 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Imbalance Causes Forgetting in Low-Rank Continual Adaptation
Jan 31, 2026Parameter-efficient continual learning aims to adapt pre-trained models to sequential tasks without forgetting previously acquired knowledge. Most existing approaches treat continual learning as avoiding interference with past updates, rather than considering what properties make the current task-specific update naturally preserve previously acquired knowledge. From a knowledge-decomposition perspective, we observe that low-rank adaptations exhibit highly imbalanced singular value spectra: a few dominant components absorb most of the adaptation energy, thereby (i) more likely to disrupt previously acquired knowledge and (ii) making the update more vulnerable to interference from subsequent tasks. To enable explicit balance among components, we decouple the magnitude of the task update from its directional structure and formulate it as a constrained optimization problem on a restricted Stiefel manifold. We address this problem using a projected first-order method compatible with standard deep-learning optimizers used in vision-language models. Our method mitigates both backward and forward forgetting, consistently outperforming continual learning baselines. The implementation code is available at https://github.com/haodotgu/EBLoRA.
Guided by Trajectories: Repairing and Rewarding Tool-Use Trajectories for Tool-Integrated Reasoning
Jan 30, 2026Tool-Integrated Reasoning (TIR) enables large language models (LLMs) to solve complex tasks by interacting with external tools, yet existing approaches depend on high-quality synthesized trajectories selected by scoring functions and sparse outcome-based rewards, providing limited and biased supervision for learning TIR. To address these challenges, in this paper, we propose AutoTraj, a two-stage framework that automatically learns TIR by repairing and rewarding tool-use trajectories. Specifically, in the supervised fine-tuning (SFT) stage, AutoTraj generates multiple candidate tool-use trajectories for each query and evaluates them along multiple dimensions. High-quality trajectories are directly retained, while low-quality ones are repaired using a LLM (i.e., LLM-as-Repairer). The resulting repaired and high-quality trajectories form a synthetic SFT dataset, while each repaired trajectory paired with its original low-quality counterpart constitutes a dataset for trajectory preference modeling. In the reinforcement learning (RL) stage, based on the preference dataset, we train a trajectory-level reward model to assess the quality of reasoning paths and combine it with outcome and format rewards, thereby explicitly guiding the optimization toward reliable TIR behaviors. Experiments on real-world benchmarks demonstrate the effectiveness of AutoTraj in TIR.
KeepLoRA: Continual Learning with Residual Gradient Adaptation
Jan 27, 2026Continual learning for pre-trained vision-language models requires balancing three competing objectives: retaining pre-trained knowledge, preserving knowledge from a sequence of learned tasks, and maintaining the plasticity to acquire new knowledge. This paper presents a simple but effective approach called KeepLoRA to effectively balance these objectives. We first analyze the knowledge retention mechanism within the model parameter space and find that general knowledge is mainly encoded in the principal subspace, while task-specific knowledge is encoded in the residual subspace. Motivated by this finding, KeepLoRA learns new tasks by restricting LoRA parameter updates in the residual subspace to prevent interfering with previously learned capabilities. Specifically, we infuse knowledge for a new task by projecting its gradient onto a subspace orthogonal to both the principal subspace of pre-trained model and the dominant directions of previous task features. Our theoretical and empirical analyses confirm that KeepLoRA balances the three objectives and achieves state-of-the-art performance. The implementation code is available at https://github.com/MaolinLuo/KeepLoRA.
Training Multimodal Large Reasoning Models Needs Better Thoughts: A Three-Stage Framework for Long Chain-of-Thought Synthesis and Selection
Dec 22, 2025Large Reasoning Models (LRMs) have demonstrated remarkable performance on complex reasoning tasks through long Chain-of-Thought (CoT) reasoning. Extending these successes to multimodal reasoning remains challenging due to the increased complexity of integrating diverse input modalities and the scarcity of high-quality long CoT training data. Existing multimodal datasets and CoT synthesis methods still suffer from limited reasoning depth, modality conversion errors, and rigid generation pipelines, hindering model performance and stability. To this end, in this paper, we propose SynSelect, a novel three-stage Synthesis-Selection framework for generating high-quality long CoT data tailored to multimodal reasoning tasks. Specifically, SynSelect first leverages multiple heterogeneous multimodal LRMs to produce diverse candidate CoTs, and then applies both instance and batch level selection to filter high-quality CoTs that can effectively enhance the model's reasoning capabilities. Extensive experiments on multiple multimodal benchmarks demonstrate that models supervised fine-tuned on SynSelect-generated data significantly outperform baselines and achieve further improvements after reinforcement learning post-training. Our results validate SynSelect as an effective approach for advancing multimodal LRMs reasoning capabilities.
Calibratable Disambiguation Loss for Multi-Instance Partial-Label Learning
Dec 19, 2025Multi-instance partial-label learning (MIPL) is a weakly supervised framework that extends the principles of multi-instance learning (MIL) and partial-label learning (PLL) to address the challenges of inexact supervision in both instance and label spaces. However, existing MIPL approaches often suffer from poor calibration, undermining classifier reliability. In this work, we propose a plug-and-play calibratable disambiguation loss (CDL) that simultaneously improves classification accuracy and calibration performance. The loss has two instantiations: the first one calibrates predictions based on probabilities from the candidate label set, while the second one integrates probabilities from both candidate and non-candidate label sets. The proposed CDL can be seamlessly incorporated into existing MIPL and PLL frameworks. We provide a theoretical analysis that establishes the lower bound and regularization properties of CDL, demonstrating its superiority over conventional disambiguation losses. Experimental results on benchmark and real-world datasets confirm that our CDL significantly enhances both classification and calibration performance.
Agentic Video Intelligence: A Flexible Framework for Advanced Video Exploration and Understanding
Nov 18, 2025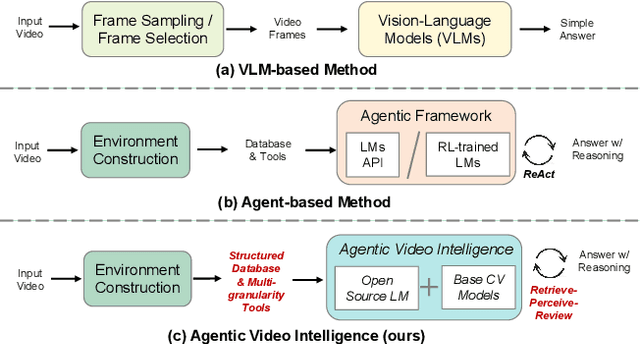
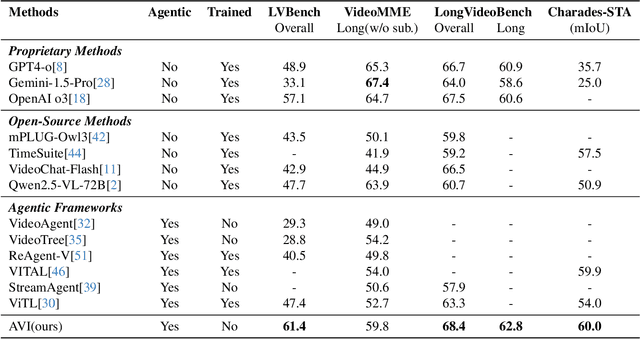
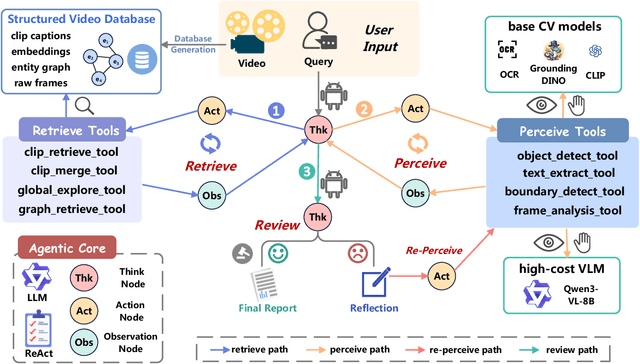
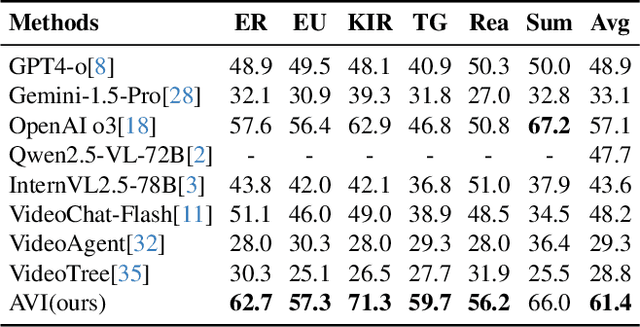
Video understanding requires not only visual recognition but also complex reasoning. While Vision-Language Models (VLMs) demonstrate impressive capabilities, they typically process videos largely in a single-pass manner with limited support for evidence revisit and iterative refinement. While recently emerging agent-based methods enable long-horizon reasoning, they either depend heavily on expensive proprietary models or require extensive agentic RL training. To overcome these limitations, we propose Agentic Video Intelligence (AVI), a flexible and training-free framework that can mirror human video comprehension through system-level design and optimization. AVI introduces three key innovations: (1) a human-inspired three-phase reasoning process (Retrieve-Perceive-Review) that ensures both sufficient global exploration and focused local analysis, (2) a structured video knowledge base organized through entity graphs, along with multi-granularity integrated tools, constituting the agent's interaction environment, and (3) an open-source model ensemble combining reasoning LLMs with lightweight base CV models and VLM, eliminating dependence on proprietary APIs or RL training. Experiments on LVBench, VideoMME-Long, LongVideoBench, and Charades-STA demonstrate that AVI achieves competitive performance while offering superior interpretability.
Tuning the Right Foundation Models is What you Need for Partial Label Learning
Jun 05, 2025Partial label learning (PLL) seeks to train generalizable classifiers from datasets with inexact supervision, a common challenge in real-world applications. Existing studies have developed numerous approaches to progressively refine and recover ground-truth labels by training convolutional neural networks. However, limited attention has been given to foundation models that offer transferrable representations. In this work, we empirically conduct comprehensive evaluations of 11 foundation models across 13 PLL approaches on 8 benchmark datasets under 3 PLL scenarios. We further propose PartialCLIP, an efficient fine-tuning framework for foundation models in PLL. Our findings reveal that current PLL approaches tend to 1) achieve significant performance gains when using foundation models, 2) exhibit remarkably similar performance to each other, 3) maintain stable performance across varying ambiguity levels, while 4) are susceptible to foundation model selection and adaptation strategies. Additionally, we demonstrate the efficacy of text-embedding classifier initialization and effective candidate label filtering using zero-shot CLIP. Our experimental results and analysis underscore the limitations of current PLL approaches and provide valuable insights for developing more generalizable PLL models. The source code can be found at https://github.com/SEU-hk/PartialCLIP.
LADA: Scalable Label-Specific CLIP Adapter for Continual Learning
May 29, 2025Continual learning with vision-language models like CLIP offers a pathway toward scalable machine learning systems by leveraging its transferable representations. Existing CLIP-based methods adapt the pre-trained image encoder by adding multiple sets of learnable parameters, with each task using a partial set of parameters. This requires selecting the expected parameters for input images during inference, which is prone to error that degrades performance. To address this problem, we introduce LADA (Label-specific ADApter). Instead of partitioning parameters across tasks, LADA appends lightweight, label-specific memory units to the frozen CLIP image encoder, enabling discriminative feature generation by aggregating task-agnostic knowledge. To prevent catastrophic forgetting, LADA employs feature distillation for seen classes, preventing their features from being interfered with by new classes. Positioned after the image encoder, LADA prevents gradient flow to the frozen CLIP parameters, ensuring efficient training. Extensive results show that LADA achieves state-of-the-art performance in continual learning settings. The implementation code is available at https://github.com/MaolinLuo/LADA.
HACSurv: A Hierarchical Copula-based Approach for Survival Analysis with Dependent Competing Risks
Oct 19, 2024



In survival analysis, subjects often face competing risks; for example, individuals with cancer may also suffer from heart disease or other illnesses, which can jointly influence the prognosis of risks and censoring. Traditional survival analysis methods often treat competing risks as independent and fail to accommodate the dependencies between different conditions. In this paper, we introduce HACSurv, a survival analysis method that learns Hierarchical Archimedean Copulas structures and cause-specific survival functions from data with competing risks. HACSurv employs a flexible dependency structure using hierarchical Archimedean copulas to represent the relationships between competing risks and censoring. By capturing the dependencies between risks and censoring, HACSurv achieves better survival predictions and offers insights into risk interactions. Experiments on synthetic datasets demonstrate that our method can accurately identify the complex dependency structure and precisely predict survival distributions, whereas the compared methods exhibit significant deviations between their predictions and the true distributions. Experiments on multiple real-world datasets also demonstrate that our method achieves better survival prediction compared to previous state-of-the-art methods.
Continuous Contrastive Learning for Long-Tailed Semi-Supervised Recognition
Oct 08, 2024Long-tailed semi-supervised learning poses a significant challenge in training models with limited labeled data exhibiting a long-tailed label distribution. Current state-of-the-art LTSSL approaches heavily rely on high-quality pseudo-labels for large-scale unlabeled data. However, these methods often neglect the impact of representations learned by the neural network and struggle with real-world unlabeled data, which typically follows a different distribution than labeled data. This paper introduces a novel probabilistic framework that unifies various recent proposals in long-tail learning. Our framework derives the class-balanced contrastive loss through Gaussian kernel density estimation. We introduce a continuous contrastive learning method, CCL, extending our framework to unlabeled data using reliable and smoothed pseudo-labels. By progressively estimating the underlying label distribution and optimizing its alignment with model predictions, we tackle the diverse distribution of unlabeled data in real-world scenarios. Extensive experiments across multiple datasets with varying unlabeled data distributions demonstrate that CCL consistently outperforms prior state-of-the-art methods, achieving over 4% improvement on the ImageNet-127 dataset. Our source code is available at https://github.com/zhouzihao11/CCL