 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTGPO: Tree-Guided Preference Optimization for Robust Web Agent Reinforcement Learning
Sep 19, 2025With the rapid advancement of large language models and vision-language models, employing large models as Web Agents has become essential for automated web interaction. However, training Web Agents with reinforcement learning faces critical challenges including credit assignment misallocation, prohibitively high annotation costs, and reward sparsity. To address these issues, we propose Tree-Guided Preference Optimization (TGPO), an offline reinforcement learning framework that proposes a tree-structured trajectory representation merging semantically identical states across trajectories to eliminate label conflicts. Our framework incorporates a Process Reward Model that automatically generates fine-grained rewards through subgoal progress, redundancy detection, and action verification. Additionally, a dynamic weighting mechanism prioritizes high-impact decision points during training. Experiments on Online-Mind2Web and our self-constructed C-WebShop datasets demonstrate that TGPO significantly outperforms existing methods, achieving higher success rates with fewer redundant steps.
HyperEditor: Achieving Both Authenticity and Cross-Domain Capability in Image Editing via Hypernetworks
Dec 21, 2023Editing real images authentically while also achieving cross-domain editing remains a challenge. Recent studies have focused on converting real images into latent codes and accomplishing image editing by manipulating these codes. However, merely manipulating the latent codes would constrain the edited images to the generator's image domain, hindering the attainment of diverse editing goals. In response, we propose an innovative image editing method called HyperEditor, which utilizes weight factors generated by hypernetworks to reassign the weights of the pre-trained StyleGAN2's generator. Guided by CLIP's cross-modal image-text semantic alignment, this innovative approach enables us to simultaneously accomplish authentic attribute editing and cross-domain style transfer, a capability not realized in previous methods. Additionally, we ascertain that modifying only the weights of specific layers in the generator can yield an equivalent editing result. Therefore, we introduce an adaptive layer selector, enabling our hypernetworks to autonomously identify the layers requiring output weight factors, which can further improve our hypernetworks' efficiency. Extensive experiments on abundant challenging datasets demonstrate the effectiveness of our method.
OpenNet: Incremental Learning for Autonomous Driving Object Detection with Balanced Loss
Nov 25, 2023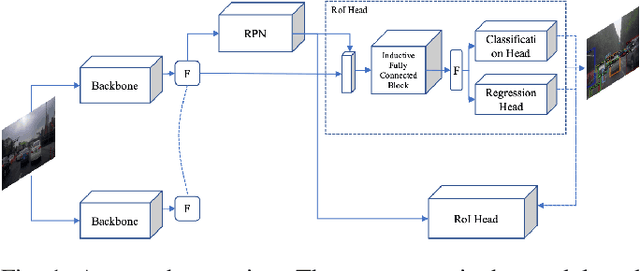

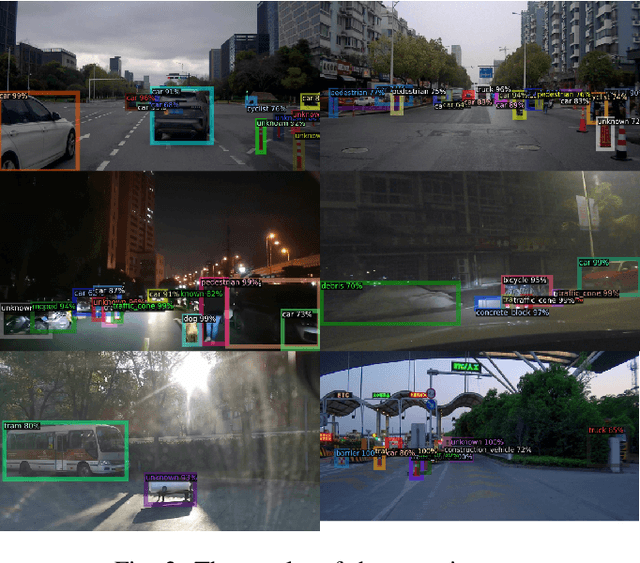

Automated driving object detection has always been a challenging task in computer vision due to environmental uncertainties. These uncertainties include significant differences in object sizes and encountering the class unseen. It may result in poor performance when traditional object detection models are directly applied to automated driving detection. Because they usually presume fixed categories of common traffic participants, such as pedestrians and cars. Worsely, the huge class imbalance between common and novel classes further exacerbates performance degradation. To address the issues stated, we propose OpenNet to moderate the class imbalance with the Balanced Loss, which is based on Cross Entropy Loss. Besides, we adopt an inductive layer based on gradient reshaping to fast learn new classes with limited samples during incremental learning. To against catastrophic forgetting, we employ normalized feature distillation. By the way, we improve multi-scale detection robustness and unknown class recognition through FPN and energy-based detection, respectively. The Experimental results upon the CODA dataset show that the proposed method can obtain better performance than that of the existing methods.
When Source-Free Domain Adaptation Meets Label Propagation
Jan 20, 2023



Source-free domain adaptation, where only a pre-trained source model is used to adapt to the target distribution, is a more general approach to achieving domain adaptation. However, it can be challenging to capture the inherent structure of the target features accurately due to the lack of supervised information on the target domain. To tackle this problem, we propose a novel approach called Adaptive Local Transfer (ALT) that tries to achieve efficient feature clustering from the perspective of label propagation. ALT divides the target data into inner and outlier samples based on the adaptive threshold of the learning state, and applies a customized learning strategy to best fits the data property. Specifically, inner samples are utilized for learning intra-class structure thanks to their relatively well-clustered properties. The low-density outlier samples are regularized by input consistency to achieve high accuracy with respect to the ground truth labels. In this way, local clustering can be prevented from forming spurious clusters while effectively propagating label information among subpopulations. Empirical evidence demonstrates that ALT outperforms the state of the arts on three public benchmarks: Office-31, Office-Home, and VisDA.
Semi-Supervised Representative Region Texture Extraction of Façade
Dec 05, 2022



Researches of analysis and parsing around fa\c{c}ades to enrich the 3D feature of fa\c{c}ade models by semantic information raised some attention in the community, whose main idea is to generate higher resolution components with similar shapes and textures to increase the overall resolution at the expense of reconstruction accuracy. While this approach works well for components like windows and doors, there is no solution for fa\c{c}ade background at present. In this paper, we introduce the concept of representative region texture, which can be used in the above modeling approach by tiling the representative texture around the fa\c{c}ade region, and propose a semi-supervised way to do representative region texture extraction from a fa\c{c}ade image. Our method does not require any additional labelled data to train as long as the semantic information is given, while a traditional end-to-end model requires plenty of data to increase its performance. Our method can extract texture from any repetitive images, not just fa\c{c}ade, which is not capable in an end-to-end model as it relies on the distribution of training set. Clustering with weighted distance is introduced to further increase the robustness to noise or an imprecise segmentation, and make the extracted texture have a higher resolution and more suitable for tiling. We verify our method on various fa\c{c}ade images, and the result shows our method has a significant performance improvement compared to only a random crop on fa\c{c}ade. We also demonstrate some application scenarios and proposed a fa\c{c}ade modeling workflow with the representative region texture, which has a better visual resolution for a regular fa\c{c}ade.