 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePotential Outcome Rankings for Counterfactual Decision Making
Nov 13, 2025Counterfactual decision-making in the face of uncertainty involves selecting the optimal action from several alternatives using causal reasoning. Decision-makers often rank expected potential outcomes (or their corresponding utility and desirability) to compare the preferences of candidate actions. In this paper, we study new counterfactual decision-making rules by introducing two new metrics: the probabilities of potential outcome ranking (PoR) and the probability of achieving the best potential outcome (PoB). PoR reveals the most probable ranking of potential outcomes for an individual, and PoB indicates the action most likely to yield the top-ranked outcome for an individual. We then establish identification theorems and derive bounds for these metrics, and present estimation methods. Finally, we perform numerical experiments to illustrate the finite-sample properties of the estimators and demonstrate their application to a real-world dataset.
Self-Supervised Multi-Part Articulated Objects Modeling via Deformable Gaussian Splatting and Progressive Primitive Segmentation
Jun 11, 2025Articulated objects are ubiquitous in everyday life, and accurate 3D representations of their geometry and motion are critical for numerous applications. However, in the absence of human annotation, existing approaches still struggle to build a unified representation for objects that contain multiple movable parts. We introduce DeGSS, a unified framework that encodes articulated objects as deformable 3D Gaussian fields, embedding geometry, appearance, and motion in one compact representation. Each interaction state is modeled as a smooth deformation of a shared field, and the resulting deformation trajectories guide a progressive coarse-to-fine part segmentation that identifies distinct rigid components, all in an unsupervised manner. The refined field provides a spatially continuous, fully decoupled description of every part, supporting part-level reconstruction and precise modeling of their kinematic relationships. To evaluate generalization and realism, we enlarge the synthetic PartNet-Mobility benchmark and release RS-Art, a real-to-sim dataset that pairs RGB captures with accurately reverse-engineered 3D models. Extensive experiments demonstrate that our method outperforms existing methods in both accuracy and stability.
Decomposition of Probabilities of Causation with Two Mediators
May 08, 2025
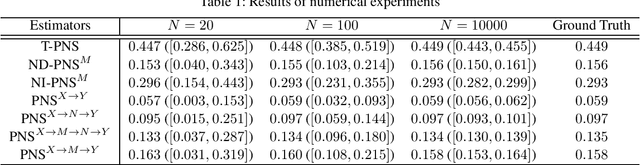


Mediation analysis for probabilities of causation (PoC) provides a fundamental framework for evaluating the necessity and sufficiency of treatment in provoking an event through different causal pathways. One of the primary objectives of causal mediation analysis is to decompose the total effect into path-specific components. In this study, we investigate the path-specific probability of necessity and sufficiency (PNS) to decompose the total PNS into path-specific components along distinct causal pathways between treatment and outcome, incorporating two mediators. We define the path-specific PNS for decomposition and provide an identification theorem. Furthermore, we conduct numerical experiments to assess the properties of the proposed estimators from finite samples and demonstrate their practical application using a real-world educational dataset.
Moments of Causal Effects
May 08, 2025The moments of random variables are fundamental statistical measures for characterizing the shape of a probability distribution, encompassing metrics such as mean, variance, skewness, and kurtosis. Additionally, the product moments, including covariance and correlation, reveal the relationships between multiple random variables. On the other hand, the primary focus of causal inference is the evaluation of causal effects, which are defined as the difference between two potential outcomes. While traditional causal effect assessment focuses on the average causal effect, this work provides definitions, identification theorems, and bounds for moments and product moments of causal effects to analyze their distribution and relationships. We conduct experiments to illustrate the estimation of the moments of causal effects from finite samples and demonstrate their practical application using a real-world medical dataset.
Dynamic Pyramid Network for Efficient Multimodal Large Language Model
Mar 26, 2025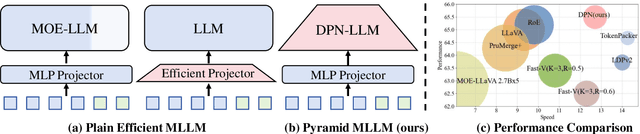

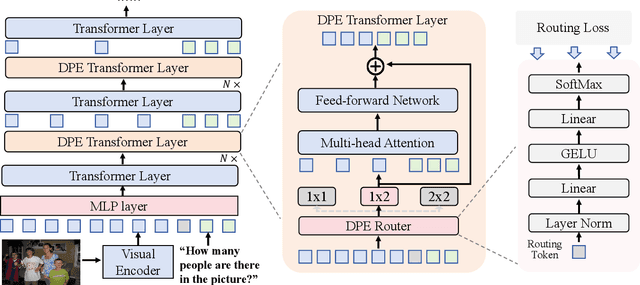

Multimodal large language models (MLLMs) have demonstrated impressive performance in various vision-language (VL) tasks, but their expensive computations still limit the real-world application. To address this issue, recent efforts aim to compress the visual features to save the computational costs of MLLMs. However, direct visual compression methods, e.g. efficient projectors, inevitably destroy the visual semantics in MLLM, especially in difficult samples. To overcome this shortcoming, we propose a novel dynamic pyramid network (DPN) for efficient MLLMs. Specifically, DPN formulates MLLM as a hierarchical structure where visual features are gradually compressed with increasing depth. In this case, even with a high compression ratio, fine-grained visual information can still be perceived in shallow layers. To maximize the benefit of DPN, we further propose an innovative Dynamic Pooling Experts (DPE) that can dynamically choose the optimal visual compression rate according to input features. With this design, harder samples will be assigned larger computations, thus preserving the model performance. To validate our approach, we conduct extensive experiments on two popular MLLMs and ten benchmarks. Experimental results show that DPN can save up to 56% average FLOPs on LLaVA while further achieving +0.74% performance gains. Besides, the generalization ability of DPN is also validated on the existing high-resolution MLLM called LLaVA-HR. Our source codes are anonymously released at https://github.com/aihao2000/DPN-LLaVA.
Standard-Deviation-Inspired Regularization for Improving Adversarial Robustness
Dec 27, 2024Adversarial Training (AT) has been demonstrated to improve the robustness of deep neural networks (DNNs) against adversarial attacks. AT is a min-max optimization procedure where in adversarial examples are generated to train a more robust DNN. The inner maximization step of AT increases the losses of inputs with respect to their actual classes. The outer minimization involves minimizing the losses on the adversarial examples obtained from the inner maximization. This work proposes a standard-deviation-inspired (SDI) regularization term to improve adversarial robustness and generalization. We argue that the inner maximization in AT is similar to minimizing a modified standard deviation of the model's output probabilities. Moreover, we suggest that maximizing this modified standard deviation can complement the outer minimization of the AT framework. To support our argument, we experimentally show that the SDI measure can be used to craft adversarial examples. Additionally, we demonstrate that combining the SDI regularization term with existing AT variants enhances the robustness of DNNs against stronger attacks, such as CW and Auto-attack, and improves generalization.
Mediation Analysis for Probabilities of Causation
Dec 19, 2024



Probabilities of causation (PoC) offer valuable insights for informed decision-making. This paper introduces novel variants of PoC-controlled direct, natural direct, and natural indirect probability of necessity and sufficiency (PNS). These metrics quantify the necessity and sufficiency of a treatment for producing an outcome, accounting for different causal pathways. We develop identification theorems for these new PoC measures, allowing for their estimation from observational data. We demonstrate the practical application of our results through an analysis of a real-world psychology dataset.
Effects of Muscle Synergy during Overhead Work with a Passive Shoulder Exoskeleton: A Case Study
Nov 23, 2024Objective: Shoulder exoskeletons can effectively assist with overhead work. However, their impacts on muscle synergy remain unclear. The objective is to systematically investigate the effects of the shoulder exoskeleton on muscle synergies during overhead work.Methods: Eight male participants were recruited to perform a screwing task both with (Intervention) and without (Normal) the exoskeleton. Eight muscles were monitored and muscle synergies were extracted using non-negative matrix factorization and electromyographic topographic maps. Results: The number of synergies extracted was the same (n = 2) in both conditions. Specifically, the first synergies in both conditions were identical, with the highest weight of AD and MD; while the second synergies were different between conditions, with highest weight of PM and MD, respectively. As for the first synergy in the Intervention condition, the activation profile significantly decreased, and the average recruitment level and activation duration were significantly lower (p<0.05). The regression analysis for the muscle synergies across conditions shows the changes of muscle synergies did not influence the sparseness of muscle synergies (p=0.7341). In the topographic maps, the mean value exhibited a significant decrease (p<0.001) and the entropy significantly increased (p<0.01). Conclusion: The exoskeleton does not alter the number of synergies and existing major synergies but may induce new synergies. It can also significantly decrease neural activation and may influence the heterogeneity of the distribution of monitored muscle activations. Significance: This study provides insights into the potential mechanisms of exoskeleton-assisted overhead work and guidance on improving the performance of exoskeletons.
A Novel Passive Occupational Shoulder Exoskeleton With Adjustable Peak Assistive Torque Angle For Overhead Tasks
Nov 21, 2024Objective: Overhead tasks are a primary inducement to work-related musculoskeletal disorders. Aiming to reduce shoulder physical loads, passive shoulder exoskeletons are increasingly prevalent in the industry due to their lightweight, affordability, and effectiveness. However, they can only handle specific tasks and struggle to balance compactness with a sufficient range of motion effectively. Method: We proposed a novel passive occupational shoulder exoskeleton designed to handle various overhead tasks at different arm elevation angles, ensuring sufficient ROM while maintaining compactness. By formulating kinematic models and simulations, an ergonomic shoulder structure was developed. Then, we presented a torque generator equipped with an adjustable peak assistive torque angle to switch between low and high assistance phases through a passive clutch mechanism. Ten healthy participants were recruited to validate its functionality by performing the screwing task. Results: Measured range of motion results demonstrated that the exoskeleton can ensure a sufficient ROM in both sagittal (164$^\circ$) and horizontal (158$^\circ$) flexion/extension movements. The experimental results of the screwing task showed that the exoskeleton could reduce muscle activation (up to 49.6%), perceived effort and frustration, and provide an improved user experience (scored 79.7 out of 100). Conclusion: These results indicate that the proposed exoskeleton can guarantee natural movements and provide efficient assistance during overhead work, and thus have the potential to reduce the risk of musculoskeletal disorders. Significance: The proposed exoskeleton provides insights into multi-task adaptability and efficient assistance, highlighting the potential for expanding the application of exoskeletons.
Graph-based Complexity for Causal Effect by Empirical Plug-in
Nov 15, 2024This paper focuses on the computational complexity of computing empirical plug-in estimates for causal effect queries. Given a causal graph and observational data, any identifiable causal query can be estimated from an expression over the observed variables, called the estimand. The estimand can then be evaluated by plugging in probabilities computed empirically from data. In contrast to conventional wisdom, which assumes that high dimensional probabilistic functions will lead to exponential evaluation time of the estimand. We show that computation can be done efficiently, potentially in time linear in the data size, depending on the estimand's hypergraph. In particular, we show that both the treewidth and hypertree width of the estimand's structure bound the evaluation complexity of the plug-in estimands, analogous to their role in the complexity of probabilistic inference in graphical models. Often, the hypertree width provides a more effective bound, since the empirical distributions are sparse.