 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen CaptchaWorld: A Comprehensive Web-based Platform for Testing and Benchmarking Multimodal LLM Agents
May 30, 2025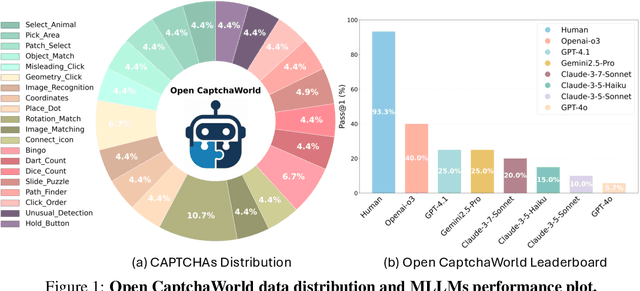
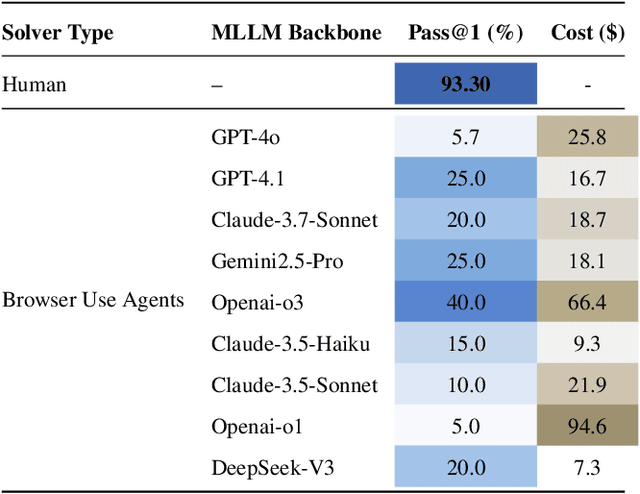

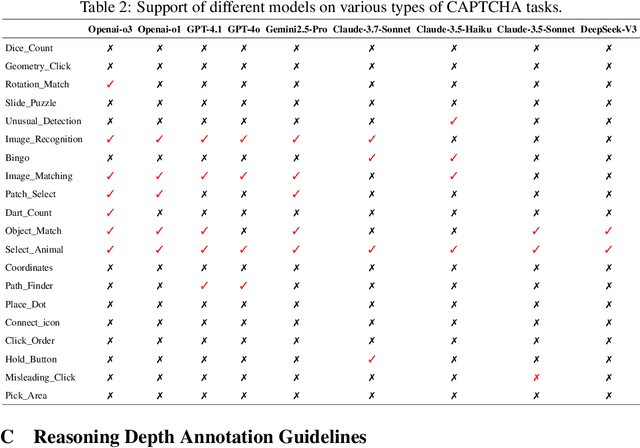
CAPTCHAs have been a critical bottleneck for deploying web agents in real-world applications, often blocking them from completing end-to-end automation tasks. While modern multimodal LLM agents have demonstrated impressive performance in static perception tasks, their ability to handle interactive, multi-step reasoning challenges like CAPTCHAs is largely untested. To address this gap, we introduce Open CaptchaWorld, the first web-based benchmark and platform specifically designed to evaluate the visual reasoning and interaction capabilities of MLLM-powered agents through diverse and dynamic CAPTCHA puzzles. Our benchmark spans 20 modern CAPTCHA types, totaling 225 CAPTCHAs, annotated with a new metric we propose: CAPTCHA Reasoning Depth, which quantifies the number of cognitive and motor steps required to solve each puzzle. Experimental results show that humans consistently achieve near-perfect scores, state-of-the-art MLLM agents struggle significantly, with success rates at most 40.0% by Browser-Use Openai-o3, far below human-level performance, 93.3%. This highlights Open CaptchaWorld as a vital benchmark for diagnosing the limits of current multimodal agents and guiding the development of more robust multimodal reasoning systems. Code and Data are available at this https URL.
Dynamic Pyramid Network for Efficient Multimodal Large Language Model
Mar 26, 2025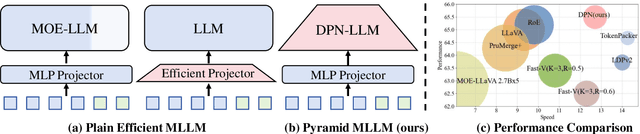

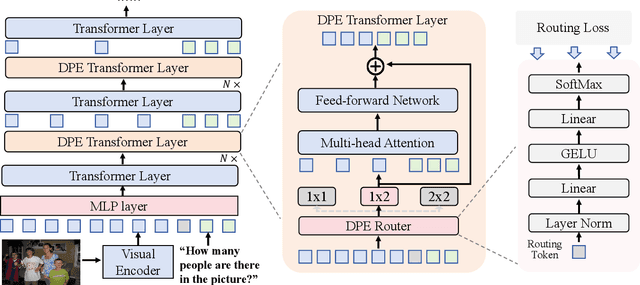

Multimodal large language models (MLLMs) have demonstrated impressive performance in various vision-language (VL) tasks, but their expensive computations still limit the real-world application. To address this issue, recent efforts aim to compress the visual features to save the computational costs of MLLMs. However, direct visual compression methods, e.g. efficient projectors, inevitably destroy the visual semantics in MLLM, especially in difficult samples. To overcome this shortcoming, we propose a novel dynamic pyramid network (DPN) for efficient MLLMs. Specifically, DPN formulates MLLM as a hierarchical structure where visual features are gradually compressed with increasing depth. In this case, even with a high compression ratio, fine-grained visual information can still be perceived in shallow layers. To maximize the benefit of DPN, we further propose an innovative Dynamic Pooling Experts (DPE) that can dynamically choose the optimal visual compression rate according to input features. With this design, harder samples will be assigned larger computations, thus preserving the model performance. To validate our approach, we conduct extensive experiments on two popular MLLMs and ten benchmarks. Experimental results show that DPN can save up to 56% average FLOPs on LLaVA while further achieving +0.74% performance gains. Besides, the generalization ability of DPN is also validated on the existing high-resolution MLLM called LLaVA-HR. Our source codes are anonymously released at https://github.com/aihao2000/DPN-LLaVA.
Dataset Distillation via Committee Voting
Jan 13, 2025Dataset distillation aims to synthesize a smaller, representative dataset that preserves the essential properties of the original data, enabling efficient model training with reduced computational resources. Prior work has primarily focused on improving the alignment or matching process between original and synthetic data, or on enhancing the efficiency of distilling large datasets. In this work, we introduce ${\bf C}$ommittee ${\bf V}$oting for ${\bf D}$ataset ${\bf D}$istillation (CV-DD), a novel and orthogonal approach that leverages the collective wisdom of multiple models or experts to create high-quality distilled datasets. We start by showing how to establish a strong baseline that already achieves state-of-the-art accuracy through leveraging recent advancements and thoughtful adjustments in model design and optimization processes. By integrating distributions and predictions from a committee of models while generating high-quality soft labels, our method captures a wider spectrum of data features, reduces model-specific biases and the adverse effects of distribution shifts, leading to significant improvements in generalization. This voting-based strategy not only promotes diversity and robustness within the distilled dataset but also significantly reduces overfitting, resulting in improved performance on post-eval tasks. Extensive experiments across various datasets and IPCs (images per class) demonstrate that Committee Voting leads to more reliable and adaptable distilled data compared to single/multi-model distillation methods, demonstrating its potential for efficient and accurate dataset distillation. Code is available at: https://github.com/Jiacheng8/CV-DD.
$γ-$MoD: Exploring Mixture-of-Depth Adaptation for Multimodal Large Language Models
Oct 17, 2024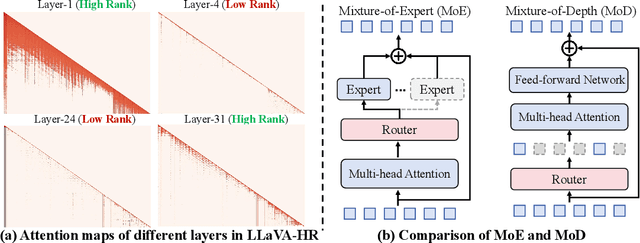

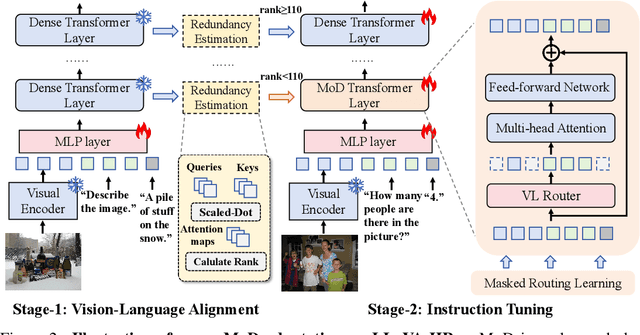

Despite the significant progress in multimodal large language models (MLLMs), their high computational cost remains a barrier to real-world deployment. Inspired by the mixture of depths (MoDs) in natural language processing, we aim to address this limitation from the perspective of ``activated tokens''. Our key insight is that if most tokens are redundant for the layer computation, then can be skipped directly via the MoD layer. However, directly converting the dense layers of MLLMs to MoD layers leads to substantial performance degradation. To address this issue, we propose an innovative MoD adaptation strategy for existing MLLMs called $\gamma$-MoD. In $\gamma$-MoD, a novel metric is proposed to guide the deployment of MoDs in the MLLM, namely rank of attention maps (ARank). Through ARank, we can effectively identify which layer is redundant and should be replaced with the MoD layer. Based on ARank, we further propose two novel designs to maximize the computational sparsity of MLLM while maintaining its performance, namely shared vision-language router and masked routing learning. With these designs, more than 90% dense layers of the MLLM can be effectively converted to the MoD ones. To validate our method, we apply it to three popular MLLMs, and conduct extensive experiments on 9 benchmark datasets. Experimental results not only validate the significant efficiency benefit of $\gamma$-MoD to existing MLLMs but also confirm its generalization ability on various MLLMs. For example, with a minor performance drop, i.e., -1.5%, $\gamma$-MoD can reduce the training and inference time of LLaVA-HR by 31.0% and 53.2%, respectively.