 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Video Generation Propels Real-World Beyond-the-View Vision-Language Navigation
Feb 05, 2026Why must vision-language navigation be bound to detailed and verbose language instructions? While such details ease decision-making, they fundamentally contradict the goal for navigation in the real-world. Ideally, agents should possess the autonomy to navigate in unknown environments guided solely by simple and high-level intents. Realizing this ambition introduces a formidable challenge: Beyond-the-View Navigation (BVN), where agents must locate distant, unseen targets without dense and step-by-step guidance. Existing large language model (LLM)-based methods, though adept at following dense instructions, often suffer from short-sighted behaviors due to their reliance on short-horimzon supervision. Simply extending the supervision horizon, however, destabilizes LLM training. In this work, we identify that video generation models inherently benefit from long-horizon supervision to align with language instructions, rendering them uniquely suitable for BVN tasks. Capitalizing on this insight, we propose introducing the video generation model into this field for the first time. Yet, the prohibitive latency for generating videos spanning tens of seconds makes real-world deployment impractical. To bridge this gap, we propose SparseVideoNav, achieving sub-second trajectory inference guided by a generated sparse future spanning a 20-second horizon. This yields a remarkable 27x speed-up compared to the unoptimized counterpart. Extensive real-world zero-shot experiments demonstrate that SparseVideoNav achieves 2.5x the success rate of state-of-the-art LLM baselines on BVN tasks and marks the first realization of such capability in challenging night scenes.
Learning Geometrically-Grounded 3D Visual Representations for View-Generalizable Robotic Manipulation
Jan 30, 2026Real-world robotic manipulation demands visuomotor policies capable of robust spatial scene understanding and strong generalization across diverse camera viewpoints. While recent advances in 3D-aware visual representations have shown promise, they still suffer from several key limitations, including reliance on multi-view observations during inference which is impractical in single-view restricted scenarios, incomplete scene modeling that fails to capture holistic and fine-grained geometric structures essential for precise manipulation, and lack of effective policy training strategies to retain and exploit the acquired 3D knowledge. To address these challenges, we present MethodName, a unified representation-policy learning framework for view-generalizable robotic manipulation. MethodName introduces a single-view 3D pretraining paradigm that leverages point cloud reconstruction and feed-forward gaussian splatting under multi-view supervision to learn holistic geometric representations. During policy learning, MethodName performs multi-step distillation to preserve the pretrained geometric understanding and effectively transfer it to manipulation skills. We conduct experiments on 12 RLBench tasks, where our approach outperforms the previous state-of-the-art method by 12.7% in average success rate. Further evaluation on six representative tasks demonstrates strong zero-shot view generalization, with success rate drops of only 22.0% and 29.7% under moderate and large viewpoint shifts respectively, whereas the state-of-the-art method suffers larger decreases of 41.6% and 51.5%.
Enhancing Differentially Private Linear Regression via Public Second-Moment
Aug 25, 2025Leveraging information from public data has become increasingly crucial in enhancing the utility of differentially private (DP) methods. Traditional DP approaches often require adding noise based solely on private data, which can significantly degrade utility. In this paper, we address this limitation in the context of the ordinary least squares estimator (OLSE) of linear regression based on sufficient statistics perturbation (SSP) under the unbounded data assumption. We propose a novel method that involves transforming private data using the public second-moment matrix to compute a transformed SSP-OLSE, whose second-moment matrix yields a better condition number and improves the OLSE accuracy and robustness. We derive theoretical error bounds about our method and the standard SSP-OLSE to the non-DP OLSE, which reveal the improved robustness and accuracy achieved by our approach. Experiments on synthetic and real-world datasets demonstrate the utility and effectiveness of our method.
KineDex: Learning Tactile-Informed Visuomotor Policies via Kinesthetic Teaching for Dexterous Manipulation
May 04, 2025
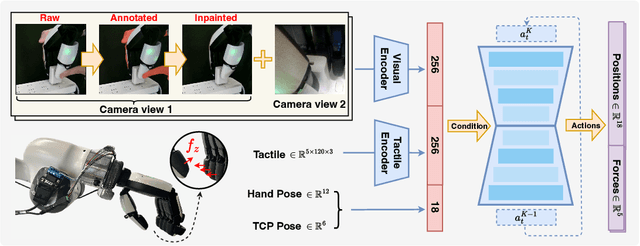


Collecting demonstrations enriched with fine-grained tactile information is critical for dexterous manipulation, particularly in contact-rich tasks that require precise force control and physical interaction. While prior works primarily focus on teleoperation or video-based retargeting, they often suffer from kinematic mismatches and the absence of real-time tactile feedback, hindering the acquisition of high-fidelity tactile data. To mitigate this issue, we propose KineDex, a hand-over-hand kinesthetic teaching paradigm in which the operator's motion is directly transferred to the dexterous hand, enabling the collection of physically grounded demonstrations enriched with accurate tactile feedback. To resolve occlusions from human hand, we apply inpainting technique to preprocess the visual observations. Based on these demonstrations, we then train a visuomotor policy using tactile-augmented inputs and implement force control during deployment for precise contact-rich manipulation. We evaluate KineDex on a suite of challenging contact-rich manipulation tasks, including particularly difficult scenarios such as squeezing toothpaste onto a toothbrush, which require precise multi-finger coordination and stable force regulation. Across these tasks, KineDex achieves an average success rate of 74.4%, representing a 57.7% improvement over the variant without force control. Comparative experiments with teleoperation and user studies further validate the advantages of KineDex in data collection efficiency and operability. Specifically, KineDex collects data over twice as fast as teleoperation across two tasks of varying difficulty, while maintaining a near-100% success rate, compared to under 50% for teleoperation.
SAM-UNet:Enhancing Zero-Shot Segmentation of SAM for Universal Medical Images
Aug 19, 2024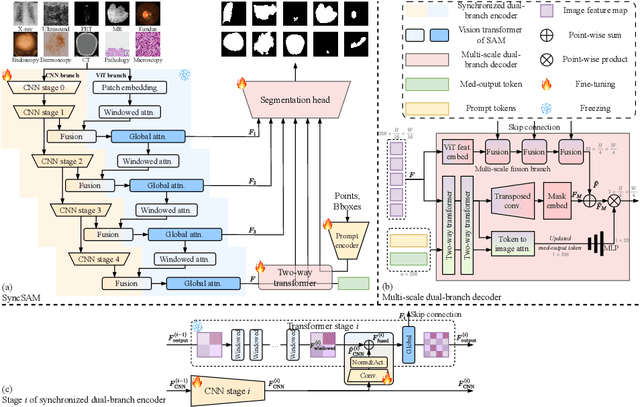
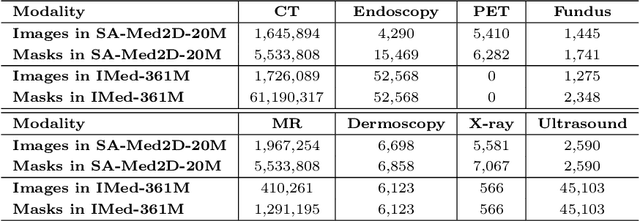
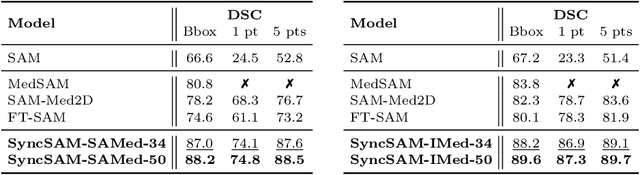
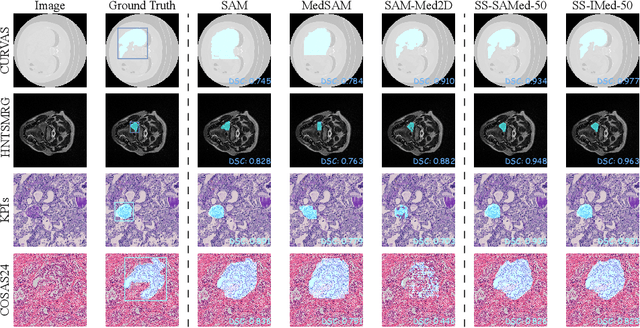
Segment Anything Model (SAM) has demonstrated impressive performance on a wide range of natural image segmentation tasks. However, its performance significantly deteriorates when directly applied to medical domain, due to the remarkable differences between natural images and medical images. Some researchers have attempted to train SAM on large scale medical datasets. However, poor zero-shot performance is observed from the experimental results. In this context, inspired by the superior performance of U-Net-like models in medical image segmentation, we propose SAMUNet, a new foundation model which incorporates U-Net to the original SAM, to fully leverage the powerful contextual modeling ability of convolutions. To be specific, we parallel a convolutional branch in the image encoder, which is trained independently with the vision Transformer branch frozen. Additionally, we employ multi-scale fusion in the mask decoder, to facilitate accurate segmentation of objects with different scales. We train SAM-UNet on SA-Med2D-16M, the largest 2-dimensional medical image segmentation dataset to date, yielding a universal pretrained model for medical images. Extensive experiments are conducted to evaluate the performance of the model, and state-of-the-art result is achieved, with a dice similarity coefficient score of 0.883 on SA-Med2D-16M dataset. Specifically, in zero-shot segmentation experiments, our model not only significantly outperforms previous large medical SAM models across all modalities, but also substantially mitigates the performance degradation seen on unseen modalities. It should be highlighted that SAM-UNet is an efficient and extensible foundation model, which can be further fine-tuned for other downstream tasks in medical community. The code is available at https://github.com/Hhankyangg/sam-unet.
Model-based Super-resolution: Towards a Unified Framework for Super-resolution
Jul 28, 2024In mathematics, a super-resolution problem can be formulated as acquiring high-frequency data from low-frequency measurements. This extrapolation problem in the frequency domain is well-known to be unstable. We propose the model-based super-resolution framework (Model-SR) to address this ill-posedness. Within this framework, we can recover the signal by solving a nonlinear least square problem and achieve the super-resolution. Theoretically, the resolution-enhancing map is proved to have Lipschitz continuity under mild conditions, leading to a stable solution to the super-resolution problem. We apply the general theory to three concrete models and give the stability estimates for each model. Numerical experiments are conducted to show the super-resolution behavior of the proposed framework. The model-based mathematical framework can be extended to problems with similar structures.
FlamePINN-1D: Physics-informed neural networks to solve forward and inverse problems of 1D laminar flames
Jun 07, 2024Given the existence of various forward and inverse problems in combustion studies and applications that necessitate distinct methods for resolution, a framework to solve them in a unified way is critically needed. A promising approach is the integration of machine learning methods with governing equations of combustion systems, which exhibits superior generality and few-shot learning ability compared to purely data-driven methods. In this work, the FlamePINN-1D framework is proposed to solve the forward and inverse problems of 1D laminar flames based on physics-informed neural networks. Three cases with increasing complexity have been tested: Case 1 are freely-propagating premixed (FPP) flames with simplified physical models, while Case 2 and Case 3 are FPP and counterflow premixed (CFP) flames with detailed models, respectively. For forward problems, FlamePINN-1D aims to solve the flame fields and infer the unknown eigenvalues (such as laminar flame speeds) under the constraints of governing equations and boundary conditions. For inverse problems, FlamePINN-1D aims to reconstruct the continuous fields and infer the unknown parameters (such as transport and chemical kinetics parameters) from noisy sparse observations of the flame. Our results strongly validate these capabilities of FlamePINN-1D across various flames and working conditions. Compared to traditional methods, FlamePINN-1D is differentiable and mesh-free, exhibits no discretization errors, and is easier to implement for inverse problems. The inverse problem results also indicate the possibility of optimizing chemical mechanisms from measurements of laboratory 1D flames. Furthermore, some proposed strategies, such as hard constraints and thin-layer normalization, are proven to be essential for the robust learning of FlamePINN-1D. The code for this paper is partially available at https://github.com/CAME-THU/FlamePINN-1D.
Scrutinize What We Ignore: Reining Task Representation Shift In Context-Based Offline Meta Reinforcement Learning
May 20, 2024



Offline meta reinforcement learning (OMRL) has emerged as a promising approach for interaction avoidance and strong generalization performance by leveraging pre-collected data and meta-learning techniques. Previous context-based approaches predominantly rely on the intuition that maximizing the mutual information between the task and the task representation ($I(Z;M)$) can lead to performance improvements. Despite achieving attractive results, the theoretical justification of performance improvement for such intuition has been lacking. Motivated by the return discrepancy scheme in the model-based RL field, we find that maximizing $I(Z;M)$ can be interpreted as consistently raising the lower bound of the expected return for a given policy conditioning on the optimal task representation. However, this optimization process ignores the task representation shift between two consecutive updates, which may lead to performance improvement collapse. To address this problem, we turn to use the framework of performance difference bound to consider the impacts of task representation shift explicitly. We demonstrate that by reining the task representation shift, it is possible to achieve monotonic performance improvements, thereby showcasing the advantage against previous approaches. To make it practical, we design an easy yet highly effective algorithm RETRO (\underline{RE}ining \underline{T}ask \underline{R}epresentation shift in context-based \underline{O}ffline meta reinforcement learning) with only adding one line of code compared to the backbone. Empirical results validate its state-of-the-art (SOTA) asymptotic performance, training stability and training-time consumption on MuJoCo and MetaWorld benchmarks.
CCTNet: A Circular Convolutional Transformer Network for LiDAR-based Place Recognition Handling Movable Objects Occlusion
May 17, 2024



Place recognition is a fundamental task for robotic application, allowing robots to perform loop closure detection within simultaneous localization and mapping (SLAM), and achieve relocalization on prior maps. Current range image-based networks use single-column convolution to maintain feature invariance to shifts in image columns caused by LiDAR viewpoint change.However, this raises the issues such as "restricted receptive fields" and "excessive focus on local regions", degrading the performance of networks. To address the aforementioned issues, we propose a lightweight circular convolutional Transformer network denoted as CCTNet, which boosts performance by capturing structural information in point clouds and facilitating crossdimensional interaction of spatial and channel information. Initially, a Circular Convolution Module (CCM) is introduced, expanding the network's perceptual field while maintaining feature consistency across varying LiDAR perspectives. Then, a Range Transformer Module (RTM) is proposed, which enhances place recognition accuracy in scenarios with movable objects by employing a combination of channel and spatial attention mechanisms. Furthermore, we propose an Overlap-based loss function, transforming the place recognition task from a binary loop closure classification into a regression problem linked to the overlap between LiDAR frames. Through extensive experiments on the KITTI and Ford Campus datasets, CCTNet surpasses comparable methods, achieving Recall@1 of 0.924 and 0.965, and Recall@1% of 0.990 and 0.993 on the test set, showcasing a superior performance. Results on the selfcollected dataset further demonstrate the proposed method's potential for practical implementation in complex scenarios to handle movable objects, showing improved generalization in various datasets.
A Fourier Approach to the Parameter Estimation Problem for One-dimensional Gaussian Mixture Models
Apr 19, 2024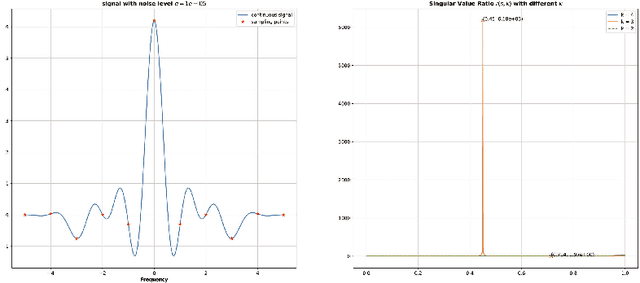
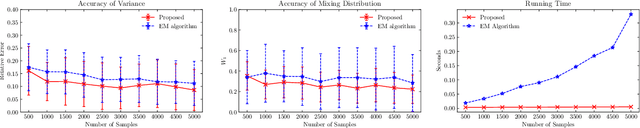

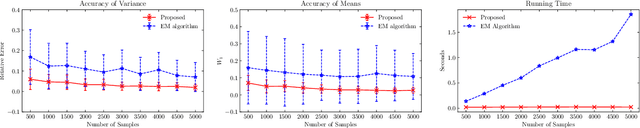
The purpose of this paper is twofold. First, we propose a novel algorithm for estimating parameters in one-dimensional Gaussian mixture models (GMMs). The algorithm takes advantage of the Hankel structure inherent in the Fourier data obtained from independent and identically distributed (i.i.d) samples of the mixture. For GMMs with a unified variance, a singular value ratio functional using the Fourier data is introduced and used to resolve the variance and component number simultaneously. The consistency of the estimator is derived. Compared to classic algorithms such as the method of moments and the maximum likelihood method, the proposed algorithm does not require prior knowledge of the number of Gaussian components or good initial guesses. Numerical experiments demonstrate its superior performance in estimation accuracy and computational cost. Second, we reveal that there exists a fundamental limit to the problem of estimating the number of Gaussian components or model order in the mixture model if the number of i.i.d samples is finite. For the case of a single variance, we show that the model order can be successfully estimated only if the minimum separation distance between the component means exceeds a certain threshold value and can fail if below. We derive a lower bound for this threshold value, referred to as the computational resolution limit, in terms of the number of i.i.d samples, the variance, and the number of Gaussian components. Numerical experiments confirm this phase transition phenomenon in estimating the model order. Moreover, we demonstrate that our algorithm achieves better scores in likelihood, AIC, and BIC when compared to the EM algorithm.