 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Models are Strong Noisy Label Detectors
Sep 29, 2024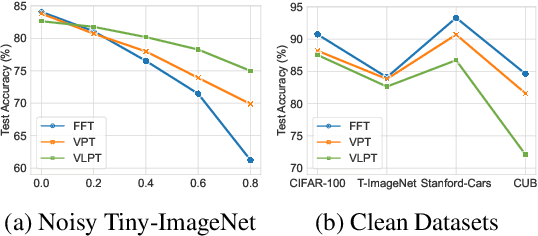



Recent research on fine-tuning vision-language models has demonstrated impressive performance in various downstream tasks. However, the challenge of obtaining accurately labeled data in real-world applications poses a significant obstacle during the fine-tuning process. To address this challenge, this paper presents a Denoising Fine-Tuning framework, called DeFT, for adapting vision-language models. DeFT utilizes the robust alignment of textual and visual features pre-trained on millions of auxiliary image-text pairs to sieve out noisy labels. The proposed framework establishes a noisy label detector by learning positive and negative textual prompts for each class. The positive prompt seeks to reveal distinctive features of the class, while the negative prompt serves as a learnable threshold for separating clean and noisy samples. We employ parameter-efficient fine-tuning for the adaptation of a pre-trained visual encoder to promote its alignment with the learned textual prompts. As a general framework, DeFT can seamlessly fine-tune many pre-trained models to downstream tasks by utilizing carefully selected clean samples. Experimental results on seven synthetic and real-world noisy datasets validate the effectiveness of DeFT in both noisy label detection and image classification.