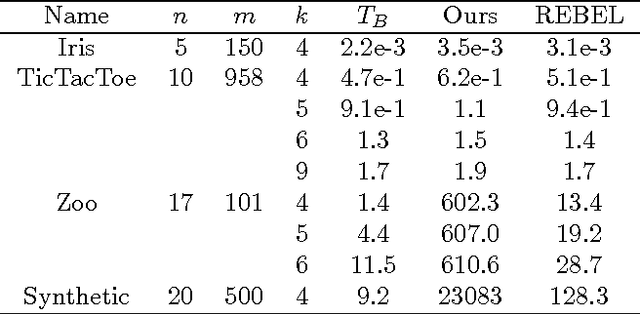


We study the problem of learning Bayesian network structures from data. Koivisto and Sood (2004) and Koivisto (2006) presented algorithms that can compute the exact marginal posterior probability of a subnetwork, e.g., a single edge, in O(n2n) time and the posterior probabilities for all n(n-1) potential edges in O(n2n) total time, assuming that the number of parents per node or the indegree is bounded by a constant. One main drawback of their algorithms is the requirement of a special structure prior that is non uniform and does not respect Markov equivalence. In this paper, we develop an algorithm that can compute the exact posterior probability of a subnetwork in O(3n) time and the posterior probabilities for all n(n-1) potential edges in O(n3n) total time. Our algorithm also assumes a bounded indegree but allows general structure priors. We demonstrate the applicability of the algorithm on several data sets with up to 20 variables.
Bayesian Model Averaging Using the k-best Bayesian Network Structures
Mar 15, 2012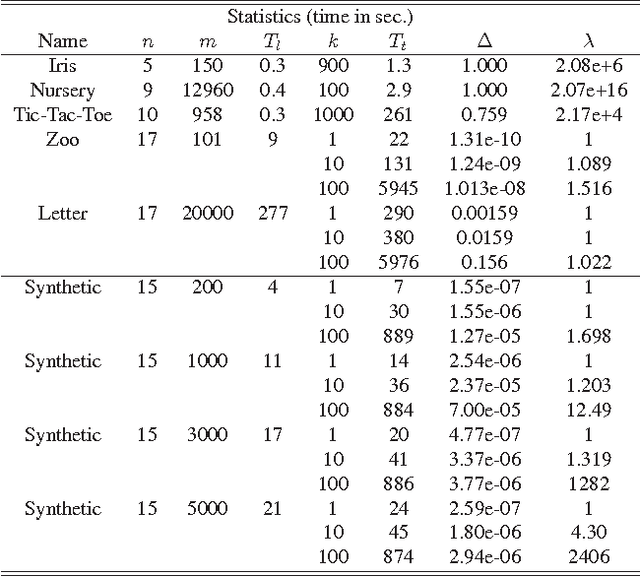
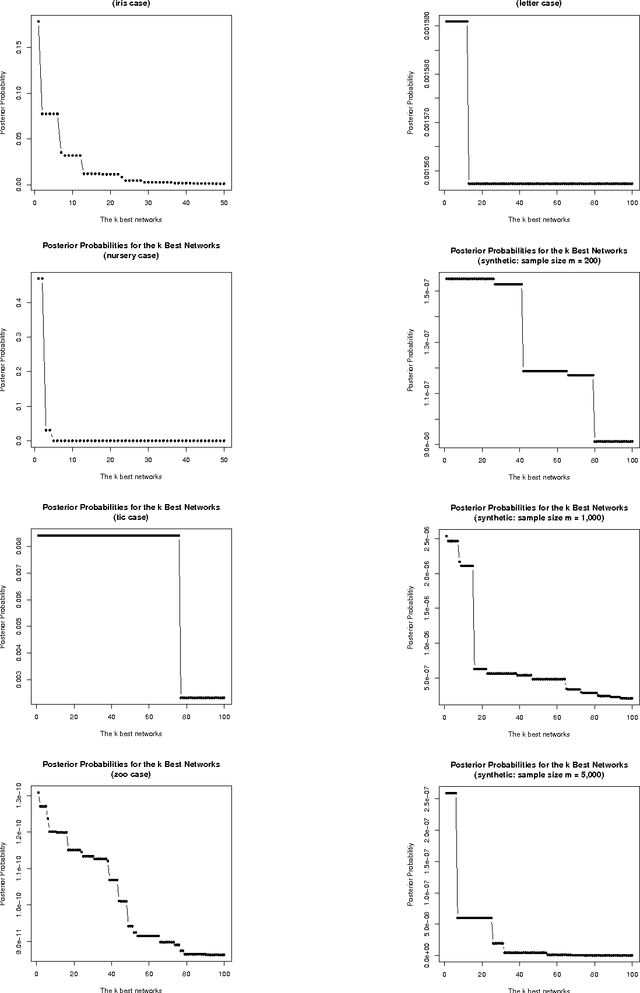
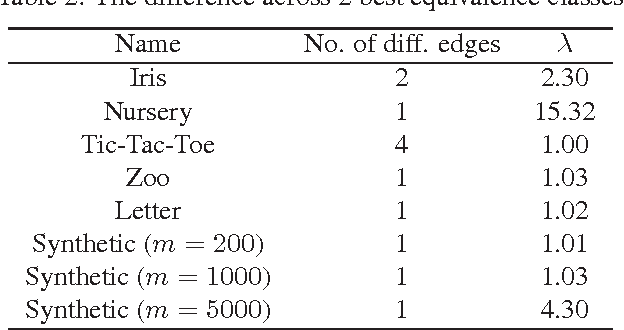
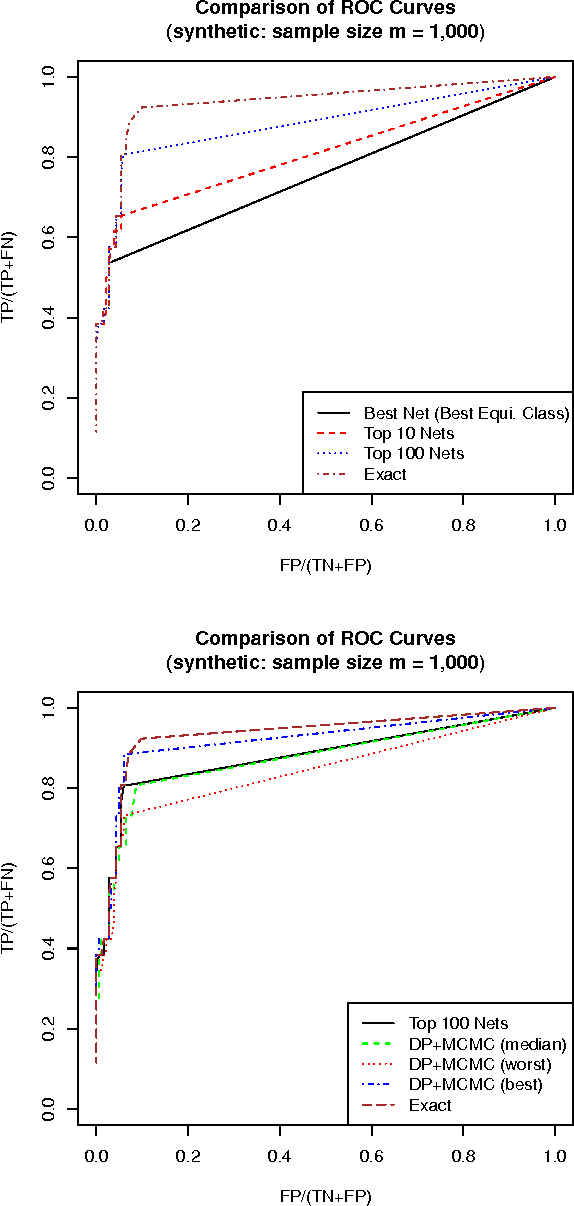
We study the problem of learning Bayesian network structures from data. We develop an algorithm for finding the k-best Bayesian network structures. We propose to compute the posterior probabilities of hypotheses of interest by Bayesian model averaging over the k-best Bayesian networks. We present empirical results on structural discovery over several real and synthetic data sets and show that the method outperforms the model selection method and the state of-the-art MCMC methods.