 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neuromorphic Reinforcement Learning Framework for Efficient Pathfinding in Robotic Mobile Fulfillment Systems
Jun 18, 2026Dynamic environmental changes, confined workspaces, and stringent real-time constraints make pathfinding in Robotic Mobile Fulfillment Systems (RMFS) a challenging problem for conventional search- and rule-based methods, which typically suffer from high computational complexity and long decision latency. While reinforcement learning (RL) has emerged as a powerful alternative, deploying learned policies with extreme energy efficiency on resource-constrained hardware remains an open challenge. We present SDQN-RMFS, an end-to-end framework that achieves high-fidelity deployment of an RL-trained policy from a full-precision artificial neural network (ANN) through to a neuromorphic chip. By computing only when triggered by sparse events, this framework unlocks ultra-low-power RMFS pathfinding. Our full-stack pipeline operates as follows: an ANN policy is first efficiently trained via a collision-allowing strategy to densify informative trajectories, and then converted into a spiking neural network (SNN) via a hard-label knowledge distillation approach. This effectively addresses the output distribution mismatch, preserving policy capability across the ANN-to-SNN pipeline while substantially reducing inference latency. Hardware experiments demonstrate up to 11,281$\times$ energy savings and a nearly two-fold reduction in latency compared to a high-performance GPU baseline, while maintaining decision quality on par with the original trained policy. These results establish physical neuromorphic inference as a practical and energy-sustainable pathway for large-scale RMFS operations.
What Limits Vision-and-Language Navigation ?
May 13, 2026Vision-and-Language Navigation (VLN) is a cornerstone of embodied intelligence. However, current agents often suffer from significant performance degradation when transitioning from simulation to real-world deployment, primarily due to perceptual instability (e.g., lighting variations and motion blur) and under-specified instructions. While existing methods attempt to bridge this gap by scaling up model size and training data, we argue that the bottleneck lies in the lack of robust spatial grounding and cross-domain priors. In this paper, we propose StereoNav, a robust Vision-Language-Action framework designed to enhance real-world navigation consistency. To address the inherent gap between synthetic training and physical execution, we introduce Target-Location Priors as a persistent bridge. These priors provide stable visual guidance that remains invariant across domains, effectively grounding the agent even when instructions are vague. Furthermore, to mitigate visual disturbances like motion blur and illumination shifts, StereoNav leverages stereo vision to construct a unified representation of semantics and geometry, enabling precise action prediction through enhanced depth awareness. Extensive experiments on R2R-CE and RxR-CE demonstrate that StereoNav achieves state-of-the-art egocentric RGB performance, with SR and SPL scores of 81.1% and 68.3%, and 67.5% and 52.0%, respectively, while using significantly fewer parameters and less training data than prior scaling-based approaches. More importantly, real-world robotic deployments confirm that StereoNav substantially improves navigation reliability in complex, unstructured environments. Project page: https://yunheng-wang.github.io/stereonav-public.github.io.
DexFormer: Cross-Embodied Dexterous Manipulation via History-Conditioned Transformer
Feb 09, 2026Dexterous manipulation remains one of the most challenging problems in robotics, requiring coherent control of high-DoF hands and arms under complex, contact-rich dynamics. A major barrier is embodiment variability: different dexterous hands exhibit distinct kinematics and dynamics, forcing prior methods to train separate policies or rely on shared action spaces with per-embodiment decoder heads. We present DexFormer, an end-to-end, dynamics-aware cross-embodiment policy built on a modified transformer backbone that conditions on historical observations. By using temporal context to infer morphology and dynamics on the fly, DexFormer adapts to diverse hand configurations and produces embodiment-appropriate control actions. Trained over a variety of procedurally generated dexterous-hand assets, DexFormer acquires a generalizable manipulation prior and exhibits strong zero-shot transfer to Leap Hand, Allegro Hand, and Rapid Hand. Our results show that a single policy can generalize across heterogeneous hand embodiments, establishing a scalable foundation for cross-embodiment dexterous manipulation. Project website: https://davidlxu.github.io/DexFormer-web/.
TBAC-UniImage: Unified Understanding and Generation by Ladder-Side Diffusion Tuning
Aug 11, 2025This paper introduces TBAC-UniImage, a novel unified model for multimodal understanding and generation. We achieve this by deeply integrating a pre-trained Diffusion Model, acting as a generative ladder, with a Multimodal Large Language Model (MLLM). Previous diffusion-based unified models face two primary limitations. One approach uses only the MLLM's final hidden state as the generative condition. This creates a shallow connection, as the generator is isolated from the rich, hierarchical representations within the MLLM's intermediate layers. The other approach, pretraining a unified generative architecture from scratch, is computationally expensive and prohibitive for many researchers. To overcome these issues, our work explores a new paradigm. Instead of relying on a single output, we use representations from multiple, diverse layers of the MLLM as generative conditions for the diffusion model. This method treats the pre-trained generator as a ladder, receiving guidance from various depths of the MLLM's understanding process. Consequently, TBAC-UniImage achieves a much deeper and more fine-grained unification of understanding and generation.
Simple Semantic-Aided Few-Shot Learning
Nov 30, 2023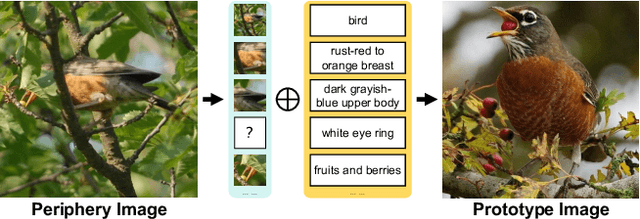
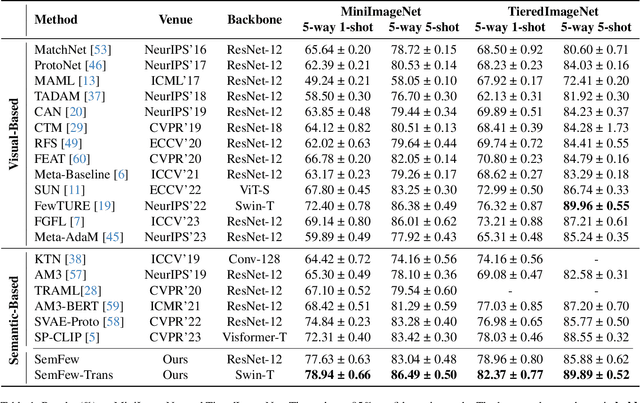
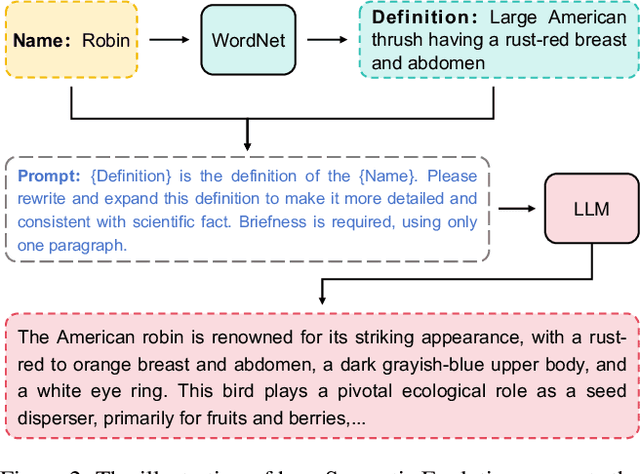
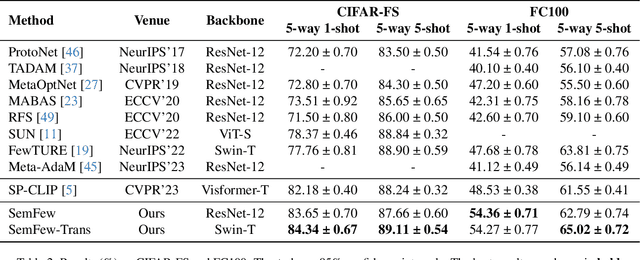
Learning from a limited amount of data, namely Few-Shot Learning, stands out as a challenging computer vision task. Several works exploit semantics and design complicated semantic fusion mechanisms to compensate for rare representative features within restricted data. However, relying on naive semantics such as class names introduces biases due to their brevity, while acquiring extensive semantics from external knowledge takes a huge time and effort. This limitation severely constrains the potential of semantics in few-shot learning. In this paper, we design an automatic way called Semantic Evolution to generate high-quality semantics. The incorporation of high-quality semantics alleviates the need for complex network structures and learning algorithms used in previous works. Hence, we employ a simple two-layer network termed Semantic Alignment Network to transform semantics and visual features into robust class prototypes with rich discriminative features for few-shot classification. The experimental results show our framework outperforms all previous methods on five benchmarks, demonstrating a simple network with high-quality semantics can beat intricate multi-modal modules on few-shot classification tasks.
Attribute Localization and Revision Network for Zero-Shot Learning
Oct 11, 2023



Zero-shot learning enables the model to recognize unseen categories with the aid of auxiliary semantic information such as attributes. Current works proposed to detect attributes from local image regions and align extracted features with class-level semantics. In this paper, we find that the choice between local and global features is not a zero-sum game, global features can also contribute to the understanding of attributes. In addition, aligning attribute features with class-level semantics ignores potential intra-class attribute variation. To mitigate these disadvantages, we present Attribute Localization and Revision Network in this paper. First, we design Attribute Localization Module (ALM) to capture both local and global features from image regions, a novel module called Scale Control Unit is incorporated to fuse global and local representations. Second, we propose Attribute Revision Module (ARM), which generates image-level semantics by revising the ground-truth value of each attribute, compensating for performance degradation caused by ignoring intra-class variation. Finally, the output of ALM will be aligned with revised semantics produced by ARM to achieve the training process. Comprehensive experimental results on three widely used benchmarks demonstrate the effectiveness of our model in the zero-shot prediction task.