 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Adversarial Training using Vulnerability-Aware Perturbation Budget
Paper and Code
Mar 06, 2024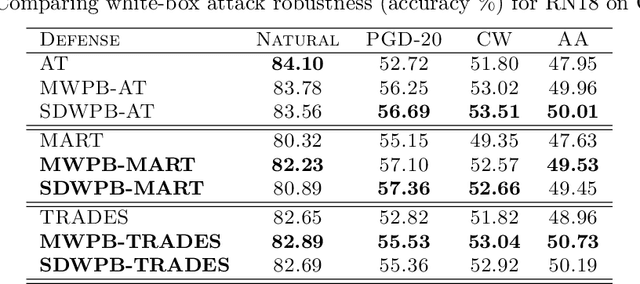
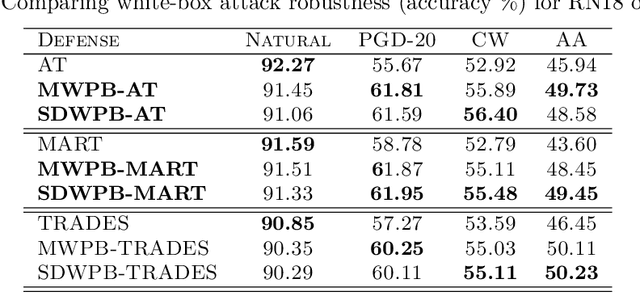
Adversarial Training (AT) effectively improves the robustness of Deep Neural Networks (DNNs) to adversarial attacks. Generally, AT involves training DNN models with adversarial examples obtained within a pre-defined, fixed perturbation bound. Notably, individual natural examples from which these adversarial examples are crafted exhibit varying degrees of intrinsic vulnerabilities, and as such, crafting adversarial examples with fixed perturbation radius for all instances may not sufficiently unleash the potency of AT. Motivated by this observation, we propose two simple, computationally cheap vulnerability-aware reweighting functions for assigning perturbation bounds to adversarial examples used for AT, named Margin-Weighted Perturbation Budget (MWPB) and Standard-Deviation-Weighted Perturbation Budget (SDWPB). The proposed methods assign perturbation radii to individual adversarial samples based on the vulnerability of their corresponding natural examples. Experimental results show that the proposed methods yield genuine improvements in the robustness of AT algorithms against various adversarial attacks.