 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositive-Unlabeled Reinforcement Learning Distillation for On-Premise Small Models
Jan 28, 2026Due to constraints on privacy, cost, and latency, on-premise deployment of small models is increasingly common. However, most practical pipelines stop at supervised fine-tuning (SFT) and fail to reach the reinforcement learning (RL) alignment stage. The main reason is that RL alignment typically requires either expensive human preference annotation or heavy reliance on high-quality reward models with large-scale API usage and ongoing engineering maintenance, both of which are ill-suited to on-premise settings. To bridge this gap, we propose a positive-unlabeled (PU) RL distillation method for on-premise small-model deployment. Without human-labeled preferences or a reward model, our method distills the teacher's preference-optimization capability from black-box generations into a locally trainable student. For each prompt, we query the teacher once to obtain an anchor response, locally sample multiple student candidates, and perform anchor-conditioned self-ranking to induce pairwise or listwise preferences, enabling a fully local training loop via direct preference optimization or group relative policy optimization. Theoretical analysis justifies that the induced preference signal by our method is order-consistent and concentrates on near-optimal candidates, supporting its stability for preference optimization. Experiments demonstrate that our method achieves consistently strong performance under a low-cost setting.
A Frustratingly Simple Yet Highly Effective Attack Baseline: Over 90% Success Rate Against the Strong Black-box Models of GPT-4.5/4o/o1
Mar 13, 2025Despite promising performance on open-source large vision-language models (LVLMs), transfer-based targeted attacks often fail against black-box commercial LVLMs. Analyzing failed adversarial perturbations reveals that the learned perturbations typically originate from a uniform distribution and lack clear semantic details, resulting in unintended responses. This critical absence of semantic information leads commercial LVLMs to either ignore the perturbation entirely or misinterpret its embedded semantics, thereby causing the attack to fail. To overcome these issues, we notice that identifying core semantic objects is a key objective for models trained with various datasets and methodologies. This insight motivates our approach that refines semantic clarity by encoding explicit semantic details within local regions, thus ensuring interoperability and capturing finer-grained features, and by concentrating modifications on semantically rich areas rather than applying them uniformly. To achieve this, we propose a simple yet highly effective solution: at each optimization step, the adversarial image is cropped randomly by a controlled aspect ratio and scale, resized, and then aligned with the target image in the embedding space. Experimental results confirm our hypothesis. Our adversarial examples crafted with local-aggregated perturbations focused on crucial regions exhibit surprisingly good transferability to commercial LVLMs, including GPT-4.5, GPT-4o, Gemini-2.0-flash, Claude-3.5-sonnet, Claude-3.7-sonnet, and even reasoning models like o1, Claude-3.7-thinking and Gemini-2.0-flash-thinking. Our approach achieves success rates exceeding 90% on GPT-4.5, 4o, and o1, significantly outperforming all prior state-of-the-art attack methods. Our optimized adversarial examples under different configurations and training code are available at https://github.com/VILA-Lab/M-Attack.
Robust Representation Learning for Unreliable Partial Label Learning
Aug 31, 2023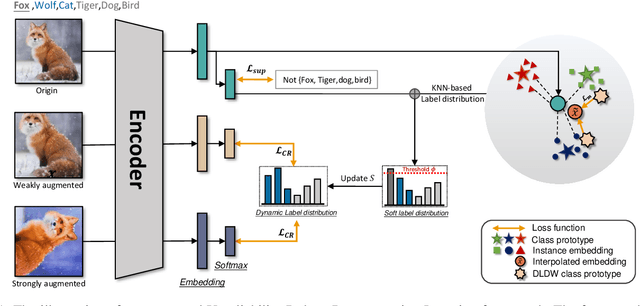
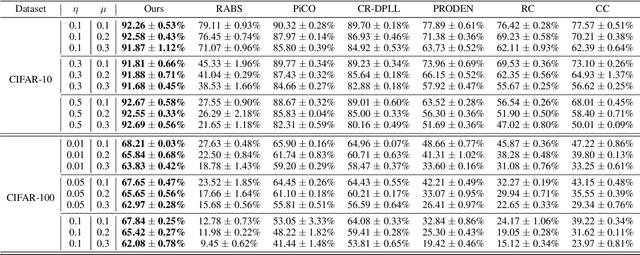
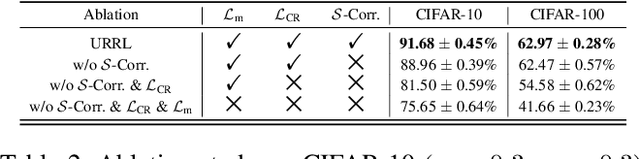
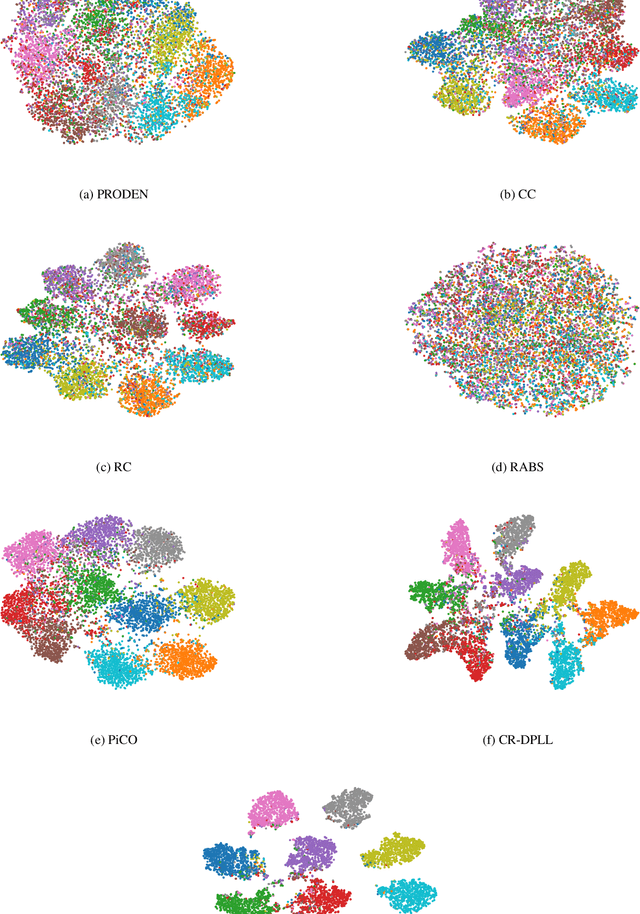
Partial Label Learning (PLL) is a type of weakly supervised learning where each training instance is assigned a set of candidate labels, but only one label is the ground-truth. However, this idealistic assumption may not always hold due to potential annotation inaccuracies, meaning the ground-truth may not be present in the candidate label set. This is known as Unreliable Partial Label Learning (UPLL) that introduces an additional complexity due to the inherent unreliability and ambiguity of partial labels, often resulting in a sub-optimal performance with existing methods. To address this challenge, we propose the Unreliability-Robust Representation Learning framework (URRL) that leverages unreliability-robust contrastive learning to help the model fortify against unreliable partial labels effectively. Concurrently, we propose a dual strategy that combines KNN-based candidate label set correction and consistency-regularization-based label disambiguation to refine label quality and enhance the ability of representation learning within the URRL framework. Extensive experiments demonstrate that the proposed method outperforms state-of-the-art PLL methods on various datasets with diverse degrees of unreliability and ambiguity. Furthermore, we provide a theoretical analysis of our approach from the perspective of the expectation maximization (EM) algorithm. Upon acceptance, we pledge to make the code publicly accessible.