 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStandard-Deviation-Inspired Regularization for Improving Adversarial Robustness
Dec 27, 2024Adversarial Training (AT) has been demonstrated to improve the robustness of deep neural networks (DNNs) against adversarial attacks. AT is a min-max optimization procedure where in adversarial examples are generated to train a more robust DNN. The inner maximization step of AT increases the losses of inputs with respect to their actual classes. The outer minimization involves minimizing the losses on the adversarial examples obtained from the inner maximization. This work proposes a standard-deviation-inspired (SDI) regularization term to improve adversarial robustness and generalization. We argue that the inner maximization in AT is similar to minimizing a modified standard deviation of the model's output probabilities. Moreover, we suggest that maximizing this modified standard deviation can complement the outer minimization of the AT framework. To support our argument, we experimentally show that the SDI measure can be used to craft adversarial examples. Additionally, we demonstrate that combining the SDI regularization term with existing AT variants enhances the robustness of DNNs against stronger attacks, such as CW and Auto-attack, and improves generalization.
Improving Adversarial Training using Vulnerability-Aware Perturbation Budget
Mar 06, 2024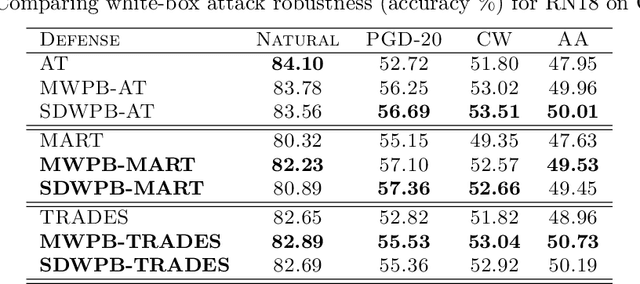
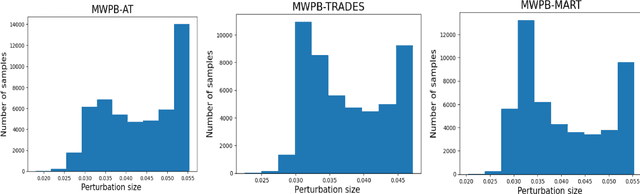
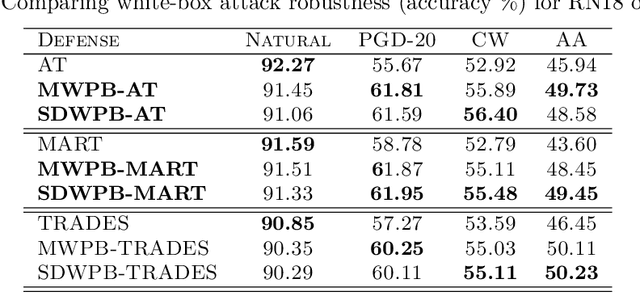
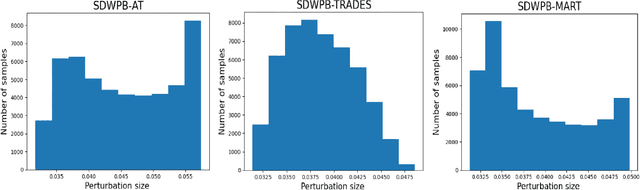
Adversarial Training (AT) effectively improves the robustness of Deep Neural Networks (DNNs) to adversarial attacks. Generally, AT involves training DNN models with adversarial examples obtained within a pre-defined, fixed perturbation bound. Notably, individual natural examples from which these adversarial examples are crafted exhibit varying degrees of intrinsic vulnerabilities, and as such, crafting adversarial examples with fixed perturbation radius for all instances may not sufficiently unleash the potency of AT. Motivated by this observation, we propose two simple, computationally cheap vulnerability-aware reweighting functions for assigning perturbation bounds to adversarial examples used for AT, named Margin-Weighted Perturbation Budget (MWPB) and Standard-Deviation-Weighted Perturbation Budget (SDWPB). The proposed methods assign perturbation radii to individual adversarial samples based on the vulnerability of their corresponding natural examples. Experimental results show that the proposed methods yield genuine improvements in the robustness of AT algorithms against various adversarial attacks.
Vulnerability-Aware Instance Reweighting For Adversarial Training
Jul 14, 2023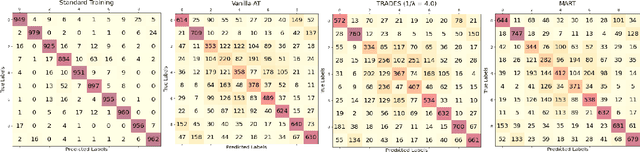


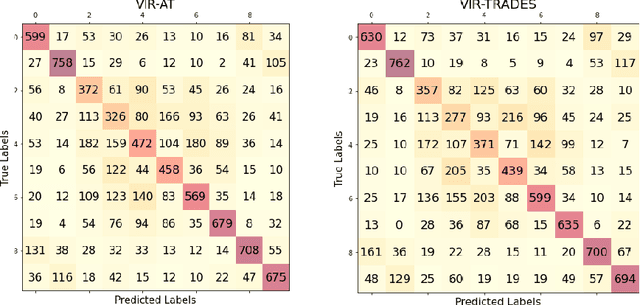
Adversarial Training (AT) has been found to substantially improve the robustness of deep learning classifiers against adversarial attacks. AT involves obtaining robustness by including adversarial examples in training a classifier. Most variants of AT algorithms treat every training example equally. However, recent works have shown that better performance is achievable by treating them unequally. In addition, it has been observed that AT exerts an uneven influence on different classes in a training set and unfairly hurts examples corresponding to classes that are inherently harder to classify. Consequently, various reweighting schemes have been proposed that assign unequal weights to robust losses of individual examples in a training set. In this work, we propose a novel instance-wise reweighting scheme. It considers the vulnerability of each natural example and the resulting information loss on its adversarial counterpart occasioned by adversarial attacks. Through extensive experiments, we show that our proposed method significantly improves over existing reweighting schemes, especially against strong white and black-box attacks.
Improving Adversarial Robustness with Hypersphere Embedding and Angular-based Regularizations
Mar 15, 2023



Adversarial training (AT) methods have been found to be effective against adversarial attacks on deep neural networks. Many variants of AT have been proposed to improve its performance. Pang et al. [1] have recently shown that incorporating hypersphere embedding (HE) into the existing AT procedures enhances robustness. We observe that the existing AT procedures are not designed for the HE framework, and thus fail to adequately learn the angular discriminative information available in the HE framework. In this paper, we propose integrating HE into AT with regularization terms that exploit the rich angular information available in the HE framework. Specifically, our method, termed angular-AT, adds regularization terms to AT that explicitly enforce weight-feature compactness and inter-class separation; all expressed in terms of angular features. Experimental results show that angular-AT further improves adversarial robustness.