 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Prompt Learning for Adapting Vision-Language Models to Downstream Image-Text Retrieval
Aug 06, 2025
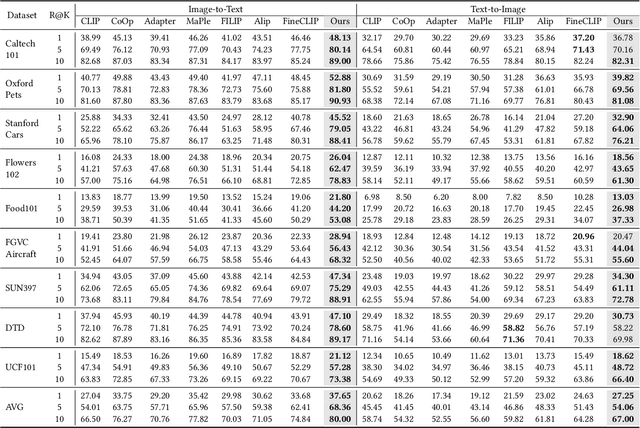
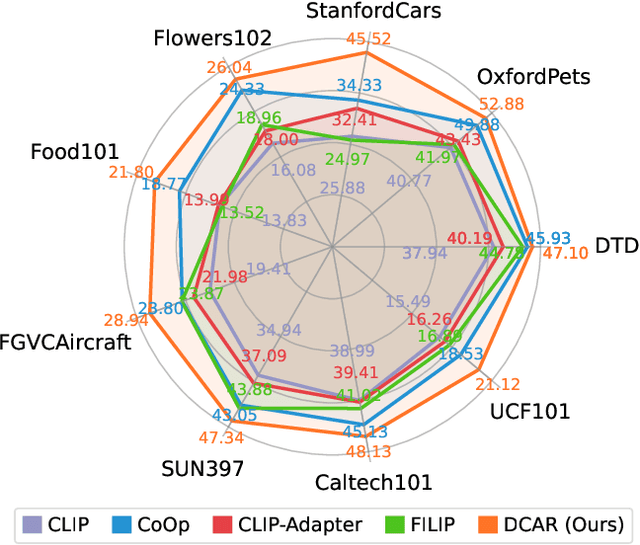
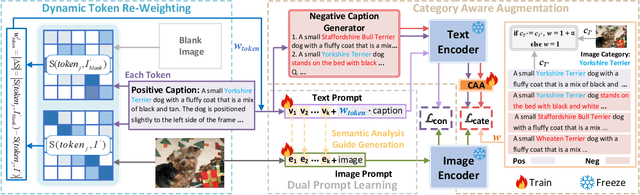
Recently, prompt learning has demonstrated remarkable success in adapting pre-trained Vision-Language Models (VLMs) to various downstream tasks such as image classification. However, its application to the downstream Image-Text Retrieval (ITR) task is more challenging. We find that the challenge lies in discriminating both fine-grained attributes and similar subcategories of the downstream data. To address this challenge, we propose Dual prompt Learning with Joint Category-Attribute Reweighting (DCAR), a novel dual-prompt learning framework to achieve precise image-text matching. The framework dynamically adjusts prompt vectors from both semantic and visual dimensions to improve the performance of CLIP on the downstream ITR task. Based on the prompt paradigm, DCAR jointly optimizes attribute and class features to enhance fine-grained representation learning. Specifically, (1) at the attribute level, it dynamically updates the weights of attribute descriptions based on text-image mutual information correlation; (2) at the category level, it introduces negative samples from multiple perspectives with category-matching weighting to learn subcategory distinctions. To validate our method, we construct the Fine-class Described Retrieval Dataset (FDRD), which serves as a challenging benchmark for ITR in downstream data domains. It covers over 1,500 downstream fine categories and 230,000 image-caption pairs with detailed attribute annotations. Extensive experiments on FDRD demonstrate that DCAR achieves state-of-the-art performance over existing baselines.
Precision Neural Network Quantization via Learnable Adaptive Modules
Apr 24, 2025Quantization Aware Training (QAT) is a neural network quantization technique that compresses model size and improves operational efficiency while effectively maintaining model performance. The paradigm of QAT is to introduce fake quantization operators during the training process, allowing the model to autonomously compensate for information loss caused by quantization. Making quantization parameters trainable can significantly improve the performance of QAT, but at the cost of compromising the flexibility during inference, especially when dealing with activation values with substantially different distributions. In this paper, we propose an effective learnable adaptive neural network quantization method, called Adaptive Step Size Quantization (ASQ), to resolve this conflict. Specifically, the proposed ASQ method first dynamically adjusts quantization scaling factors through a trained module capable of accommodating different activations. Then, to address the rigid resolution issue inherent in Power of Two (POT) quantization, we propose an efficient non-uniform quantization scheme. We utilize the Power Of Square root of Two (POST) as the basis for exponential quantization, effectively handling the bell-shaped distribution of neural network weights across various bit-widths while maintaining computational efficiency through a Look-Up Table method (LUT). Extensive experimental results demonstrate that the proposed ASQ method is superior to the state-of-the-art QAT approaches. Notably that the ASQ is even competitive compared to full precision baselines, with its 4-bit quantized ResNet34 model improving accuracy by 1.2\% on ImageNet.
SaENeRF: Suppressing Artifacts in Event-based Neural Radiance Fields
Apr 23, 2025Event cameras are neuromorphic vision sensors that asynchronously capture changes in logarithmic brightness changes, offering significant advantages such as low latency, low power consumption, low bandwidth, and high dynamic range. While these characteristics make them ideal for high-speed scenarios, reconstructing geometrically consistent and photometrically accurate 3D representations from event data remains fundamentally challenging. Current event-based Neural Radiance Fields (NeRF) methods partially address these challenges but suffer from persistent artifacts caused by aggressive network learning in early stages and the inherent noise of event cameras. To overcome these limitations, we present SaENeRF, a novel self-supervised framework that effectively suppresses artifacts and enables 3D-consistent, dense, and photorealistic NeRF reconstruction of static scenes solely from event streams. Our approach normalizes predicted radiance variations based on accumulated event polarities, facilitating progressive and rapid learning for scene representation construction. Additionally, we introduce regularization losses specifically designed to suppress artifacts in regions where photometric changes fall below the event threshold and simultaneously enhance the light intensity difference of non-zero events, thereby improving the visual fidelity of the reconstructed scene. Extensive qualitative and quantitative experiments demonstrate that our method significantly reduces artifacts and achieves superior reconstruction quality compared to existing methods. The code is available at https://github.com/Mr-firework/SaENeRF.
Memory-Augmented Dual-Decoder Networks for Multi-Class Unsupervised Anomaly Detection
Apr 21, 2025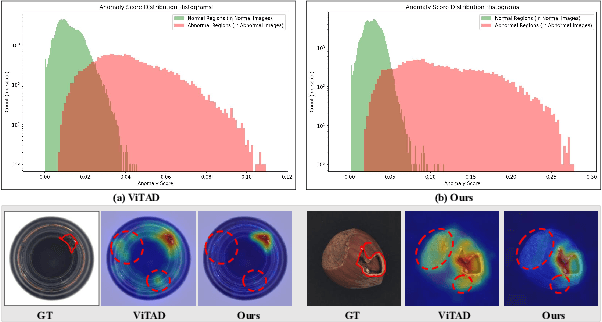
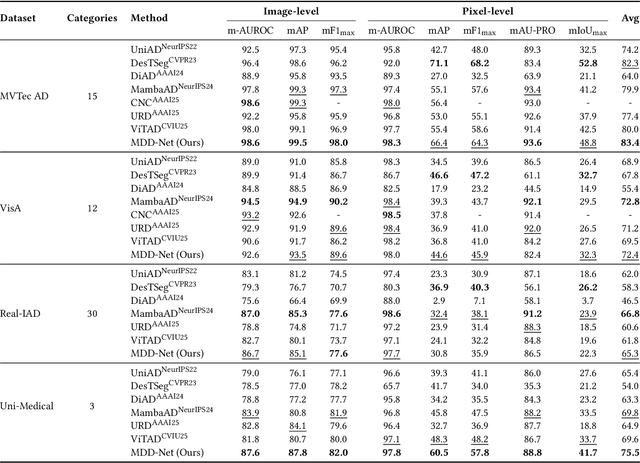
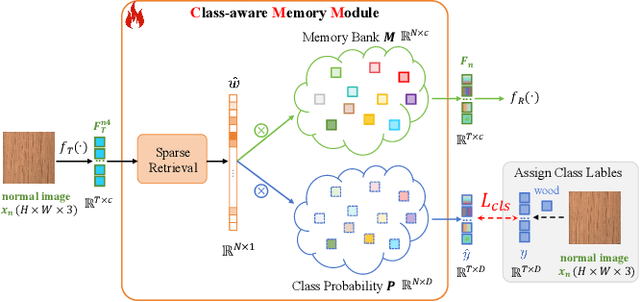
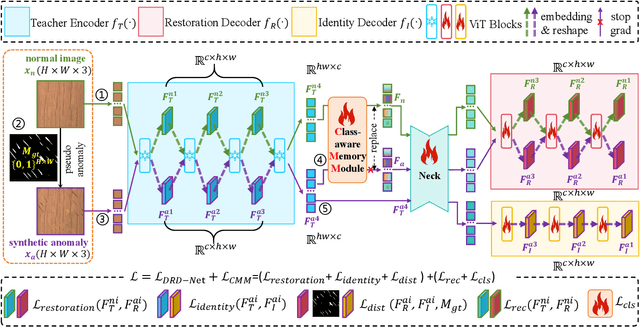
Recent advances in unsupervised anomaly detection (UAD) have shifted from single-class to multi-class scenarios. In such complex contexts, the increasing pattern diversity has brought two challenges to reconstruction-based approaches: (1) over-generalization: anomalies that are subtle or share compositional similarities with normal patterns may be reconstructed with high fidelity, making them difficult to distinguish from normal instances; and (2) insufficient normality reconstruction: complex normal features, such as intricate textures or fine-grained structures, may not be faithfully reconstructed due to the model's limited representational capacity, resulting in false positives. Existing methods typically focus on addressing the former, which unintentionally exacerbate the latter, resulting in inadequate representation of intricate normal patterns. To concurrently address these two challenges, we propose a Memory-augmented Dual-Decoder Networks (MDD-Net). This network includes two critical components: a Dual-Decoder Reverse Distillation Network (DRD-Net) and a Class-aware Memory Module (CMM). Specifically, the DRD-Net incorporates a restoration decoder designed to recover normal features from synthetic abnormal inputs and an identity decoder to reconstruct features that maintain the anomalous semantics. By exploiting the discrepancy between features produced by two decoders, our approach refines anomaly scores beyond the conventional encoder-decoder comparison paradigm, effectively reducing false positives and enhancing localization accuracy. Furthermore, the CMM explicitly encodes and preserves class-specific normal prototypes, actively steering the network away from anomaly reconstruction. Comprehensive experimental results across several benchmarks demonstrate the superior performance of our MDD-Net framework over current SoTA approaches in multi-class UAD tasks.
EBAD-Gaussian: Event-driven Bundle Adjusted Deblur Gaussian Splatting
Apr 14, 2025While 3D Gaussian Splatting (3D-GS) achieves photorealistic novel view synthesis, its performance degrades with motion blur. In scenarios with rapid motion or low-light conditions, existing RGB-based deblurring methods struggle to model camera pose and radiance changes during exposure, reducing reconstruction accuracy. Event cameras, capturing continuous brightness changes during exposure, can effectively assist in modeling motion blur and improving reconstruction quality. Therefore, we propose Event-driven Bundle Adjusted Deblur Gaussian Splatting (EBAD-Gaussian), which reconstructs sharp 3D Gaussians from event streams and severely blurred images. This method jointly learns the parameters of these Gaussians while recovering camera motion trajectories during exposure time. Specifically, we first construct a blur loss function by synthesizing multiple latent sharp images during the exposure time, minimizing the difference between real and synthesized blurred images. Then we use event stream to supervise the light intensity changes between latent sharp images at any time within the exposure period, supplementing the light intensity dynamic changes lost in RGB images. Furthermore, we optimize the latent sharp images at intermediate exposure times based on the event-based double integral (EDI) prior, applying consistency constraints to enhance the details and texture information of the reconstructed images. Extensive experiments on synthetic and real-world datasets show that EBAD-Gaussian can achieve high-quality 3D scene reconstruction under the condition of blurred images and event stream inputs.
Zero-Shot Aerial Object Detection with Visual Description Regularization
Mar 01, 2024



Existing object detection models are mainly trained on large-scale labeled datasets. However, annotating data for novel aerial object classes is expensive since it is time-consuming and may require expert knowledge. Thus, it is desirable to study label-efficient object detection methods on aerial images. In this work, we propose a zero-shot method for aerial object detection named visual Description Regularization, or DescReg. Concretely, we identify the weak semantic-visual correlation of the aerial objects and aim to address the challenge with prior descriptions of their visual appearance. Instead of directly encoding the descriptions into class embedding space which suffers from the representation gap problem, we propose to infuse the prior inter-class visual similarity conveyed in the descriptions into the embedding learning. The infusion process is accomplished with a newly designed similarity-aware triplet loss which incorporates structured regularization on the representation space. We conduct extensive experiments with three challenging aerial object detection datasets, including DIOR, xView, and DOTA. The results demonstrate that DescReg significantly outperforms the state-of-the-art ZSD methods with complex projection designs and generative frameworks, e.g., DescReg outperforms best reported ZSD method on DIOR by 4.5 mAP on unseen classes and 8.1 in HM. We further show the generalizability of DescReg by integrating it into generative ZSD methods as well as varying the detection architecture.
Analysis and Applications of Deep Learning with Finite Samples in Full Life-Cycle Intelligence of Nuclear Power Generation
Nov 07, 2023



The advent of Industry 4.0 has precipitated the incorporation of Artificial Intelligence (AI) methods within industrial contexts, aiming to realize intelligent manufacturing, operation as well as maintenance, also known as industrial intelligence. However, intricate industrial milieus, particularly those relating to energy exploration and production, frequently encompass data characterized by long-tailed class distribution, sample imbalance, and domain shift. These attributes pose noteworthy challenges to data-centric Deep Learning (DL) techniques, crucial for the realization of industrial intelligence. The present study centers on the intricate and distinctive industrial scenarios of Nuclear Power Generation (NPG), meticulously scrutinizing the application of DL techniques under the constraints of finite data samples. Initially, the paper expounds on potential employment scenarios for AI across the full life-cycle of NPG. Subsequently, we delve into an evaluative exposition of DL's advancement, grounded in the finite sample perspective. This encompasses aspects such as small-sample learning, few-shot learning, zero-shot learning, and open-set recognition, also referring to the unique data characteristics of NPG. The paper then proceeds to present two specific case studies. The first revolves around the automatic recognition of zirconium alloy metallography, while the second pertains to open-set recognition for signal diagnosis of machinery sensors. These cases, spanning the entirety of NPG's life-cycle, are accompanied by constructive outcomes and insightful deliberations. By exploring and applying DL methodologies within the constraints of finite sample availability, this paper not only furnishes a robust technical foundation but also introduces a fresh perspective toward the secure and efficient advancement and exploitation of this advanced energy source.
VCL Challenges 2023 at ICCV 2023 Technical Report: Bi-level Adaptation Method for Test-time Adaptive Object Detection
Oct 13, 2023This report outlines our team's participation in VCL Challenges B Continual Test_time Adaptation, focusing on the technical details of our approach. Our primary focus is Testtime Adaptation using bi_level adaptations, encompassing image_level and detector_level adaptations. At the image level, we employ adjustable parameterbased image filters, while at the detector level, we leverage adjustable parameterbased mean teacher modules. Ultimately, through the utilization of these bi_level adaptations, we have achieved a remarkable 38.3% mAP on the target domain of the test set within VCL Challenges B. It is worth noting that the minimal drop in mAP, is mearly 4.2%, and the overall performance is 32.5% mAP.
Attribute Localization and Revision Network for Zero-Shot Learning
Oct 11, 2023Zero-shot learning enables the model to recognize unseen categories with the aid of auxiliary semantic information such as attributes. Current works proposed to detect attributes from local image regions and align extracted features with class-level semantics. In this paper, we find that the choice between local and global features is not a zero-sum game, global features can also contribute to the understanding of attributes. In addition, aligning attribute features with class-level semantics ignores potential intra-class attribute variation. To mitigate these disadvantages, we present Attribute Localization and Revision Network in this paper. First, we design Attribute Localization Module (ALM) to capture both local and global features from image regions, a novel module called Scale Control Unit is incorporated to fuse global and local representations. Second, we propose Attribute Revision Module (ARM), which generates image-level semantics by revising the ground-truth value of each attribute, compensating for performance degradation caused by ignoring intra-class variation. Finally, the output of ALM will be aligned with revised semantics produced by ARM to achieve the training process. Comprehensive experimental results on three widely used benchmarks demonstrate the effectiveness of our model in the zero-shot prediction task.
GPT-NAS: Neural Architecture Search with the Generative Pre-Trained Model
May 09, 2023Neural Architecture Search (NAS) has emerged as one of the effective methods to design the optimal neural network architecture automatically. Although neural architectures have achieved human-level performances in several tasks, few of them are obtained from the NAS method. The main reason is the huge search space of neural architectures, making NAS algorithms inefficient. This work presents a novel architecture search algorithm, called GPT-NAS, that optimizes neural architectures by Generative Pre-Trained (GPT) model. In GPT-NAS, we assume that a generative model pre-trained on a large-scale corpus could learn the fundamental law of building neural architectures. Therefore, GPT-NAS leverages the generative pre-trained (GPT) model to propose reasonable architecture components given the basic one. Such an approach can largely reduce the search space by introducing prior knowledge in the search process. Extensive experimental results show that our GPT-NAS method significantly outperforms seven manually designed neural architectures and thirteen architectures provided by competing NAS methods. In addition, our ablation study indicates that the proposed algorithm improves the performance of finely tuned neural architectures by up to about 12% compared to those without GPT, further demonstrating its effectiveness in searching neural architectures.