 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCSR: Pseudo-label Consistency-Guided Sample Refinement for Noisy Correspondence Learning
Sep 19, 2025Cross-modal retrieval aims to align different modalities via semantic similarity. However, existing methods often assume that image-text pairs are perfectly aligned, overlooking Noisy Correspondences in real data. These misaligned pairs misguide similarity learning and degrade retrieval performance. Previous methods often rely on coarse-grained categorizations that simply divide data into clean and noisy samples, overlooking the intrinsic diversity within noisy instances. Moreover, they typically apply uniform training strategies regardless of sample characteristics, resulting in suboptimal sample utilization for model optimization. To address the above challenges, we introduce a novel framework, called Pseudo-label Consistency-Guided Sample Refinement (PCSR), which enhances correspondence reliability by explicitly dividing samples based on pseudo-label consistency. Specifically, we first employ a confidence-based estimation to distinguish clean and noisy pairs, then refine the noisy pairs via pseudo-label consistency to uncover structurally distinct subsets. We further proposed a Pseudo-label Consistency Score (PCS) to quantify prediction stability, enabling the separation of ambiguous and refinable samples within noisy pairs. Accordingly, we adopt Adaptive Pair Optimization (APO), where ambiguous samples are optimized with robust loss functions and refinable ones are enhanced via text replacement during training. Extensive experiments on CC152K, MS-COCO and Flickr30K validate the effectiveness of our method in improving retrieval robustness under noisy supervision.
Aligning Information Capacity Between Vision and Language via Dense-to-Sparse Feature Distillation for Image-Text Matching
Mar 19, 2025Enabling Visual Semantic Models to effectively handle multi-view description matching has been a longstanding challenge. Existing methods typically learn a set of embeddings to find the optimal match for each view's text and compute similarity. However, the visual and text embeddings learned through these approaches have limited information capacity and are prone to interference from locally similar negative samples. To address this issue, we argue that the information capacity of embeddings is crucial and propose Dense-to-Sparse Feature Distilled Visual Semantic Embedding (D2S-VSE), which enhances the information capacity of sparse text by leveraging dense text distillation. Specifically, D2S-VSE is a two-stage framework. In the pre-training stage, we align images with dense text to enhance the information capacity of visual semantic embeddings. In the fine-tuning stage, we optimize two tasks simultaneously, distilling dense text embeddings to sparse text embeddings while aligning images and sparse texts, enhancing the information capacity of sparse text embeddings. Our proposed D2S-VSE model is extensively evaluated on the large-scale MS-COCO and Flickr30K datasets, demonstrating its superiority over recent state-of-the-art methods.
Mesoscopic Insights: Orchestrating Multi-scale & Hybrid Architecture for Image Manipulation Localization
Dec 18, 2024



The mesoscopic level serves as a bridge between the macroscopic and microscopic worlds, addressing gaps overlooked by both. Image manipulation localization (IML), a crucial technique to pursue truth from fake images, has long relied on low-level (microscopic-level) traces. However, in practice, most tampering aims to deceive the audience by altering image semantics. As a result, manipulation commonly occurs at the object level (macroscopic level), which is equally important as microscopic traces. Therefore, integrating these two levels into the mesoscopic level presents a new perspective for IML research. Inspired by this, our paper explores how to simultaneously construct mesoscopic representations of micro and macro information for IML and introduces the Mesorch architecture to orchestrate both. Specifically, this architecture i) combines Transformers and CNNs in parallel, with Transformers extracting macro information and CNNs capturing micro details, and ii) explores across different scales, assessing micro and macro information seamlessly. Additionally, based on the Mesorch architecture, the paper introduces two baseline models aimed at solving IML tasks through mesoscopic representation. Extensive experiments across four datasets have demonstrated that our models surpass the current state-of-the-art in terms of performance, computational complexity, and robustness.
Analysis and Applications of Deep Learning with Finite Samples in Full Life-Cycle Intelligence of Nuclear Power Generation
Nov 07, 2023



The advent of Industry 4.0 has precipitated the incorporation of Artificial Intelligence (AI) methods within industrial contexts, aiming to realize intelligent manufacturing, operation as well as maintenance, also known as industrial intelligence. However, intricate industrial milieus, particularly those relating to energy exploration and production, frequently encompass data characterized by long-tailed class distribution, sample imbalance, and domain shift. These attributes pose noteworthy challenges to data-centric Deep Learning (DL) techniques, crucial for the realization of industrial intelligence. The present study centers on the intricate and distinctive industrial scenarios of Nuclear Power Generation (NPG), meticulously scrutinizing the application of DL techniques under the constraints of finite data samples. Initially, the paper expounds on potential employment scenarios for AI across the full life-cycle of NPG. Subsequently, we delve into an evaluative exposition of DL's advancement, grounded in the finite sample perspective. This encompasses aspects such as small-sample learning, few-shot learning, zero-shot learning, and open-set recognition, also referring to the unique data characteristics of NPG. The paper then proceeds to present two specific case studies. The first revolves around the automatic recognition of zirconium alloy metallography, while the second pertains to open-set recognition for signal diagnosis of machinery sensors. These cases, spanning the entirety of NPG's life-cycle, are accompanied by constructive outcomes and insightful deliberations. By exploring and applying DL methodologies within the constraints of finite sample availability, this paper not only furnishes a robust technical foundation but also introduces a fresh perspective toward the secure and efficient advancement and exploitation of this advanced energy source.
Pre-training-free Image Manipulation Localization through Non-Mutually Exclusive Contrastive Learning
Sep 27, 2023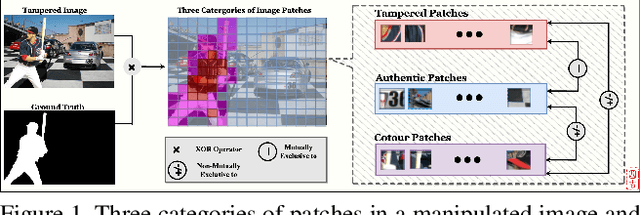

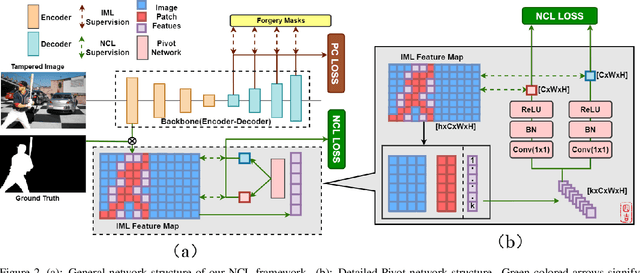

Deep Image Manipulation Localization (IML) models suffer from training data insufficiency and thus heavily rely on pre-training. We argue that contrastive learning is more suitable to tackle the data insufficiency problem for IML. Crafting mutually exclusive positives and negatives is the prerequisite for contrastive learning. However, when adopting contrastive learning in IML, we encounter three categories of image patches: tampered, authentic, and contour patches. Tampered and authentic patches are naturally mutually exclusive, but contour patches containing both tampered and authentic pixels are non-mutually exclusive to them. Simply abnegating these contour patches results in a drastic performance loss since contour patches are decisive to the learning outcomes. Hence, we propose the Non-mutually exclusive Contrastive Learning (NCL) framework to rescue conventional contrastive learning from the above dilemma. In NCL, to cope with the non-mutually exclusivity, we first establish a pivot structure with dual branches to constantly switch the role of contour patches between positives and negatives while training. Then, we devise a pivot-consistent loss to avoid spatial corruption caused by the role-switching process. In this manner, NCL both inherits the self-supervised merits to address the data insufficiency and retains a high manipulation localization accuracy. Extensive experiments verify that our NCL achieves state-of-the-art performance on all five benchmarks without any pre-training and is more robust on unseen real-life samples. The code is available at: https://github.com/Knightzjz/NCL-IML.
GPT-NAS: Neural Architecture Search with the Generative Pre-Trained Model
May 09, 2023Neural Architecture Search (NAS) has emerged as one of the effective methods to design the optimal neural network architecture automatically. Although neural architectures have achieved human-level performances in several tasks, few of them are obtained from the NAS method. The main reason is the huge search space of neural architectures, making NAS algorithms inefficient. This work presents a novel architecture search algorithm, called GPT-NAS, that optimizes neural architectures by Generative Pre-Trained (GPT) model. In GPT-NAS, we assume that a generative model pre-trained on a large-scale corpus could learn the fundamental law of building neural architectures. Therefore, GPT-NAS leverages the generative pre-trained (GPT) model to propose reasonable architecture components given the basic one. Such an approach can largely reduce the search space by introducing prior knowledge in the search process. Extensive experimental results show that our GPT-NAS method significantly outperforms seven manually designed neural architectures and thirteen architectures provided by competing NAS methods. In addition, our ablation study indicates that the proposed algorithm improves the performance of finely tuned neural architectures by up to about 12% compared to those without GPT, further demonstrating its effectiveness in searching neural architectures.
Partial Differential Equations Meet Deep Neural Networks: A Survey
Nov 18, 2022



Many problems in science and engineering can be represented by a set of partial differential equations (PDEs) through mathematical modeling. Mechanism-based computation following PDEs has long been an essential paradigm for studying topics such as computational fluid dynamics, multiphysics simulation, molecular dynamics, or even dynamical systems. It is a vibrant multi-disciplinary field of increasing importance and with extraordinary potential. At the same time, solving PDEs efficiently has been a long-standing challenge. Generally, except for a few differential equations for which analytical solutions are directly available, many more equations must rely on numerical approaches such as the finite difference method, finite element method, finite volume method, and boundary element method to be solved approximately. These numerical methods usually divide a continuous problem domain into discrete points and then concentrate on solving the system at each of those points. Though the effectiveness of these traditional numerical methods, the vast number of iterative operations accompanying each step forward significantly reduces the efficiency. Recently, another equally important paradigm, data-based computation represented by deep learning, has emerged as an effective means of solving PDEs. Surprisingly, a comprehensive review for this interesting subfield is still lacking. This survey aims to categorize and review the current progress on Deep Neural Networks (DNNs) for PDEs. We discuss the literature published in this subfield over the past decades and present them in a common taxonomy, followed by an overview and classification of applications of these related methods in scientific research and engineering scenarios. The origin, developing history, character, sort, as well as the future trends in each potential direction of this subfield are also introduced.