 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard Labels In! Rethinking the Role of Hard Labels in Mitigating Local Semantic Drift
Dec 22, 2025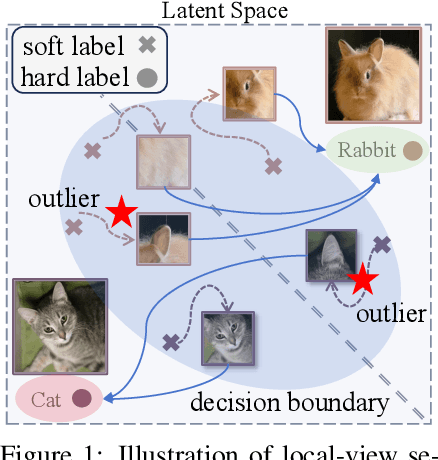
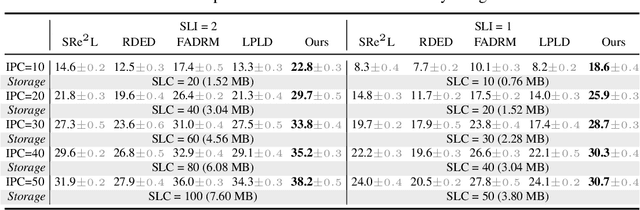
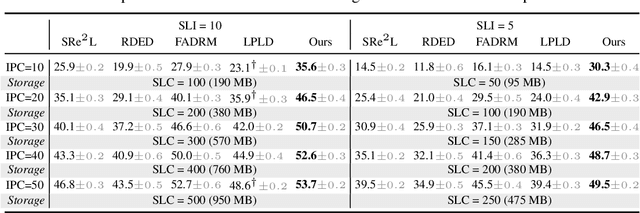
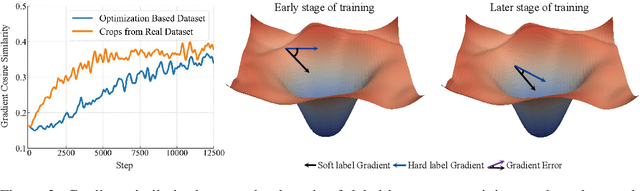
Soft labels generated by teacher models have become a dominant paradigm for knowledge transfer and recent large-scale dataset distillation such as SRe2L, RDED, LPLD, offering richer supervision than conventional hard labels. However, we observe that when only a limited number of crops per image are used, soft labels are prone to local semantic drift: a crop may visually resemble another class, causing its soft embedding to deviate from the ground-truth semantics of the original image. This mismatch between local visual content and global semantic meaning introduces systematic errors and distribution misalignment between training and testing. In this work, we revisit the overlooked role of hard labels and show that, when appropriately integrated, they provide a powerful content-agnostic anchor to calibrate semantic drift. We theoretically characterize the emergence of drift under few soft-label supervision and demonstrate that hybridizing soft and hard labels restores alignment between visual content and semantic supervision. Building on this insight, we propose a new training paradigm, Hard Label for Alleviating Local Semantic Drift (HALD), which leverages hard labels as intermediate corrective signals while retaining the fine-grained advantages of soft labels. Extensive experiments on dataset distillation and large-scale conventional classification benchmarks validate our approach, showing consistent improvements in generalization. On ImageNet-1K, we achieve 42.7% with only 285M storage for soft labels, outperforming prior state-of-the-art LPLD by 9.0%. Our findings re-establish the importance of hard labels as a complementary tool, and call for a rethinking of their role in soft-label-dominated training.
CaberNet: Causal Representation Learning for Cross-Domain HVAC Energy Prediction
Nov 10, 2025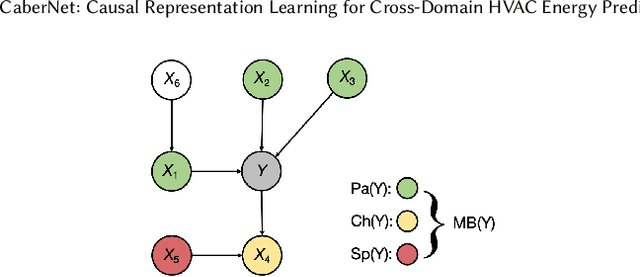



Cross-domain HVAC energy prediction is essential for scalable building energy management, particularly because collecting extensive labeled data for every new building is both costly and impractical. Yet, this task remains highly challenging due to the scarcity and heterogeneity of data across different buildings, climate zones, and seasonal patterns. In particular, buildings situated in distinct climatic regions introduce variability that often leads existing methods to overfit to spurious correlations, rely heavily on expert intervention, or compromise on data diversity. To address these limitations, we propose CaberNet, a causal and interpretable deep sequence model that learns invariant (Markov blanket) representations for robust cross-domain prediction. In a purely data-driven fashion and without requiring any prior knowledge, CaberNet integrates i) a global feature gate trained with a self-supervised Bernoulli regularization to distinguish superior causal features from inferior ones, and ii) a domain-wise training scheme that balances domain contributions, minimizes cross-domain loss variance, and promotes latent factor independence. We evaluate CaberNet on real-world datasets collected from three buildings located in three climatically diverse cities, and it consistently outperforms all baselines, achieving a 22.9\% reduction in normalized mean squared error (NMSE) compared to the best benchmark. Our code is available at https://github.com/rickzky1001/CaberNet-CRL.
Open CaptchaWorld: A Comprehensive Web-based Platform for Testing and Benchmarking Multimodal LLM Agents
May 30, 2025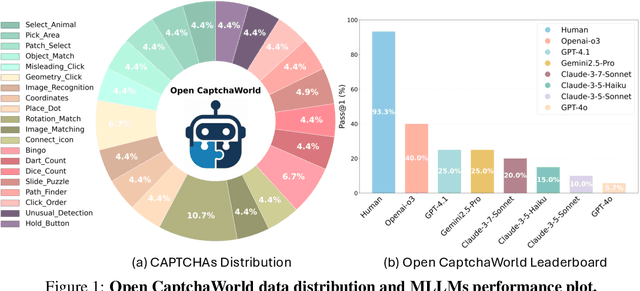
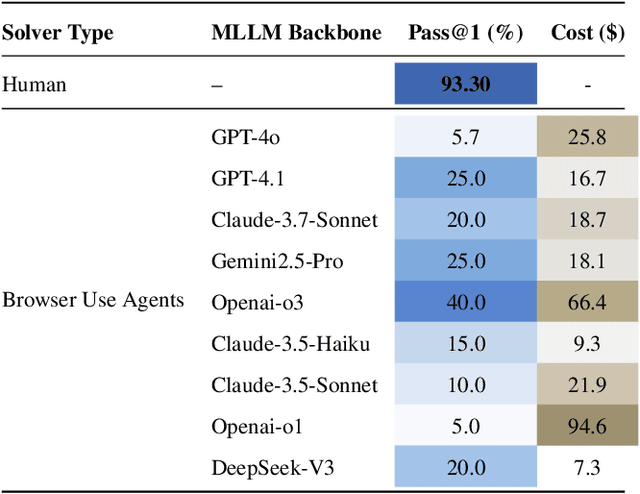

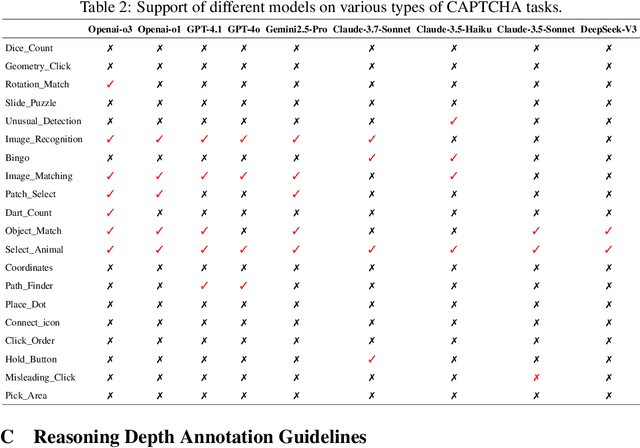
CAPTCHAs have been a critical bottleneck for deploying web agents in real-world applications, often blocking them from completing end-to-end automation tasks. While modern multimodal LLM agents have demonstrated impressive performance in static perception tasks, their ability to handle interactive, multi-step reasoning challenges like CAPTCHAs is largely untested. To address this gap, we introduce Open CaptchaWorld, the first web-based benchmark and platform specifically designed to evaluate the visual reasoning and interaction capabilities of MLLM-powered agents through diverse and dynamic CAPTCHA puzzles. Our benchmark spans 20 modern CAPTCHA types, totaling 225 CAPTCHAs, annotated with a new metric we propose: CAPTCHA Reasoning Depth, which quantifies the number of cognitive and motor steps required to solve each puzzle. Experimental results show that humans consistently achieve near-perfect scores, state-of-the-art MLLM agents struggle significantly, with success rates at most 40.0% by Browser-Use Openai-o3, far below human-level performance, 93.3%. This highlights Open CaptchaWorld as a vital benchmark for diagnosing the limits of current multimodal agents and guiding the development of more robust multimodal reasoning systems. Code and Data are available at this https URL.
A Frustratingly Simple Yet Highly Effective Attack Baseline: Over 90% Success Rate Against the Strong Black-box Models of GPT-4.5/4o/o1
Mar 13, 2025Despite promising performance on open-source large vision-language models (LVLMs), transfer-based targeted attacks often fail against black-box commercial LVLMs. Analyzing failed adversarial perturbations reveals that the learned perturbations typically originate from a uniform distribution and lack clear semantic details, resulting in unintended responses. This critical absence of semantic information leads commercial LVLMs to either ignore the perturbation entirely or misinterpret its embedded semantics, thereby causing the attack to fail. To overcome these issues, we notice that identifying core semantic objects is a key objective for models trained with various datasets and methodologies. This insight motivates our approach that refines semantic clarity by encoding explicit semantic details within local regions, thus ensuring interoperability and capturing finer-grained features, and by concentrating modifications on semantically rich areas rather than applying them uniformly. To achieve this, we propose a simple yet highly effective solution: at each optimization step, the adversarial image is cropped randomly by a controlled aspect ratio and scale, resized, and then aligned with the target image in the embedding space. Experimental results confirm our hypothesis. Our adversarial examples crafted with local-aggregated perturbations focused on crucial regions exhibit surprisingly good transferability to commercial LVLMs, including GPT-4.5, GPT-4o, Gemini-2.0-flash, Claude-3.5-sonnet, Claude-3.7-sonnet, and even reasoning models like o1, Claude-3.7-thinking and Gemini-2.0-flash-thinking. Our approach achieves success rates exceeding 90% on GPT-4.5, 4o, and o1, significantly outperforming all prior state-of-the-art attack methods. Our optimized adversarial examples under different configurations and training code are available at https://github.com/VILA-Lab/M-Attack.
Dataset Distillation via Committee Voting
Jan 13, 2025Dataset distillation aims to synthesize a smaller, representative dataset that preserves the essential properties of the original data, enabling efficient model training with reduced computational resources. Prior work has primarily focused on improving the alignment or matching process between original and synthetic data, or on enhancing the efficiency of distilling large datasets. In this work, we introduce ${\bf C}$ommittee ${\bf V}$oting for ${\bf D}$ataset ${\bf D}$istillation (CV-DD), a novel and orthogonal approach that leverages the collective wisdom of multiple models or experts to create high-quality distilled datasets. We start by showing how to establish a strong baseline that already achieves state-of-the-art accuracy through leveraging recent advancements and thoughtful adjustments in model design and optimization processes. By integrating distributions and predictions from a committee of models while generating high-quality soft labels, our method captures a wider spectrum of data features, reduces model-specific biases and the adverse effects of distribution shifts, leading to significant improvements in generalization. This voting-based strategy not only promotes diversity and robustness within the distilled dataset but also significantly reduces overfitting, resulting in improved performance on post-eval tasks. Extensive experiments across various datasets and IPCs (images per class) demonstrate that Committee Voting leads to more reliable and adaptable distilled data compared to single/multi-model distillation methods, demonstrating its potential for efficient and accurate dataset distillation. Code is available at: https://github.com/Jiacheng8/CV-DD.