 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperation-Guided Progressive Human-to-AI Text Transformation Benchmark for Multi-Granularity AI-Text Detection
Jun 04, 2026As AI writing assistants become increasingly integrated into real-world drafting and revision workflows, many documents are no longer purely human-written or AI-generated, but instead result from progressive human-AI co-editing. However, existing AI-text detection benchmarks largely focus on final outputs and provide limited understanding of how AI authorship signals emerge, accumulate, or disappear throughout the revision process. We introduce OpAI-Bench, an operation-guided benchmark for studying progressive human-to-AI text transformation across document, sentence, token, and span granularities. Starting from human-written documents, OpAI-Bench constructs nine sequentially revised versions for each sample under predefined AI coverage levels and five representative AI edit operations, covering four domains while preserving complete authorship provenance at multiple granularities. The benchmark supports comprehensive evaluation with 8 document-level detectors, 7 sentence-level detectors, and 2 fine-grained token/span-level detectors. Experiments reveal that AI-text detectability is governed not only by the proportion of AI-edited content, but also by edit operation, domain, and cumulative revision history. Interestingly, we notice that mixed-authorship intermediate versions are often harder to detect than both fully human and heavily AI-edited endpoints, exposing non-monotonic detection patterns missed by existing benchmarks. OpAI-Bench provides a controlled testbed for analyzing whether, when, and how AI-assisted writing becomes detectable under realistic progressive editing scenarios. Our code and benchmark are available at https://github.com/VILA-Lab/OpAI-Bench.
LLMSurgeon: Diagnosing Data Mixture of Large Language Models
May 28, 2026The pretraining data mixture of Large Language Models (LLMs) constitutes their "digital DNA", shaping model behaviors, capabilities, and failure modes. Yet this composition is rarely disclosed, making post-hoc auditing of data combination or provenance difficult. In this work, we formalize $\textbf{Data Mixture Surgery (DMS)}$: given only generated text from a target LLM, estimate the domain-level distribution of its pretraining corpus under a predefined taxonomy. We propose $\textbf{LLMSurgeon}$, a strong framework that casts DMS as an inverse problem under the label-shift assumption. Rather than directly aggregating classifier outputs, LLMSurgeon estimates a calibrated $\textit{soft}$ confusion matrix and solves a constrained inverse problem to correct systematic domain confusion and recover the latent mixture prior. To evaluate, we introduce $\textbf{LLMScan}$, a recipe-verifiable evaluation suite built from open-source LLMs with transparent pretraining mixtures. Across LLMScan, LLMSurgeon recovers domain mixtures with high fidelity under fixed protocols. Our work presents a practical, post-hoc approach for auditing the digital DNA of foundation models without access to their training data.
Covering Human Action Space for Computer Use: Data Synthesis and Benchmark
May 12, 2026Computer-use agents (CUAs) automate on-screen work, as illustrated by GPT-5.4 and Claude. Yet their reliability on complex, low-frequency interactions is still poor, limiting user trust. Our analysis of failure cases from advanced models suggests a long-tail pattern in GUI operations, where a relatively small fraction of complex and diverse interactions accounts for a disproportionate share of task failures. We hypothesize that this issue largely stems from the scarcity of data for complex interactions. To address this problem, we propose a new benchmark CUActSpot for evaluating models' capabilities on complex interactions across five modalities: GUI, text, table, canvas, and natural image, as well as a variety of actions (click, drag, draw, etc.), covering a broader range of interaction types than prior click-centric benchmarks that focus mainly on GUI widgets. We also design a renderer-based data-synthesis pipeline: scenes are automatically generated for each modality, screenshots and element coordinates are recorded, and an LLM produces matching instructions and action traces. After training on this corpus, our Phi-Ground-Any-4B outperforms open-source models with fewer than 32B parameters. We will release our benchmark, data, code, and models at https://github.com/microsoft/Phi-Ground.git
Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems
Apr 14, 2026Claude Code is an agentic coding tool that can run shell commands, edit files, and call external services on behalf of the user. This study describes its comprehensive architecture by analyzing the publicly available TypeScript source code and further comparing it with OpenClaw, an independent open-source AI agent system that answers many of the same design questions from a different deployment context. Our analysis identifies five human values, philosophies, and needs that motivate the architecture (human decision authority, safety and security, reliable execution, capability amplification, and contextual adaptability) and traces them through thirteen design principles to specific implementation choices. The core of the system is a simple while-loop that calls the model, runs tools, and repeats. Most of the code, however, lives in the systems around this loop: a permission system with seven modes and an ML-based classifier, a five-layer compaction pipeline for context management, four extensibility mechanisms (MCP, plugins, skills, and hooks), a subagent delegation mechanism with worktree isolation, and append-oriented session storage. A comparison with OpenClaw, a multi-channel personal assistant gateway, shows that the same recurring design questions produce different architectural answers when the deployment context changes: from per-action safety classification to perimeter-level access control, from a single CLI loop to an embedded runtime within a gateway control plane, and from context-window extensions to gateway-wide capability registration. We finally identify six open design directions for future agent systems, grounded in recent empirical, architectural, and policy literature.
From Masks to Pixels and Meaning: A New Taxonomy, Benchmark, and Metrics for VLM Image Tampering
Mar 20, 2026Existing tampering detection benchmarks largely rely on object masks, which severely misalign with the true edit signal: many pixels inside a mask are untouched or only trivially modified, while subtle yet consequential edits outside the mask are treated as natural. We reformulate VLM image tampering from coarse region labels to a pixel-grounded, meaning and language-aware task. First, we introduce a taxonomy spanning edit primitives (replace/remove/splice/inpaint/attribute/colorization, etc.) and their semantic class of tampered object, linking low-level changes to high-level understanding. Second, we release a new benchmark with per-pixel tamper maps and paired category supervision to evaluate detection and classification within a unified protocol. Third, we propose a training framework and evaluation metrics that quantify pixel-level correctness with localization to assess confidence or prediction on true edit intensity, and further measure tamper meaning understanding via semantics-aware classification and natural language descriptions for the predicted regions. We also re-evaluate the existing strong segmentation/localization baselines on recent strong tamper detectors and reveal substantial over- and under-scoring using mask-only metrics, and expose failure modes on micro-edits and off-mask changes. Our framework advances the field from masks to pixels, meanings and language descriptions, establishing a rigorous standard for tamper localization, semantic classification and description. Code and benchmark data are available at https://github.com/VILA-Lab/PIXAR.
Exploring 3D Dataset Pruning
Feb 28, 2026Dataset pruning has been widely studied for 2D images to remove redundancy and accelerate training, while particular pruning methods for 3D data remain largely unexplored. In this work, we study dataset pruning for 3D data, where its observed common long-tail class distribution nature make optimization under conventional evaluation metrics Overall Accuracy (OA) and Mean Accuracy (mAcc) inherently conflicting, and further make pruning particularly challenging. To address this, we formulate pruning as approximating the full-data expected risk with a weighted subset, which reveals two key errors: coverage error from insufficient representativeness and prior-mismatch bias from inconsistency between subset-induced class weights and target metrics. We propose representation-aware subset selection with per-class retention quotas for long-tail coverage, and prior-invariant teacher supervision using calibrated soft labels and embedding-geometry distillation. The retention quota also serves as a switch to control the OA-mAcc trade-off. Extensive experiments on 3D datasets show that our method can improve both metrics across multiple settings while adapting to different downstream preferences. Our code is available at https://github.com/XiaohanZhao123/3D-Dataset-Pruning.
Pushing the Frontier of Black-Box LVLM Attacks via Fine-Grained Detail Targeting
Feb 19, 2026Black-box adversarial attacks on Large Vision-Language Models (LVLMs) are challenging due to missing gradients and complex multimodal boundaries. While prior state-of-the-art transfer-based approaches like M-Attack perform well using local crop-level matching between source and target images, we find this induces high-variance, nearly orthogonal gradients across iterations, violating coherent local alignment and destabilizing optimization. We attribute this to (i) ViT translation sensitivity that yields spike-like gradients and (ii) structural asymmetry between source and target crops. We reformulate local matching as an asymmetric expectation over source transformations and target semantics, and build a gradient-denoising upgrade to M-Attack. On the source side, Multi-Crop Alignment (MCA) averages gradients from multiple independently sampled local views per iteration to reduce variance. On the target side, Auxiliary Target Alignment (ATA) replaces aggressive target augmentation with a small auxiliary set from a semantically correlated distribution, producing a smoother, lower-variance target manifold. We further reinterpret momentum as Patch Momentum, replaying historical crop gradients; combined with a refined patch-size ensemble (PE+), this strengthens transferable directions. Together these modules form M-Attack-V2, a simple, modular enhancement over M-Attack that substantially improves transfer-based black-box attacks on frontier LVLMs: boosting success rates on Claude-4.0 from 8% to 30%, Gemini-2.5-Pro from 83% to 97%, and GPT-5 from 98% to 100%, outperforming prior black-box LVLM attacks. Code and data are publicly available at: https://github.com/vila-lab/M-Attack-V2.
Next-Gen CAPTCHAs: Leveraging the Cognitive Gap for Scalable and Diverse GUI-Agent Defense
Feb 09, 2026The rapid evolution of GUI-enabled agents has rendered traditional CAPTCHAs obsolete. While previous benchmarks like OpenCaptchaWorld established a baseline for evaluating multimodal agents, recent advancements in reasoning-heavy models, such as Gemini3-Pro-High and GPT-5.2-Xhigh have effectively collapsed this security barrier, achieving pass rates as high as 90% on complex logic puzzles like "Bingo". In response, we introduce Next-Gen CAPTCHAs, a scalable defense framework designed to secure the next-generation web against the advanced agents. Unlike static datasets, our benchmark is built upon a robust data generation pipeline, allowing for large-scale and easily scalable evaluations, notably, for backend-supported types, our system is capable of generating effectively unbounded CAPTCHA instances. We exploit the persistent human-agent "Cognitive Gap" in interactive perception, memory, decision-making, and action. By engineering dynamic tasks that require adaptive intuition rather than granular planning, we re-establish a robust distinction between biological users and artificial agents, offering a scalable and diverse defense mechanism for the agentic era.
Hard Labels In! Rethinking the Role of Hard Labels in Mitigating Local Semantic Drift
Dec 22, 2025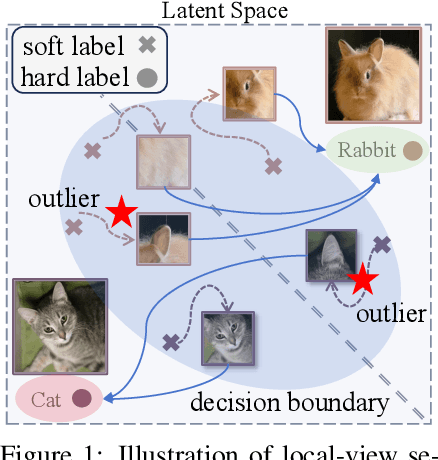
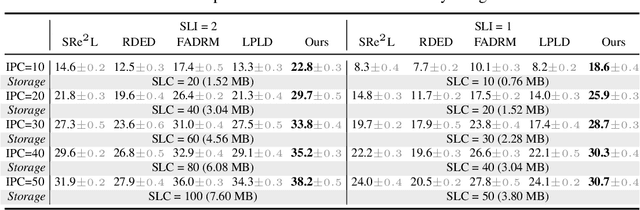
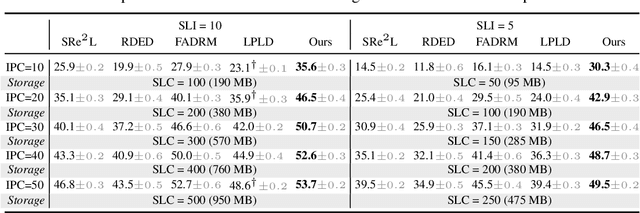
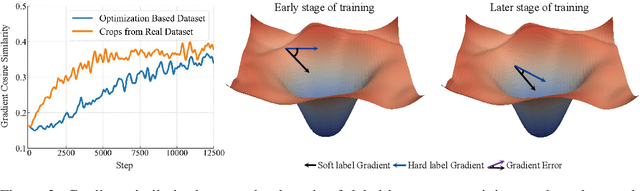
Soft labels generated by teacher models have become a dominant paradigm for knowledge transfer and recent large-scale dataset distillation such as SRe2L, RDED, LPLD, offering richer supervision than conventional hard labels. However, we observe that when only a limited number of crops per image are used, soft labels are prone to local semantic drift: a crop may visually resemble another class, causing its soft embedding to deviate from the ground-truth semantics of the original image. This mismatch between local visual content and global semantic meaning introduces systematic errors and distribution misalignment between training and testing. In this work, we revisit the overlooked role of hard labels and show that, when appropriately integrated, they provide a powerful content-agnostic anchor to calibrate semantic drift. We theoretically characterize the emergence of drift under few soft-label supervision and demonstrate that hybridizing soft and hard labels restores alignment between visual content and semantic supervision. Building on this insight, we propose a new training paradigm, Hard Label for Alleviating Local Semantic Drift (HALD), which leverages hard labels as intermediate corrective signals while retaining the fine-grained advantages of soft labels. Extensive experiments on dataset distillation and large-scale conventional classification benchmarks validate our approach, showing consistent improvements in generalization. On ImageNet-1K, we achieve 42.7% with only 285M storage for soft labels, outperforming prior state-of-the-art LPLD by 9.0%. Our findings re-establish the importance of hard labels as a complementary tool, and call for a rethinking of their role in soft-label-dominated training.
Open CaptchaWorld: A Comprehensive Web-based Platform for Testing and Benchmarking Multimodal LLM Agents
May 30, 2025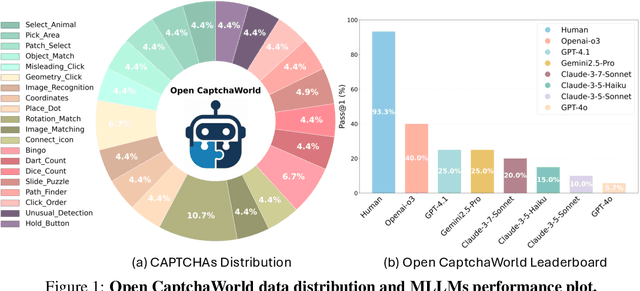
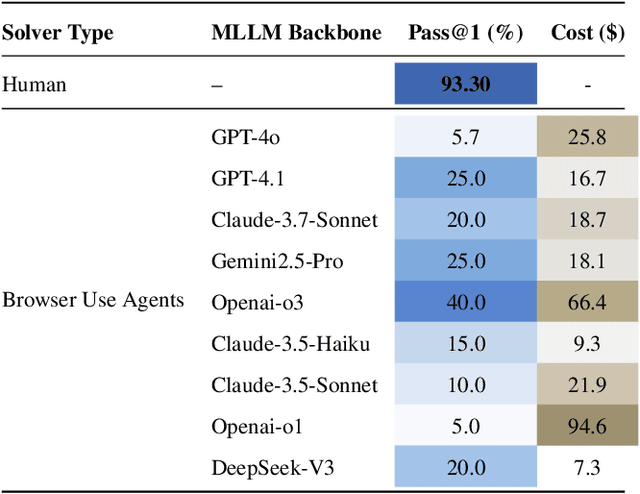

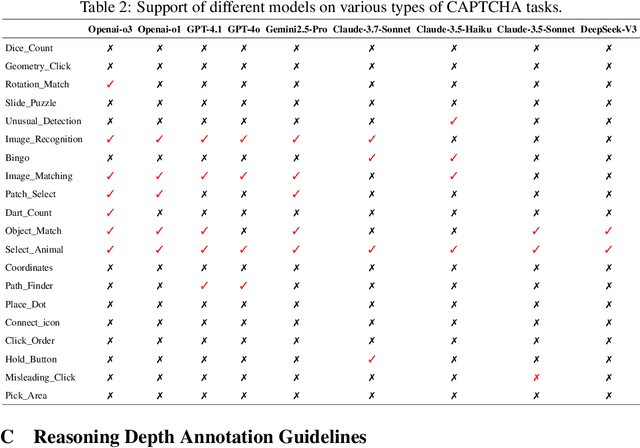
CAPTCHAs have been a critical bottleneck for deploying web agents in real-world applications, often blocking them from completing end-to-end automation tasks. While modern multimodal LLM agents have demonstrated impressive performance in static perception tasks, their ability to handle interactive, multi-step reasoning challenges like CAPTCHAs is largely untested. To address this gap, we introduce Open CaptchaWorld, the first web-based benchmark and platform specifically designed to evaluate the visual reasoning and interaction capabilities of MLLM-powered agents through diverse and dynamic CAPTCHA puzzles. Our benchmark spans 20 modern CAPTCHA types, totaling 225 CAPTCHAs, annotated with a new metric we propose: CAPTCHA Reasoning Depth, which quantifies the number of cognitive and motor steps required to solve each puzzle. Experimental results show that humans consistently achieve near-perfect scores, state-of-the-art MLLM agents struggle significantly, with success rates at most 40.0% by Browser-Use Openai-o3, far below human-level performance, 93.3%. This highlights Open CaptchaWorld as a vital benchmark for diagnosing the limits of current multimodal agents and guiding the development of more robust multimodal reasoning systems. Code and Data are available at this https URL.