 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Information Fusion for Chart Understanding: A Survey of MLLMs -- Evolution, Limitations, and Cognitive Enhancement
Feb 08, 2026Chart understanding is a quintessential information fusion task, requiring the seamless integration of graphical and textual data to extract meaning. The advent of Multimodal Large Language Models (MLLMs) has revolutionized this domain, yet the landscape of MLLM-based chart analysis remains fragmented and lacks systematic organization. This survey provides a comprehensive roadmap of this nascent frontier by structuring the domain's core components. We begin by analyzing the fundamental challenges of fusing visual and linguistic information in charts. We then categorize downstream tasks and datasets, introducing a novel taxonomy of canonical and non-canonical benchmarks to highlight the field's expanding scope. Subsequently, we present a comprehensive evolution of methodologies, tracing the progression from classic deep learning techniques to state-of-the-art MLLM paradigms that leverage sophisticated fusion strategies. By critically examining the limitations of current models, particularly their perceptual and reasoning deficits, we identify promising future directions, including advanced alignment techniques and reinforcement learning for cognitive enhancement. This survey aims to equip researchers and practitioners with a structured understanding of how MLLMs are transforming chart information fusion and to catalyze progress toward more robust and reliable systems.
Adaptive Image Zoom-in with Bounding Box Transformation for UAV Object Detection
Feb 07, 2026Detecting objects from UAV-captured images is challenging due to the small object size. In this work, a simple and efficient adaptive zoom-in framework is explored for object detection on UAV images. The main motivation is that the foreground objects are generally smaller and sparser than those in common scene images, which hinders the optimization of effective object detectors. We thus aim to zoom in adaptively on the objects to better capture object features for the detection task. To achieve the goal, two core designs are required: \textcolor{black}{i) How to conduct non-uniform zooming on each image efficiently? ii) How to enable object detection training and inference with the zoomed image space?} Correspondingly, a lightweight offset prediction scheme coupled with a novel box-based zooming objective is introduced to learn non-uniform zooming on the input image. Based on the learned zooming transformation, a corner-aligned bounding box transformation method is proposed. The method warps the ground-truth bounding boxes to the zoomed space to learn object detection, and warps the predicted bounding boxes back to the original space during inference. We conduct extensive experiments on three representative UAV object detection datasets, including VisDrone, UAVDT, and SeaDronesSee. The proposed ZoomDet is architecture-independent and can be applied to an arbitrary object detection architecture. Remarkably, on the SeaDronesSee dataset, ZoomDet offers more than 8.4 absolute gain of mAP with a Faster R-CNN model, with only about 3 ms additional latency. The code is available at https://github.com/twangnh/zoomdet_code.
Deploying Models to Non-participating Clients in Federated Learning without Fine-tuning: A Hypernetwork-based Approach
Aug 18, 2025Federated Learning (FL) has emerged as a promising paradigm for privacy-preserving collaborative learning, yet data heterogeneity remains a critical challenge. While existing methods achieve progress in addressing data heterogeneity for participating clients, they fail to generalize to non-participating clients with in-domain distribution shifts and resource constraints. To mitigate this issue, we present HyperFedZero, a novel method that dynamically generates specialized models via a hypernetwork conditioned on distribution-aware embeddings. Our approach explicitly incorporates distribution-aware inductive biases into the model's forward pass, extracting robust distribution embeddings using a NoisyEmbed-enhanced extractor with a Balancing Penalty, effectively preventing feature collapse. The hypernetwork then leverages these embeddings to generate specialized models chunk-by-chunk for non-participating clients, ensuring adaptability to their unique data distributions. Extensive experiments on multiple datasets and models demonstrate HyperFedZero's remarkable performance, surpassing competing methods consistently with minimal computational, storage, and communication overhead. Moreover, ablation studies and visualizations further validate the necessity of each component, confirming meaningful adaptations and validating the effectiveness of HyperFedZero.
Dual Prompt Learning for Adapting Vision-Language Models to Downstream Image-Text Retrieval
Aug 06, 2025
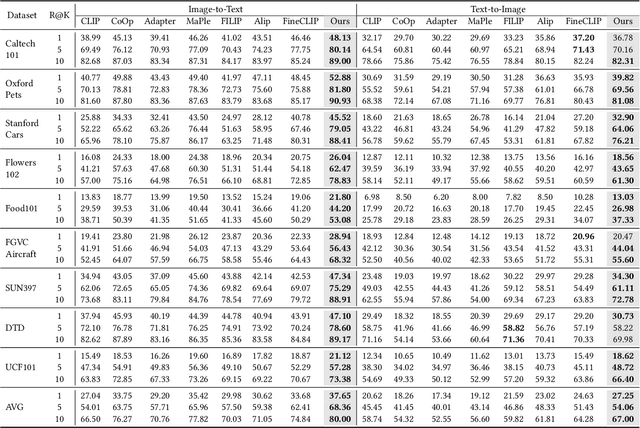
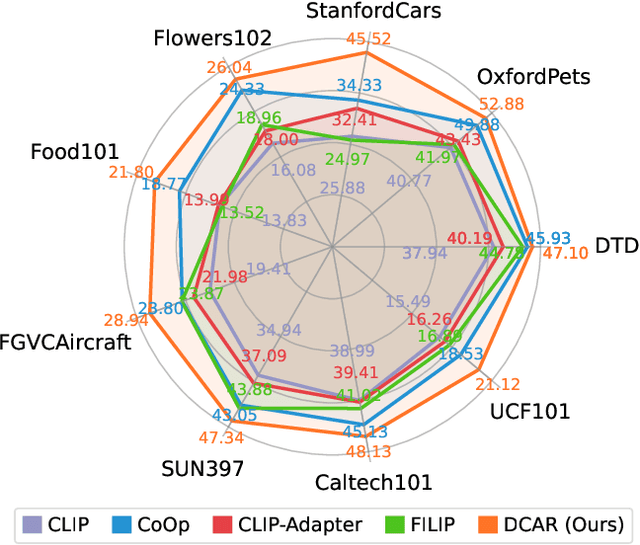
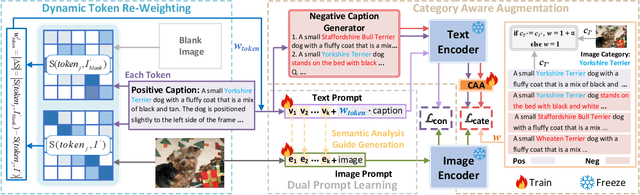
Recently, prompt learning has demonstrated remarkable success in adapting pre-trained Vision-Language Models (VLMs) to various downstream tasks such as image classification. However, its application to the downstream Image-Text Retrieval (ITR) task is more challenging. We find that the challenge lies in discriminating both fine-grained attributes and similar subcategories of the downstream data. To address this challenge, we propose Dual prompt Learning with Joint Category-Attribute Reweighting (DCAR), a novel dual-prompt learning framework to achieve precise image-text matching. The framework dynamically adjusts prompt vectors from both semantic and visual dimensions to improve the performance of CLIP on the downstream ITR task. Based on the prompt paradigm, DCAR jointly optimizes attribute and class features to enhance fine-grained representation learning. Specifically, (1) at the attribute level, it dynamically updates the weights of attribute descriptions based on text-image mutual information correlation; (2) at the category level, it introduces negative samples from multiple perspectives with category-matching weighting to learn subcategory distinctions. To validate our method, we construct the Fine-class Described Retrieval Dataset (FDRD), which serves as a challenging benchmark for ITR in downstream data domains. It covers over 1,500 downstream fine categories and 230,000 image-caption pairs with detailed attribute annotations. Extensive experiments on FDRD demonstrate that DCAR achieves state-of-the-art performance over existing baselines.
Enhancing Diffusion Model Stability for Image Restoration via Gradient Management
Jul 09, 2025

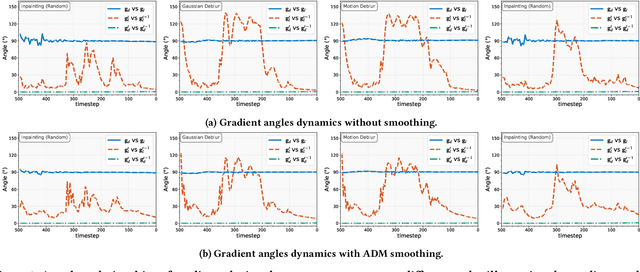

Diffusion models have shown remarkable promise for image restoration by leveraging powerful priors. Prominent methods typically frame the restoration problem within a Bayesian inference framework, which iteratively combines a denoising step with a likelihood guidance step. However, the interactions between these two components in the generation process remain underexplored. In this paper, we analyze the underlying gradient dynamics of these components and identify significant instabilities. Specifically, we demonstrate conflicts between the prior and likelihood gradient directions, alongside temporal fluctuations in the likelihood gradient itself. We show that these instabilities disrupt the generative process and compromise restoration performance. To address these issues, we propose Stabilized Progressive Gradient Diffusion (SPGD), a novel gradient management technique. SPGD integrates two synergistic components: (1) a progressive likelihood warm-up strategy to mitigate gradient conflicts; and (2) adaptive directional momentum (ADM) smoothing to reduce fluctuations in the likelihood gradient. Extensive experiments across diverse restoration tasks demonstrate that SPGD significantly enhances generation stability, leading to state-of-the-art performance in quantitative metrics and visually superior results. Code is available at \href{https://github.com/74587887/SPGD}{here}.
GigaVideo-1: Advancing Video Generation via Automatic Feedback with 4 GPU-Hours Fine-Tuning
Jun 12, 2025
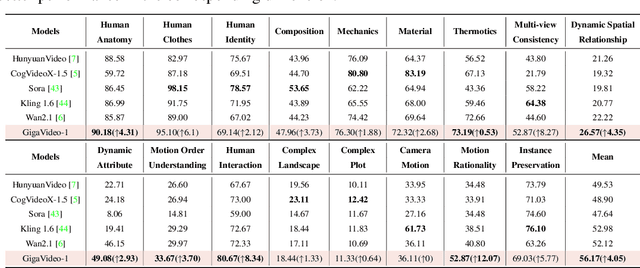
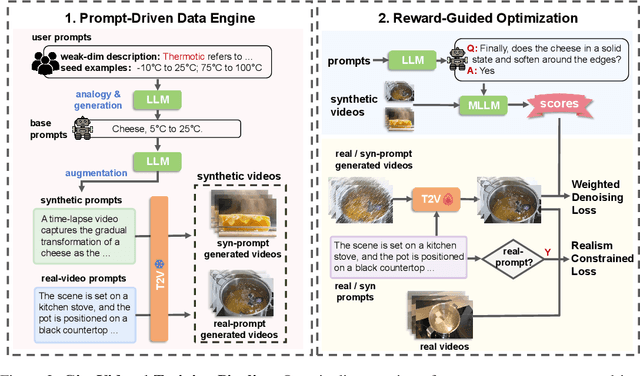

Recent progress in diffusion models has greatly enhanced video generation quality, yet these models still require fine-tuning to improve specific dimensions like instance preservation, motion rationality, composition, and physical plausibility. Existing fine-tuning approaches often rely on human annotations and large-scale computational resources, limiting their practicality. In this work, we propose GigaVideo-1, an efficient fine-tuning framework that advances video generation without additional human supervision. Rather than injecting large volumes of high-quality data from external sources, GigaVideo-1 unlocks the latent potential of pre-trained video diffusion models through automatic feedback. Specifically, we focus on two key aspects of the fine-tuning process: data and optimization. To improve fine-tuning data, we design a prompt-driven data engine that constructs diverse, weakness-oriented training samples. On the optimization side, we introduce a reward-guided training strategy, which adaptively weights samples using feedback from pre-trained vision-language models with a realism constraint. We evaluate GigaVideo-1 on the VBench-2.0 benchmark using Wan2.1 as the baseline across 17 evaluation dimensions. Experiments show that GigaVideo-1 consistently improves performance on almost all the dimensions with an average gain of about 4% using only 4 GPU-hours. Requiring no manual annotations and minimal real data, GigaVideo-1 demonstrates both effectiveness and efficiency. Code, model, and data will be publicly available.
Scientists' First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning
Jun 12, 2025Scientific discoveries increasingly rely on complex multimodal reasoning based on information-intensive scientific data and domain-specific expertise. Empowered by expert-level scientific benchmarks, scientific Multimodal Large Language Models (MLLMs) hold the potential to significantly enhance this discovery process in realistic workflows. However, current scientific benchmarks mostly focus on evaluating the knowledge understanding capabilities of MLLMs, leading to an inadequate assessment of their perception and reasoning abilities. To address this gap, we present the Scientists' First Exam (SFE) benchmark, designed to evaluate the scientific cognitive capacities of MLLMs through three interconnected levels: scientific signal perception, scientific attribute understanding, scientific comparative reasoning. Specifically, SFE comprises 830 expert-verified VQA pairs across three question types, spanning 66 multimodal tasks across five high-value disciplines. Extensive experiments reveal that current state-of-the-art GPT-o3 and InternVL-3 achieve only 34.08% and 26.52% on SFE, highlighting significant room for MLLMs to improve in scientific realms. We hope the insights obtained in SFE will facilitate further developments in AI-enhanced scientific discoveries.
Can Large Language Models Understand Internet Buzzwords Through User-Generated Content
May 21, 2025The massive user-generated content (UGC) available in Chinese social media is giving rise to the possibility of studying internet buzzwords. In this paper, we study if large language models (LLMs) can generate accurate definitions for these buzzwords based on UGC as examples. Our work serves a threefold contribution. First, we introduce CHEER, the first dataset of Chinese internet buzzwords, each annotated with a definition and relevant UGC. Second, we propose a novel method, called RESS, to effectively steer the comprehending process of LLMs to produce more accurate buzzword definitions, mirroring the skills of human language learning. Third, with CHEER, we benchmark the strengths and weaknesses of various off-the-shelf definition generation methods and our RESS. Our benchmark demonstrates the effectiveness of RESS while revealing crucial shared challenges: over-reliance on prior exposure, underdeveloped inferential abilities, and difficulty identifying high-quality UGC to facilitate comprehension. We believe our work lays the groundwork for future advancements in LLM-based definition generation. Our dataset and code are available at https://github.com/SCUNLP/Buzzword.
DD-Ranking: Rethinking the Evaluation of Dataset Distillation
May 19, 2025



In recent years, dataset distillation has provided a reliable solution for data compression, where models trained on the resulting smaller synthetic datasets achieve performance comparable to those trained on the original datasets. To further improve the performance of synthetic datasets, various training pipelines and optimization objectives have been proposed, greatly advancing the field of dataset distillation. Recent decoupled dataset distillation methods introduce soft labels and stronger data augmentation during the post-evaluation phase and scale dataset distillation up to larger datasets (e.g., ImageNet-1K). However, this raises a question: Is accuracy still a reliable metric to fairly evaluate dataset distillation methods? Our empirical findings suggest that the performance improvements of these methods often stem from additional techniques rather than the inherent quality of the images themselves, with even randomly sampled images achieving superior results. Such misaligned evaluation settings severely hinder the development of DD. Therefore, we propose DD-Ranking, a unified evaluation framework, along with new general evaluation metrics to uncover the true performance improvements achieved by different methods. By refocusing on the actual information enhancement of distilled datasets, DD-Ranking provides a more comprehensive and fair evaluation standard for future research advancements.
Precision Neural Network Quantization via Learnable Adaptive Modules
Apr 24, 2025



Quantization Aware Training (QAT) is a neural network quantization technique that compresses model size and improves operational efficiency while effectively maintaining model performance. The paradigm of QAT is to introduce fake quantization operators during the training process, allowing the model to autonomously compensate for information loss caused by quantization. Making quantization parameters trainable can significantly improve the performance of QAT, but at the cost of compromising the flexibility during inference, especially when dealing with activation values with substantially different distributions. In this paper, we propose an effective learnable adaptive neural network quantization method, called Adaptive Step Size Quantization (ASQ), to resolve this conflict. Specifically, the proposed ASQ method first dynamically adjusts quantization scaling factors through a trained module capable of accommodating different activations. Then, to address the rigid resolution issue inherent in Power of Two (POT) quantization, we propose an efficient non-uniform quantization scheme. We utilize the Power Of Square root of Two (POST) as the basis for exponential quantization, effectively handling the bell-shaped distribution of neural network weights across various bit-widths while maintaining computational efficiency through a Look-Up Table method (LUT). Extensive experimental results demonstrate that the proposed ASQ method is superior to the state-of-the-art QAT approaches. Notably that the ASQ is even competitive compared to full precision baselines, with its 4-bit quantized ResNet34 model improving accuracy by 1.2\% on ImageNet.