 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard Labels In! Rethinking the Role of Hard Labels in Mitigating Local Semantic Drift
Dec 22, 2025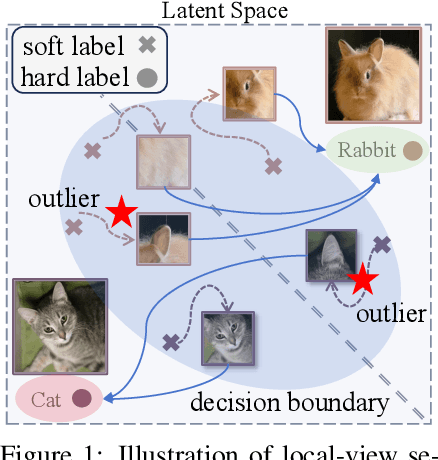
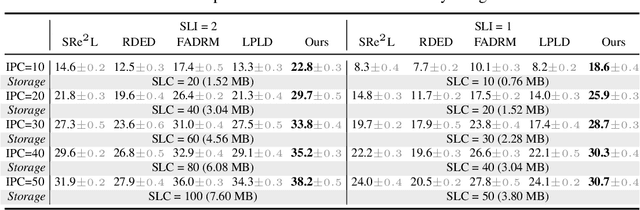
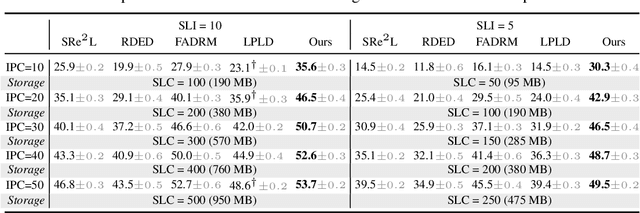
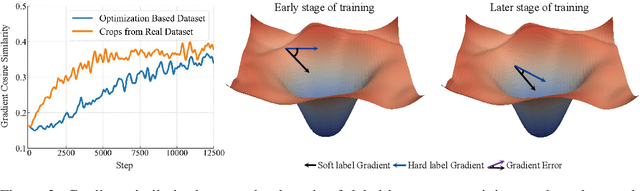
Soft labels generated by teacher models have become a dominant paradigm for knowledge transfer and recent large-scale dataset distillation such as SRe2L, RDED, LPLD, offering richer supervision than conventional hard labels. However, we observe that when only a limited number of crops per image are used, soft labels are prone to local semantic drift: a crop may visually resemble another class, causing its soft embedding to deviate from the ground-truth semantics of the original image. This mismatch between local visual content and global semantic meaning introduces systematic errors and distribution misalignment between training and testing. In this work, we revisit the overlooked role of hard labels and show that, when appropriately integrated, they provide a powerful content-agnostic anchor to calibrate semantic drift. We theoretically characterize the emergence of drift under few soft-label supervision and demonstrate that hybridizing soft and hard labels restores alignment between visual content and semantic supervision. Building on this insight, we propose a new training paradigm, Hard Label for Alleviating Local Semantic Drift (HALD), which leverages hard labels as intermediate corrective signals while retaining the fine-grained advantages of soft labels. Extensive experiments on dataset distillation and large-scale conventional classification benchmarks validate our approach, showing consistent improvements in generalization. On ImageNet-1K, we achieve 42.7% with only 285M storage for soft labels, outperforming prior state-of-the-art LPLD by 9.0%. Our findings re-establish the importance of hard labels as a complementary tool, and call for a rethinking of their role in soft-label-dominated training.
Measuring Epistemic Humility in Multimodal Large Language Models
Sep 11, 2025Hallucinations in multimodal large language models (MLLMs) -- where the model generates content inconsistent with the input image -- pose significant risks in real-world applications, from misinformation in visual question answering to unsafe errors in decision-making. Existing benchmarks primarily test recognition accuracy, i.e., evaluating whether models can select the correct answer among distractors. This overlooks an equally critical capability for trustworthy AI: recognizing when none of the provided options are correct, a behavior reflecting epistemic humility. We present HumbleBench, a new hallucination benchmark designed to evaluate MLLMs' ability to reject plausible but incorrect answers across three hallucination types: object, relation, and attribute. Built from a panoptic scene graph dataset, we leverage fine-grained scene graph annotations to extract ground-truth entities and relations, and prompt GPT-4-Turbo to generate multiple-choice questions, followed by a rigorous manual filtering process. Each question includes a "None of the above" option, requiring models not only to recognize correct visual information but also to identify when no provided answer is valid. We evaluate a variety of state-of-the-art MLLMs -- including both general-purpose and specialized reasoning models -- on HumbleBench and share valuable findings and insights with the community. By incorporating explicit false-option rejection, HumbleBench fills a key gap in current evaluation suites, providing a more realistic measure of MLLM reliability in safety-critical settings. Our code and dataset are released publicly and can be accessed at https://github.com/maifoundations/HumbleBench.
Bootstrapping Grounded Chain-of-Thought in Multimodal LLMs for Data-Efficient Model Adaptation
Jul 03, 2025Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in interpreting images using natural language. However, without using large-scale datasets for retraining, these models are difficult to adapt to specialized vision tasks, e.g., chart understanding. This problem is caused by a mismatch between pre-training and downstream datasets: pre-training datasets primarily concentrate on scenes and objects but contain limited information about specialized, non-object images, such as charts and tables. In this paper, we share an interesting finding that training an MLLM with Chain-of-Thought (CoT) reasoning data can facilitate model adaptation in specialized vision tasks, especially under data-limited regimes. However, we identify a critical issue within CoT data distilled from pre-trained MLLMs, i.e., the data often contains multiple factual errors in the reasoning steps. To address the problem, we propose Grounded Chain-of-Thought (GCoT), a simple bootstrapping-based approach that aims to inject grounding information (i.e., bounding boxes) into CoT data, essentially making the reasoning steps more faithful to input images. We evaluate our approach on five specialized vision tasks, which cover a variety of visual formats including charts, tables, receipts, and reports. The results demonstrate that under data-limited regimes our approach significantly improves upon fine-tuning and distillation.
M^3:Manipulation Mask Manufacturer for Arbitrary-Scale Super-Resolution Mask
Jul 04, 2024In the field of image manipulation localization (IML), the small quantity and poor quality of existing datasets have always been major issues. A dataset containing various types of manipulations will greatly help improve the accuracy of IML models. Images on the internet (such as those on Baidu Tieba's PS Bar) are manipulated using various techniques, and creating a dataset from these images will significantly enrich the types of manipulations in our data. However, images on the internet suffer from resolution and clarity issues, and the masks obtained by simply subtracting the manipulated image from the original contain various noises. These noises are difficult to remove, rendering the masks unusable for IML models. Inspired by the field of change detection, we treat the original and manipulated images as changes over time for the same image and view the data generation task as a change detection task. However, due to clarity issues between images, conventional change detection models perform poorly. Therefore, we introduced a super-resolution module and proposed the Manipulation Mask Manufacturer (MMM) framework. It enhances the resolution of both the original and tampered images, thereby improving image details for better comparison. Simultaneously, the framework converts the original and tampered images into feature embeddings and concatenates them, effectively modeling the context. Additionally, we created the Manipulation Mask Manufacturer Dataset (MMMD), a dataset that covers a wide range of manipulation techniques. We aim to contribute to the fields of image forensics and manipulation detection by providing more realistic manipulation data through MMM and MMMD. Detailed information about MMMD and the download link can be found at: the code and datasets will be made available.
Beyond Visual Appearances: Privacy-sensitive Objects Identification via Hybrid Graph Reasoning
Jun 18, 2024The Privacy-sensitive Object Identification (POI) task allocates bounding boxes for privacy-sensitive objects in a scene. The key to POI is settling an object's privacy class (privacy-sensitive or non-privacy-sensitive). In contrast to conventional object classes which are determined by the visual appearance of an object, one object's privacy class is derived from the scene contexts and is subject to various implicit factors beyond its visual appearance. That is, visually similar objects may be totally opposite in their privacy classes. To explicitly derive the objects' privacy class from the scene contexts, in this paper, we interpret the POI task as a visual reasoning task aimed at the privacy of each object in the scene. Following this interpretation, we propose the PrivacyGuard framework for POI. PrivacyGuard contains three stages. i) Structuring: an unstructured image is first converted into a structured, heterogeneous scene graph that embeds rich scene contexts. ii) Data Augmentation: a contextual perturbation oversampling strategy is proposed to create slightly perturbed privacy-sensitive objects in a scene graph, thereby balancing the skewed distribution of privacy classes. iii) Hybrid Graph Generation & Reasoning: the balanced, heterogeneous scene graph is then transformed into a hybrid graph by endowing it with extra "node-node" and "edge-edge" homogeneous paths. These homogeneous paths allow direct message passing between nodes or edges, thereby accelerating reasoning and facilitating the capturing of subtle context changes. Based on this hybrid graph... **For the full abstract, see the original paper.**
IMDL-BenCo: A Comprehensive Benchmark and Codebase for Image Manipulation Detection & Localization
Jun 15, 2024
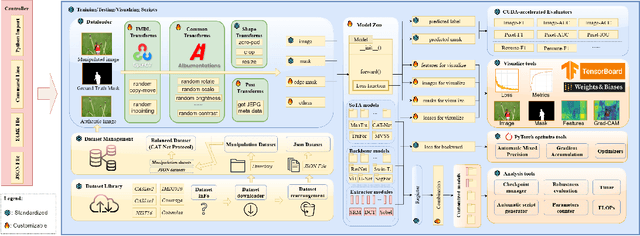
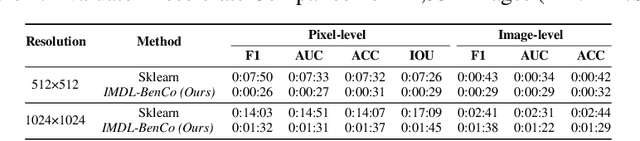

A comprehensive benchmark is yet to be established in the Image Manipulation Detection \& Localization (IMDL) field. The absence of such a benchmark leads to insufficient and misleading model evaluations, severely undermining the development of this field. However, the scarcity of open-sourced baseline models and inconsistent training and evaluation protocols make conducting rigorous experiments and faithful comparisons among IMDL models challenging. To address these challenges, we introduce IMDL-BenCo, the first comprehensive IMDL benchmark and modular codebase. IMDL-BenCo:~\textbf{i)} decomposes the IMDL framework into standardized, reusable components and revises the model construction pipeline, improving coding efficiency and customization flexibility;~\textbf{ii)} fully implements or incorporates training code for state-of-the-art models to establish a comprehensive IMDL benchmark; and~\textbf{iii)} conducts deep analysis based on the established benchmark and codebase, offering new insights into IMDL model architecture, dataset characteristics, and evaluation standards. Specifically, IMDL-BenCo includes common processing algorithms, 8 state-of-the-art IMDL models (1 of which are reproduced from scratch), 2 sets of standard training and evaluation protocols, 15 GPU-accelerated evaluation metrics, and 3 kinds of robustness evaluation. This benchmark and codebase represent a significant leap forward in calibrating the current progress in the IMDL field and inspiring future breakthroughs. Code is available at: https://github.com/scu-zjz/IMDLBenCo
SHAN: Object-Level Privacy Detection via Inference on Scene Heterogeneous Graph
Mar 14, 2024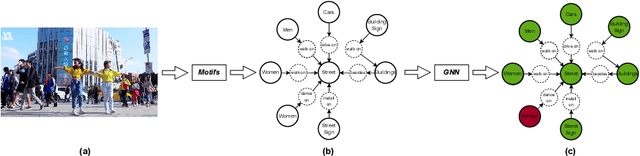
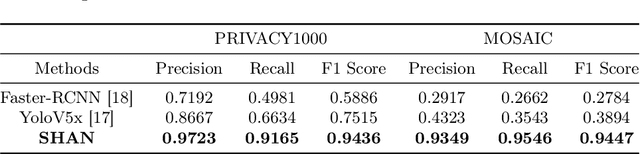

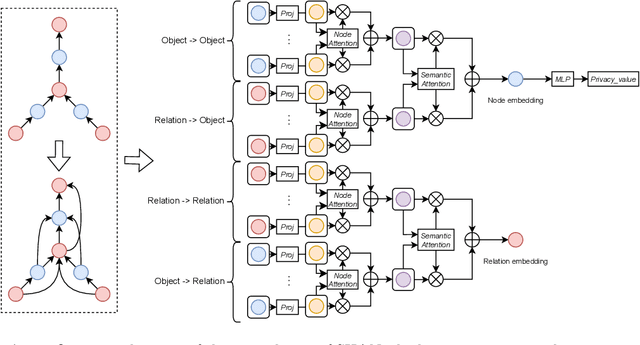
With the rise of social platforms, protecting privacy has become an important issue. Privacy object detection aims to accurately locate private objects in images. It is the foundation of safeguarding individuals' privacy rights and ensuring responsible data handling practices in the digital age. Since privacy of object is not shift-invariant, the essence of the privacy object detection task is inferring object privacy based on scene information. However, privacy object detection has long been studied as a subproblem of common object detection tasks. Therefore, existing methods suffer from serious deficiencies in accuracy, generalization, and interpretability. Moreover, creating large-scale privacy datasets is difficult due to legal constraints and existing privacy datasets lack label granularity. The granularity of existing privacy detection methods remains limited to the image level. To address the above two issues, we introduce two benchmark datasets for object-level privacy detection and propose SHAN, Scene Heterogeneous graph Attention Network, a model constructs a scene heterogeneous graph from an image and utilizes self-attention mechanisms for scene inference to obtain object privacy. Through experiments, we demonstrated that SHAN performs excellently in privacy object detection tasks, with all metrics surpassing those of the baseline model.