 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForensicHub: A Unified Benchmark & Codebase for All-Domain Fake Image Detection and Localization
May 16, 2025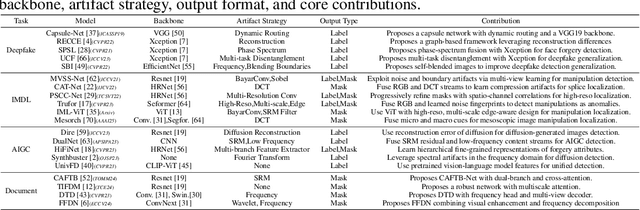
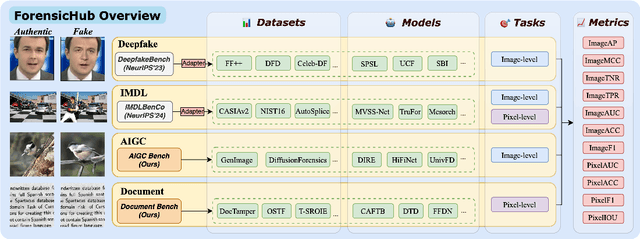
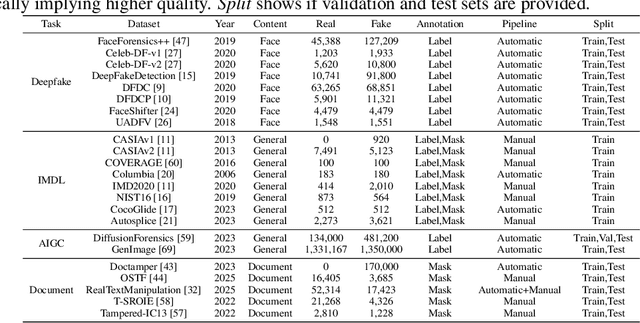
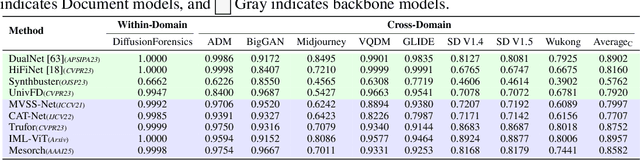
The field of Fake Image Detection and Localization (FIDL) is highly fragmented, encompassing four domains: deepfake detection (Deepfake), image manipulation detection and localization (IMDL), artificial intelligence-generated image detection (AIGC), and document image manipulation localization (Doc). Although individual benchmarks exist in some domains, a unified benchmark for all domains in FIDL remains blank. The absence of a unified benchmark results in significant domain silos, where each domain independently constructs its datasets, models, and evaluation protocols without interoperability, preventing cross-domain comparisons and hindering the development of the entire FIDL field. To close the domain silo barrier, we propose ForensicHub, the first unified benchmark & codebase for all-domain fake image detection and localization. Considering drastic variations on dataset, model, and evaluation configurations across all domains, as well as the scarcity of open-sourced baseline models and the lack of individual benchmarks in some domains, ForensicHub: i) proposes a modular and configuration-driven architecture that decomposes forensic pipelines into interchangeable components across datasets, transforms, models, and evaluators, allowing flexible composition across all domains; ii) fully implements 10 baseline models, 6 backbones, 2 new benchmarks for AIGC and Doc, and integrates 2 existing benchmarks of DeepfakeBench and IMDLBenCo through an adapter-based design; iii) conducts indepth analysis based on the ForensicHub, offering 8 key actionable insights into FIDL model architecture, dataset characteristics, and evaluation standards. ForensicHub represents a significant leap forward in breaking the domain silos in the FIDL field and inspiring future breakthroughs.
Can We Get Rid of Handcrafted Feature Extractors? SparseViT: Nonsemantics-Centered, Parameter-Efficient Image Manipulation Localization Through Spare-Coding Transformer
Dec 19, 2024
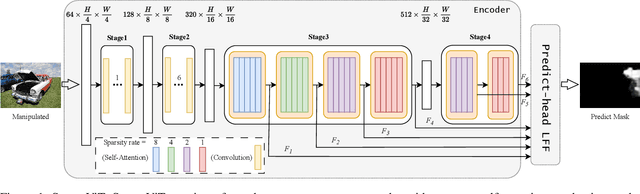
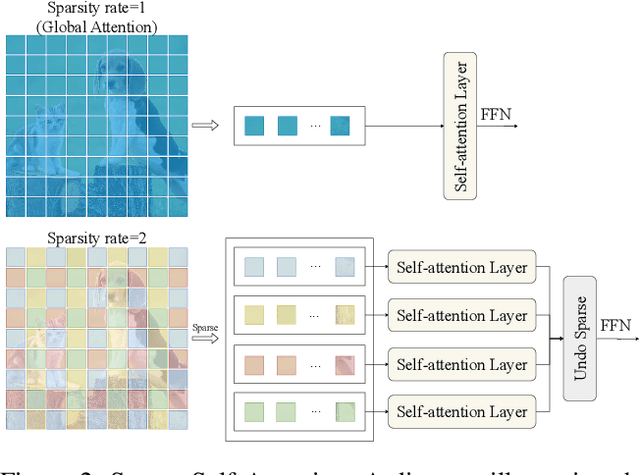
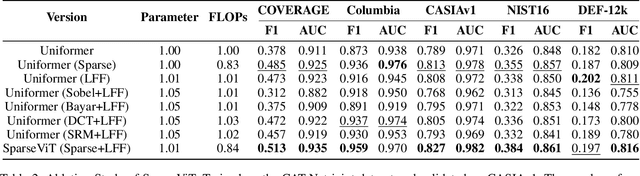
Non-semantic features or semantic-agnostic features, which are irrelevant to image context but sensitive to image manipulations, are recognized as evidential to Image Manipulation Localization (IML). Since manual labels are impossible, existing works rely on handcrafted methods to extract non-semantic features. Handcrafted non-semantic features jeopardize IML model's generalization ability in unseen or complex scenarios. Therefore, for IML, the elephant in the room is: How to adaptively extract non-semantic features? Non-semantic features are context-irrelevant and manipulation-sensitive. That is, within an image, they are consistent across patches unless manipulation occurs. Then, spare and discrete interactions among image patches are sufficient for extracting non-semantic features. However, image semantics vary drastically on different patches, requiring dense and continuous interactions among image patches for learning semantic representations. Hence, in this paper, we propose a Sparse Vision Transformer (SparseViT), which reformulates the dense, global self-attention in ViT into a sparse, discrete manner. Such sparse self-attention breaks image semantics and forces SparseViT to adaptively extract non-semantic features for images. Besides, compared with existing IML models, the sparse self-attention mechanism largely reduced the model size (max 80% in FLOPs), achieving stunning parameter efficiency and computation reduction. Extensive experiments demonstrate that, without any handcrafted feature extractors, SparseViT is superior in both generalization and efficiency across benchmark datasets.
Mesoscopic Insights: Orchestrating Multi-scale & Hybrid Architecture for Image Manipulation Localization
Dec 18, 2024



The mesoscopic level serves as a bridge between the macroscopic and microscopic worlds, addressing gaps overlooked by both. Image manipulation localization (IML), a crucial technique to pursue truth from fake images, has long relied on low-level (microscopic-level) traces. However, in practice, most tampering aims to deceive the audience by altering image semantics. As a result, manipulation commonly occurs at the object level (macroscopic level), which is equally important as microscopic traces. Therefore, integrating these two levels into the mesoscopic level presents a new perspective for IML research. Inspired by this, our paper explores how to simultaneously construct mesoscopic representations of micro and macro information for IML and introduces the Mesorch architecture to orchestrate both. Specifically, this architecture i) combines Transformers and CNNs in parallel, with Transformers extracting macro information and CNNs capturing micro details, and ii) explores across different scales, assessing micro and macro information seamlessly. Additionally, based on the Mesorch architecture, the paper introduces two baseline models aimed at solving IML tasks through mesoscopic representation. Extensive experiments across four datasets have demonstrated that our models surpass the current state-of-the-art in terms of performance, computational complexity, and robustness.
Saliency Guided Optimization of Diffusion Latents
Oct 14, 2024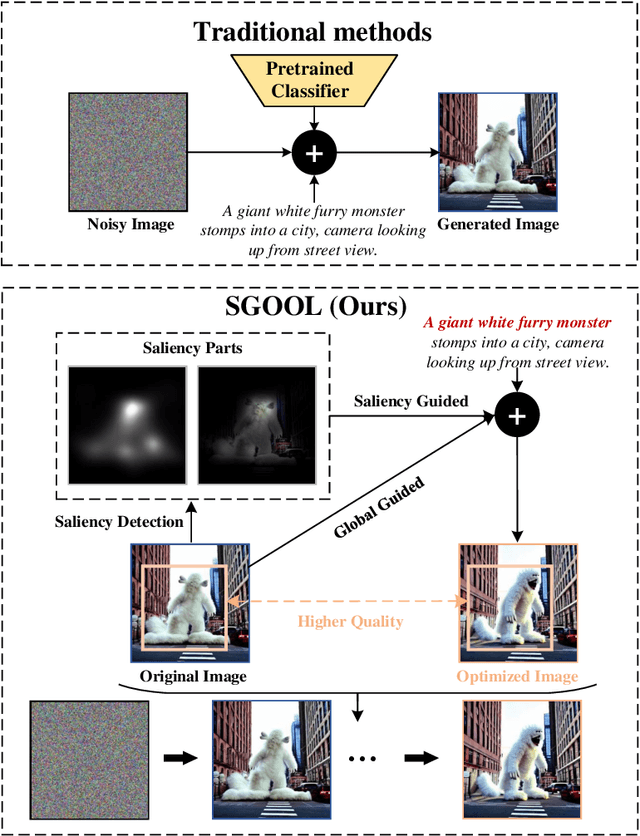

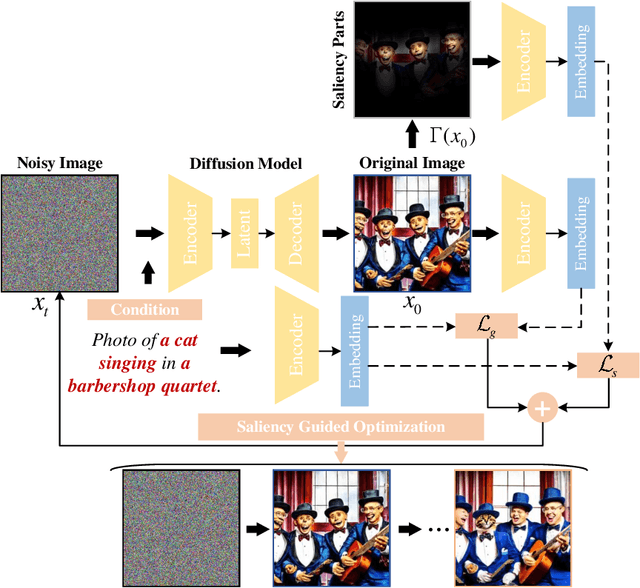
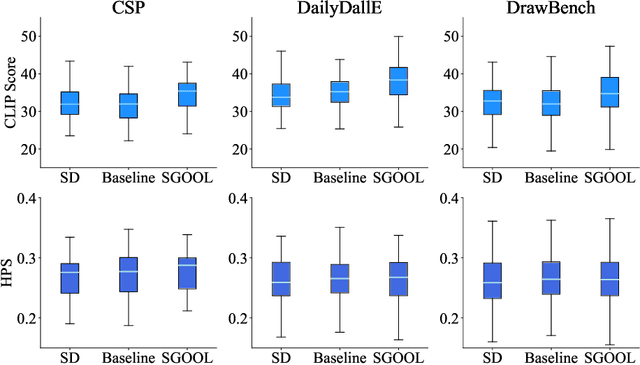
With the rapid advances in diffusion models, generating decent images from text prompts is no longer challenging. The key to text-to-image generation is how to optimize the results of a text-to-image generation model so that they can be better aligned with human intentions or prompts. Existing optimization methods commonly treat the entire image uniformly and conduct global optimization. These methods overlook the fact that when viewing an image, the human visual system naturally prioritizes attention toward salient areas, often neglecting less or non-salient regions. That is, humans are likely to neglect optimizations in non-salient areas. Consequently, although model retaining is conducted under the guidance of additional large and multimodality models, existing methods, which perform uniform optimizations, yield sub-optimal results. To address this alignment challenge effectively and efficiently, we propose Saliency Guided Optimization Of Diffusion Latents (SGOOL). We first employ a saliency detector to mimic the human visual attention system and mark out the salient regions. To avoid retraining an additional model, our method directly optimizes the diffusion latents. Besides, SGOOL utilizes an invertible diffusion process and endows it with the merits of constant memory implementation. Hence, our method becomes a parameter-efficient and plug-and-play fine-tuning method. Extensive experiments have been done with several metrics and human evaluation. Experimental results demonstrate the superiority of SGOOL in image quality and prompt alignment.
M^3:Manipulation Mask Manufacturer for Arbitrary-Scale Super-Resolution Mask
Jul 04, 2024In the field of image manipulation localization (IML), the small quantity and poor quality of existing datasets have always been major issues. A dataset containing various types of manipulations will greatly help improve the accuracy of IML models. Images on the internet (such as those on Baidu Tieba's PS Bar) are manipulated using various techniques, and creating a dataset from these images will significantly enrich the types of manipulations in our data. However, images on the internet suffer from resolution and clarity issues, and the masks obtained by simply subtracting the manipulated image from the original contain various noises. These noises are difficult to remove, rendering the masks unusable for IML models. Inspired by the field of change detection, we treat the original and manipulated images as changes over time for the same image and view the data generation task as a change detection task. However, due to clarity issues between images, conventional change detection models perform poorly. Therefore, we introduced a super-resolution module and proposed the Manipulation Mask Manufacturer (MMM) framework. It enhances the resolution of both the original and tampered images, thereby improving image details for better comparison. Simultaneously, the framework converts the original and tampered images into feature embeddings and concatenates them, effectively modeling the context. Additionally, we created the Manipulation Mask Manufacturer Dataset (MMMD), a dataset that covers a wide range of manipulation techniques. We aim to contribute to the fields of image forensics and manipulation detection by providing more realistic manipulation data through MMM and MMMD. Detailed information about MMMD and the download link can be found at: the code and datasets will be made available.
IMDL-BenCo: A Comprehensive Benchmark and Codebase for Image Manipulation Detection & Localization
Jun 15, 2024
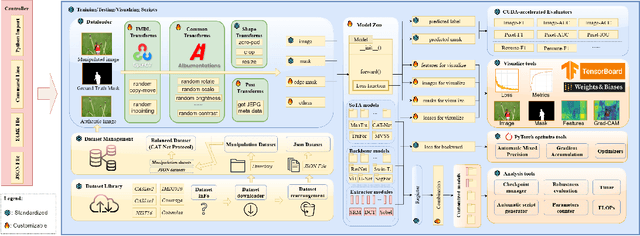
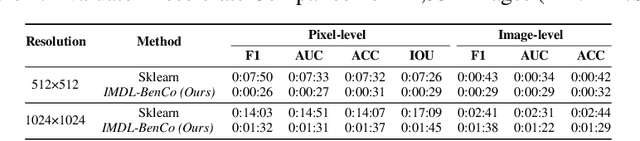

A comprehensive benchmark is yet to be established in the Image Manipulation Detection \& Localization (IMDL) field. The absence of such a benchmark leads to insufficient and misleading model evaluations, severely undermining the development of this field. However, the scarcity of open-sourced baseline models and inconsistent training and evaluation protocols make conducting rigorous experiments and faithful comparisons among IMDL models challenging. To address these challenges, we introduce IMDL-BenCo, the first comprehensive IMDL benchmark and modular codebase. IMDL-BenCo:~\textbf{i)} decomposes the IMDL framework into standardized, reusable components and revises the model construction pipeline, improving coding efficiency and customization flexibility;~\textbf{ii)} fully implements or incorporates training code for state-of-the-art models to establish a comprehensive IMDL benchmark; and~\textbf{iii)} conducts deep analysis based on the established benchmark and codebase, offering new insights into IMDL model architecture, dataset characteristics, and evaluation standards. Specifically, IMDL-BenCo includes common processing algorithms, 8 state-of-the-art IMDL models (1 of which are reproduced from scratch), 2 sets of standard training and evaluation protocols, 15 GPU-accelerated evaluation metrics, and 3 kinds of robustness evaluation. This benchmark and codebase represent a significant leap forward in calibrating the current progress in the IMDL field and inspiring future breakthroughs. Code is available at: https://github.com/scu-zjz/IMDLBenCo