 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
May 21, 2026Joint audio-visual reasoning is essential for omnimodal understanding, yet current multimodal large language models (MLLMs) still struggle when reasoning requires fine-grained evidence from both modalities. A central limitation is that explicit text-based chain-of-thought (CoT) compresses continuous audio-visual signals into discrete tokens, weakening temporal grounding and shifting intermediate reasoning toward language priors. We argue that a unified latent space is a better medium for such reasoning because it preserves dense sensory information while remaining compatible with autoregressive generation. Based on this insight, we propose \textbf{LatentOmni}, a cross-modal reasoning framework that interleaves textual reasoning with audio-visual latent states. LatentOmni introduces feature-level supervision to align latent reasoning states with task-relevant sensory features and uses Omni-Sync Position Embedding (OSPE) to maintain temporal consistency between latent audio and visual states. We further construct \textbf{LatentOmni-Instruct-35K}, a dataset of audio-visual interleaved reasoning trajectories for supervising latent-space reasoning. Comprehensive evaluation across multiple audio-visual reasoning benchmarks demonstrates that LatentOmni achieves the best performance among the evaluated open-source models and consistently outperforms the Explicit Text CoT baseline, supporting latent-space joint reasoning as a promising path toward stronger omnimodal understanding.
K12-KGraph: A Curriculum-Aligned Knowledge Graph for Benchmarking and Training Educational LLMs
May 10, 2026Large language models (LLMs) are increasingly used in K-12 education, yet existing benchmarks such as C-Eval, CMMLU, GaokaoBench, and EduEval mainly evaluate factual recall through exam-style question answering. Effective educational AI additionally requires curriculum cognition: understanding how knowledge is structured through prerequisite chains, concept taxonomies, experiment-concept links, and pedagogical sequencing. To address this gap, we introduce K12-KGraph, a curriculum-aligned knowledge graph extracted from official People's Education Press textbooks across mathematics, physics, chemistry, and biology from primary to high school. The graph contains seven node types (Concept, Skill, Experiment, Exercise, Section, Chapter, Book) and nine relation types covering taxonomy, prerequisite, association, verification, assessment, location, and order. Based on this graph, we construct two resources: (1) K12-Bench, a 23,640-question multi-select benchmark spanning five graph-derived task families (Ground, Prereq, Neighbor, Evidence, and Locate); and (2) K12-Train, a KG-guided supervised fine-tuning corpus of approximately 2,300 QA pairs synthesized from graph structure and node attributes. Experiments reveal substantial deficiencies in curriculum cognition: on K12-Bench, Gemini-3-Flash achieves only 57% exact match, while the best open-source model, Gemma-4-31B-IT, reaches 46%. Under a strictly matched 2,300-sample SFT budget on Qwen3-4B-Base and Llama-3.1-8B-Base, K12-Train consistently outperforms equally sized subsets from eight mainstream instruction-tuning corpora on both GaokaoBench and EduEval, demonstrating that curriculum-structured supervision is highly sample-efficient for educational tuning. We release the graph, benchmark, training data, and full construction pipeline.
OpenWorldLib: A Unified Codebase and Definition of Advanced World Models
Apr 06, 2026World models have garnered significant attention as a promising research direction in artificial intelligence, yet a clear and unified definition remains lacking. In this paper, we introduce OpenWorldLib, a comprehensive and standardized inference framework for Advanced World Models. Drawing on the evolution of world models, we propose a clear definition: a world model is a model or framework centered on perception, equipped with interaction and long-term memory capabilities, for understanding and predicting the complex world. We further systematically categorize the essential capabilities of world models. Based on this definition, OpenWorldLib integrates models across different tasks within a unified framework, enabling efficient reuse and collaborative inference. Finally, we present additional reflections and analyses on potential future directions for world model research. Code link: https://github.com/OpenDCAI/OpenWorldLib
DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
Mar 27, 2026Data-centric training has emerged as a promising direction for improving large language models (LLMs) by optimizing not only model parameters but also the selection, composition, and weighting of training data during optimization. However, existing approaches to data selection, data mixture optimization, and data reweighting are often developed in isolated codebases with inconsistent interfaces, hindering reproducibility, fair comparison, and practical integration. In this paper, we present DataFlex, a unified data-centric dynamic training framework built upon LLaMA-Factory. DataFlex supports three major paradigms of dynamic data optimization: sample selection, domain mixture adjustment, and sample reweighting, while remaining fully compatible with the original training workflow. It provides extensible trainer abstractions and modular components, enabling a drop-in replacement for standard LLM training, and unifies key model-dependent operations such as embedding extraction, inference, and gradient computation, with support for large-scale settings including DeepSpeed ZeRO-3. We conduct comprehensive experiments across multiple data-centric methods. Dynamic data selection consistently outperforms static full-data training on MMLU across both Mistral-7B and Llama-3.2-3B. For data mixture, DoReMi and ODM improve both MMLU accuracy and corpus-level perplexity over default proportions when pretraining Qwen2.5-1.5B on SlimPajama at 6B and 30B token scales. DataFlex also achieves consistent runtime improvements over original implementations. These results demonstrate that DataFlex provides an effective, efficient, and reproducible infrastructure for data-centric dynamic training of LLMs.
Towards Next-Generation LLM Training: From the Data-Centric Perspective
Mar 16, 2026Large language models (LLMs) have demonstrated remarkable performance across a wide range of tasks and domains, with data playing a central role in enabling these advances. Despite this success, the preparation and effective utilization of the massive datasets required for LLM training remain major bottlenecks. In current practice, LLM training data is often constructed using ad hoc scripts, and there is still a lack of mature, agent-based data preparation systems that can automatically construct robust and reusable data workflows, thereby freeing data scientists from repetitive and error-prone engineering efforts. Moreover, once collected, datasets are often consumed largely in their entirety during training, without systematic mechanisms for data selection, mixture optimization, or reweighting. To address these limitations, we advocate two complementary research directions. First, we propose building a robust, agent-based automatic data preparation system that supports automated workflow construction and scalable data management. Second, we argue for a unified data-model interaction training system in which data is dynamically selected, mixed, and reweighted throughout the training process, enabling more efficient, adaptive, and performance-aware data utilization. Finally, we discuss the remaining challenges and outline promising directions for future research and system development.
Can We Build a Monolithic Model for Fake Image Detection? SICA: Semantic-Induced Constrained Adaptation for Unified-Yet-Discriminative Artifact Feature Space Reconstruction
Feb 06, 2026Fake Image Detection (FID), aiming at unified detection across four image forensic subdomains, is critical in real-world forensic scenarios. Compared with ensemble approaches, monolithic FID models are theoretically more promising, but to date, consistently yield inferior performance in practice. In this work, by discovering the ``heterogeneous phenomenon'', which is the intrinsic distinctness of artifacts across subdomains, we diagnose the cause of this underperformance for the first time: the collapse of the artifact feature space driven by such phenomenon. The core challenge for developing a practical monolithic FID model thus boils down to the ``unified-yet-discriminative" reconstruction of the artifact feature space. To address this paradoxical challenge, we hypothesize that high-level semantics can serve as a structural prior for the reconstruction, and further propose Semantic-Induced Constrained Adaptation (SICA), the first monolithic FID paradigm. Extensive experiments on our OpenMMSec dataset demonstrate that SICA outperforms 15 state-of-the-art methods and reconstructs the target unified-yet-discriminative artifact feature space in a near-orthogonal manner, thus firmly validating our hypothesis. The code and dataset are available at:https: //github.com/scu-zjz/SICA_OpenMMSec.
Research on World Models Is Not Merely Injecting World Knowledge into Specific Tasks
Feb 02, 2026World models have emerged as a critical frontier in AI research, aiming to enhance large models by infusing them with physical dynamics and world knowledge. The core objective is to enable agents to understand, predict, and interact with complex environments. However, current research landscape remains fragmented, with approaches predominantly focused on injecting world knowledge into isolated tasks, such as visual prediction, 3D estimation, or symbol grounding, rather than establishing a unified definition or framework. While these task-specific integrations yield performance gains, they often lack the systematic coherence required for holistic world understanding. In this paper, we analyze the limitations of such fragmented approaches and propose a unified design specification for world models. We suggest that a robust world model should not be a loose collection of capabilities but a normative framework that integrally incorporates interaction, perception, symbolic reasoning, and spatial representation. This work aims to provide a structured perspective to guide future research toward more general, robust, and principled models of the world.
GIFT: Unlocking Global Optimality in Post-Training via Finite-Temperature Gibbs Initialization
Jan 14, 2026The prevailing post-training paradigm for Large Reasoning Models (LRMs)--Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL)--suffers from an intrinsic optimization mismatch: the rigid supervision inherent in SFT induces distributional collapse, thereby exhausting the exploration space necessary for subsequent RL. In this paper, we reformulate SFT within a unified post-training framework and propose Gibbs Initialization with Finite Temperature (GIFT). We characterize standard SFT as a degenerate zero-temperature limit that suppresses base priors. Conversely, GIFT incorporates supervision as a finite-temperature energy potential, establishing a distributional bridge that ensures objective consistency throughout the post-training pipeline. Our experiments demonstrate that GIFT significantly outperforms standard SFT and other competitive baselines when utilized for RL initialization, providing a mathematically principled pathway toward achieving global optimality in post-training. Our code is available at https://github.com/zzy1127/GIFT.
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
Dec 18, 2025The rapidly growing demand for high-quality data in Large Language Models (LLMs) has intensified the need for scalable, reliable, and semantically rich data preparation pipelines. However, current practices remain dominated by ad-hoc scripts and loosely specified workflows, which lack principled abstractions, hinder reproducibility, and offer limited support for model-in-the-loop data generation. To address these challenges, we present DataFlow, a unified and extensible LLM-driven data preparation framework. DataFlow is designed with system-level abstractions that enable modular, reusable, and composable data transformations, and provides a PyTorch-style pipeline construction API for building debuggable and optimizable dataflows. The framework consists of nearly 200 reusable operators and six domain-general pipelines spanning text, mathematical reasoning, code, Text-to-SQL, agentic RAG, and large-scale knowledge extraction. To further improve usability, we introduce DataFlow-Agent, which automatically translates natural-language specifications into executable pipelines via operator synthesis, pipeline planning, and iterative verification. Across six representative use cases, DataFlow consistently improves downstream LLM performance. Our math, code, and text pipelines outperform curated human datasets and specialized synthetic baselines, achieving up to +3\% execution accuracy in Text-to-SQL over SynSQL, +7\% average improvements on code benchmarks, and 1--3 point gains on MATH, GSM8K, and AIME. Moreover, a unified 10K-sample dataset produced by DataFlow enables base models to surpass counterparts trained on 1M Infinity-Instruct data. These results demonstrate that DataFlow provides a practical and high-performance substrate for reliable, reproducible, and scalable LLM data preparation, and establishes a system-level foundation for future data-centric AI development.
Scone: Bridging Composition and Distinction in Subject-Driven Image Generation via Unified Understanding-Generation Modeling
Dec 14, 2025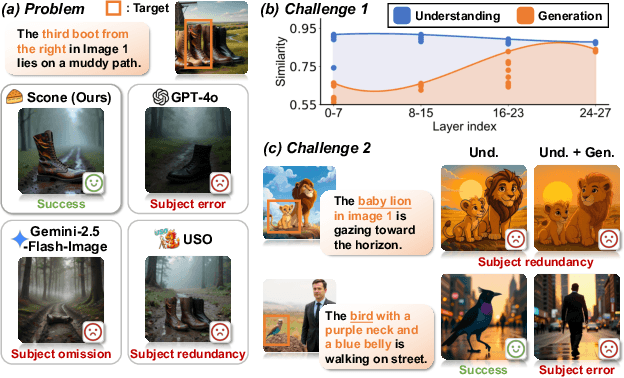

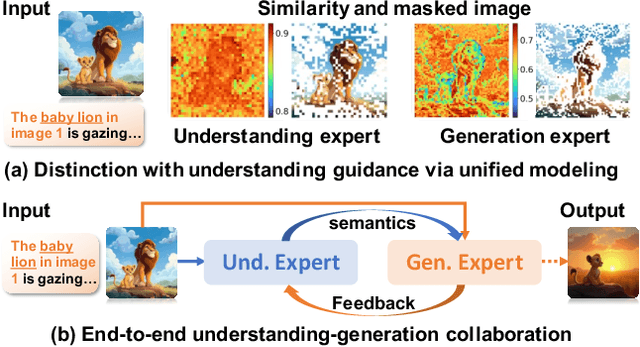
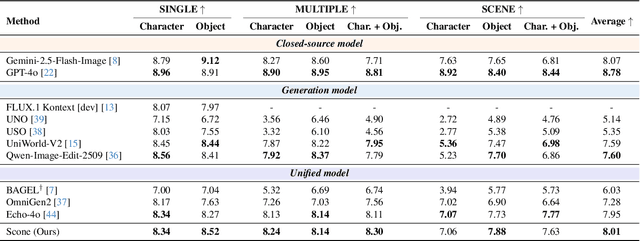
Subject-driven image generation has advanced from single- to multi-subject composition, while neglecting distinction, the ability to identify and generate the correct subject when inputs contain multiple candidates. This limitation restricts effectiveness in complex, realistic visual settings. We propose Scone, a unified understanding-generation method that integrates composition and distinction. Scone enables the understanding expert to act as a semantic bridge, conveying semantic information and guiding the generation expert to preserve subject identity while minimizing interference. A two-stage training scheme first learns composition, then enhances distinction through semantic alignment and attention-based masking. We also introduce SconeEval, a benchmark for evaluating both composition and distinction across diverse scenarios. Experiments demonstrate that Scone outperforms existing open-source models in composition and distinction tasks on two benchmarks. Our model, benchmark, and training data are available at: https://github.com/Ryann-Ran/Scone.