 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Adaptation: Unsupervised Domain Adaptation without Source Data
Feb 26, 2025In this paper, we investigate a challenging unsupervised domain adaptation setting -- unsupervised model adaptation. We aim to explore how to rely only on unlabeled target data to improve performance of an existing source prediction model on the target domain, since labeled source data may not be available in some real-world scenarios due to data privacy issues. For this purpose, we propose a new framework, which is referred to as collaborative class conditional generative adversarial net to bypass the dependence on the source data. Specifically, the prediction model is to be improved through generated target-style data, which provides more accurate guidance for the generator. As a result, the generator and the prediction model can collaborate with each other without source data. Furthermore, due to the lack of supervision from source data, we propose a weight constraint that encourages similarity to the source model. A clustering-based regularization is also introduced to produce more discriminative features in the target domain. Compared to conventional domain adaptation methods, our model achieves superior performance on multiple adaptation tasks with only unlabeled target data, which verifies its effectiveness in this challenging setting.
* accepted by CVPR2020
Spatial Hierarchy and Temporal Attention Guided Cross Masking for Self-supervised Skeleton-based Action Recognition
Sep 26, 2024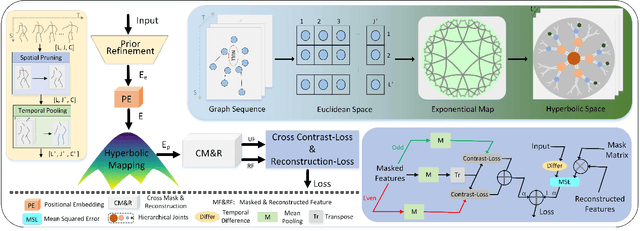
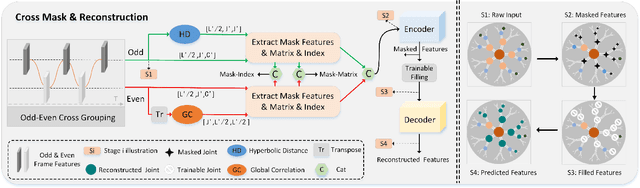
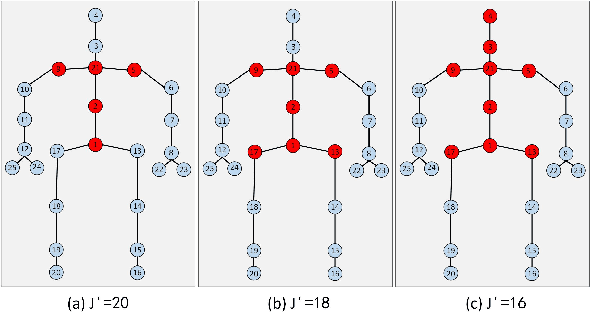
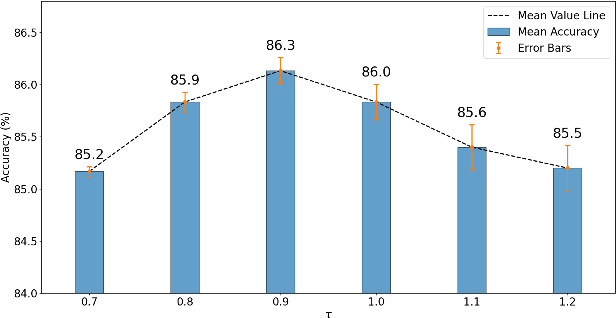
In self-supervised skeleton-based action recognition, the mask reconstruction paradigm is gaining interest in enhancing model refinement and robustness through effective masking. However, previous works primarily relied on a single masking criterion, resulting in the model overfitting specific features and overlooking other effective information. In this paper, we introduce a hierarchy and attention guided cross-masking framework (HA-CM) that applies masking to skeleton sequences from both spatial and temporal perspectives. Specifically, in spatial graphs, we utilize hyperbolic space to maintain joint distinctions and effectively preserve the hierarchical structure of high-dimensional skeletons, employing joint hierarchy as the masking criterion. In temporal flows, we substitute traditional distance metrics with the global attention of joints for masking, addressing the convergence of distances in high-dimensional space and the lack of a global perspective. Additionally, we incorporate cross-contrast loss based on the cross-masking framework into the loss function to enhance the model's learning of instance-level features. HA-CM shows efficiency and universality on three public large-scale datasets, NTU-60, NTU-120, and PKU-MMD. The source code of our HA-CM is available at https://github.com/YinxPeng/HA-CM-main.
D2Vformer: A Flexible Time Series Prediction Model Based on Time Position Embedding
Sep 17, 2024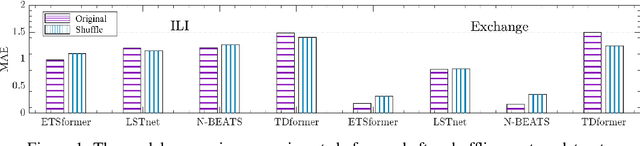
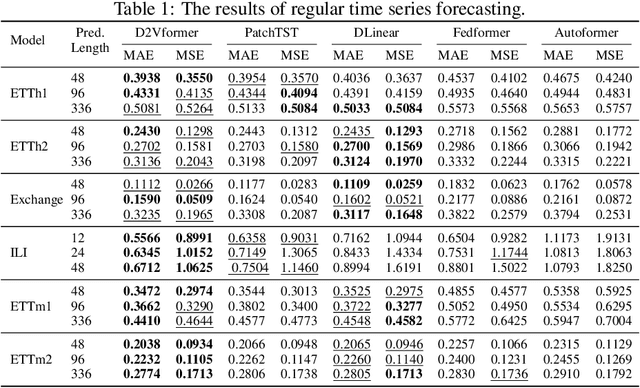

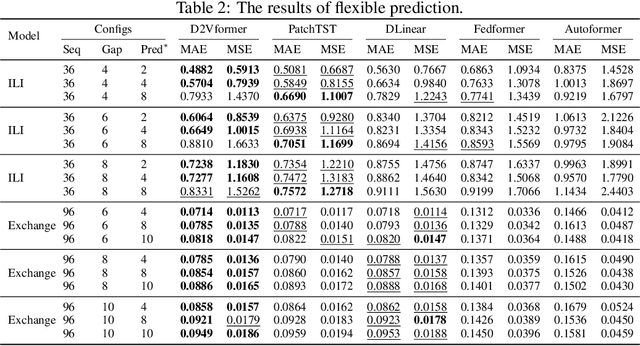
Time position embeddings capture the positional information of time steps, often serving as auxiliary inputs to enhance the predictive capabilities of time series models. However, existing models exhibit limitations in capturing intricate time positional information and effectively utilizing these embeddings. To address these limitations, this paper proposes a novel model called D2Vformer. Unlike typical prediction methods that rely on RNNs or Transformers, this approach can directly handle scenarios where the predicted sequence is not adjacent to the input sequence or where its length dynamically changes. In comparison to conventional methods, D2Vformer undoubtedly saves a significant amount of training resources. In D2Vformer, the Date2Vec module uses the timestamp information and feature sequences to generate time position embeddings. Afterward, D2Vformer introduces a new fusion block that utilizes an attention mechanism to explore the similarity in time positions between the embeddings of the input sequence and the predicted sequence, thereby generating predictions based on this similarity. Through extensive experiments on six datasets, we demonstrate that Date2Vec outperforms other time position embedding methods, and D2Vformer surpasses state-of-the-art methods in both fixed-length and variable-length prediction tasks.
Multi-Weather Image Restoration via Histogram-Based Transformer Feature Enhancement
Sep 10, 2024



Currently, the mainstream restoration tasks under adverse weather conditions have predominantly focused on single-weather scenarios. However, in reality, multiple weather conditions always coexist and their degree of mixing is usually unknown. Under such complex and diverse weather conditions, single-weather restoration models struggle to meet practical demands. This is particularly critical in fields such as autonomous driving, where there is an urgent need for a model capable of effectively handling mixed weather conditions and enhancing image quality in an automated manner. In this paper, we propose a Task Sequence Generator module that, in conjunction with the Task Intra-patch Block, effectively extracts task-specific features embedded in degraded images. The Task Intra-patch Block introduces an external learnable sequence that aids the network in capturing task-specific information. Additionally, we employ a histogram-based transformer module as the backbone of our network, enabling the capture of both global and local dynamic range features. Our proposed model achieves state-of-the-art performance on public datasets.
Multiple weather images restoration using the task transformer and adaptive mixup strategy
Sep 05, 2024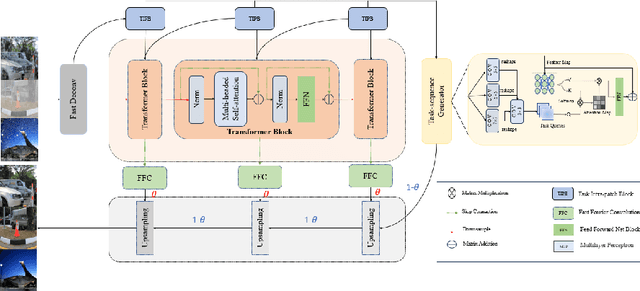

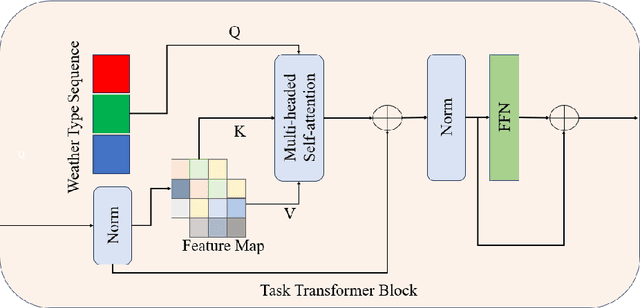

The current state-of-the-art in severe weather removal predominantly focuses on single-task applications, such as rain removal, haze removal, and snow removal. However, real-world weather conditions often consist of a mixture of several weather types, and the degree of weather mixing in autonomous driving scenarios remains unknown. In the presence of complex and diverse weather conditions, a single weather removal model often encounters challenges in producing clear images from severe weather images. Therefore, there is a need for the development of multi-task severe weather removal models that can effectively handle mixed weather conditions and improve image quality in autonomous driving scenarios. In this paper, we introduce a novel multi-task severe weather removal model that can effectively handle complex weather conditions in an adaptive manner. Our model incorporates a weather task sequence generator, enabling the self-attention mechanism to selectively focus on features specific to different weather types. To tackle the challenge of repairing large areas of weather degradation, we introduce Fast Fourier Convolution (FFC) to increase the receptive field. Additionally, we propose an adaptive upsampling technique that effectively processes both the weather task information and underlying image features by selectively retaining relevant information. Our proposed model has achieved state-of-the-art performance on the publicly available dataset.
H-SGANet: Hybrid Sparse Graph Attention Network for Deformable Medical Image Registration
Aug 29, 2024
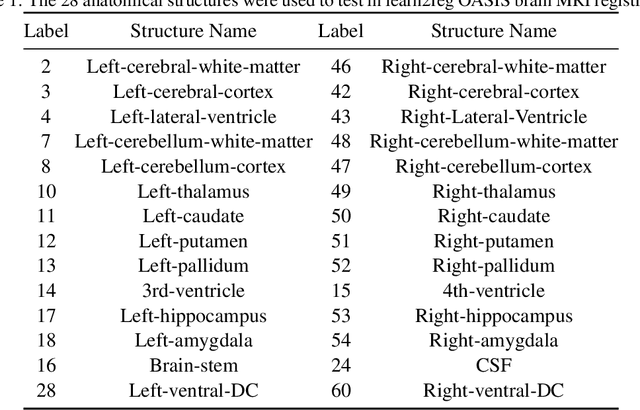


The integration of Convolutional Neural Network (ConvNet) and Transformer has emerged as a strong candidate for image registration, leveraging the strengths of both models and a large parameter space. However, this hybrid model, treating brain MRI volumes as grid or sequence structures, faces challenges in accurately representing anatomical connectivity, diverse brain regions, and vital connections contributing to the brain's internal architecture. Concerns also arise regarding the computational expense and GPU memory usage associated with this model. To tackle these issues, a lightweight hybrid sparse graph attention network (H-SGANet) has been developed. This network incorporates a central mechanism, Sparse Graph Attention (SGA), based on a Vision Graph Neural Network (ViG) with predetermined anatomical connections. The SGA module expands the model's receptive field and seamlessly integrates into the network. To further amplify the advantages of the hybrid network, the Separable Self-Attention (SSA) is employed as an enhanced token mixer, integrated with depth-wise convolution to constitute SSAFormer. This strategic integration is designed to more effectively extract long-range dependencies. As a hybrid ConvNet-ViG-Transformer model, H-SGANet offers threefold benefits for volumetric medical image registration. It optimizes fixed and moving images concurrently through a hybrid feature fusion layer and an end-to-end learning framework. Compared to VoxelMorph, a model with a similar parameter count, H-SGANet demonstrates significant performance enhancements of 3.5% and 1.5% in Dice score on the OASIS dataset and LPBA40 dataset, respectively.
HyperEditor: Achieving Both Authenticity and Cross-Domain Capability in Image Editing via Hypernetworks
Dec 21, 2023Editing real images authentically while also achieving cross-domain editing remains a challenge. Recent studies have focused on converting real images into latent codes and accomplishing image editing by manipulating these codes. However, merely manipulating the latent codes would constrain the edited images to the generator's image domain, hindering the attainment of diverse editing goals. In response, we propose an innovative image editing method called HyperEditor, which utilizes weight factors generated by hypernetworks to reassign the weights of the pre-trained StyleGAN2's generator. Guided by CLIP's cross-modal image-text semantic alignment, this innovative approach enables us to simultaneously accomplish authentic attribute editing and cross-domain style transfer, a capability not realized in previous methods. Additionally, we ascertain that modifying only the weights of specific layers in the generator can yield an equivalent editing result. Therefore, we introduce an adaptive layer selector, enabling our hypernetworks to autonomously identify the layers requiring output weight factors, which can further improve our hypernetworks' efficiency. Extensive experiments on abundant challenging datasets demonstrate the effectiveness of our method.
When Source-Free Domain Adaptation Meets Label Propagation
Jan 20, 2023



Source-free domain adaptation, where only a pre-trained source model is used to adapt to the target distribution, is a more general approach to achieving domain adaptation. However, it can be challenging to capture the inherent structure of the target features accurately due to the lack of supervised information on the target domain. To tackle this problem, we propose a novel approach called Adaptive Local Transfer (ALT) that tries to achieve efficient feature clustering from the perspective of label propagation. ALT divides the target data into inner and outlier samples based on the adaptive threshold of the learning state, and applies a customized learning strategy to best fits the data property. Specifically, inner samples are utilized for learning intra-class structure thanks to their relatively well-clustered properties. The low-density outlier samples are regularized by input consistency to achieve high accuracy with respect to the ground truth labels. In this way, local clustering can be prevented from forming spurious clusters while effectively propagating label information among subpopulations. Empirical evidence demonstrates that ALT outperforms the state of the arts on three public benchmarks: Office-31, Office-Home, and VisDA.
Dual-Attention Enhanced BDense-UNet for Liver Lesion Segmentation
Jul 24, 2021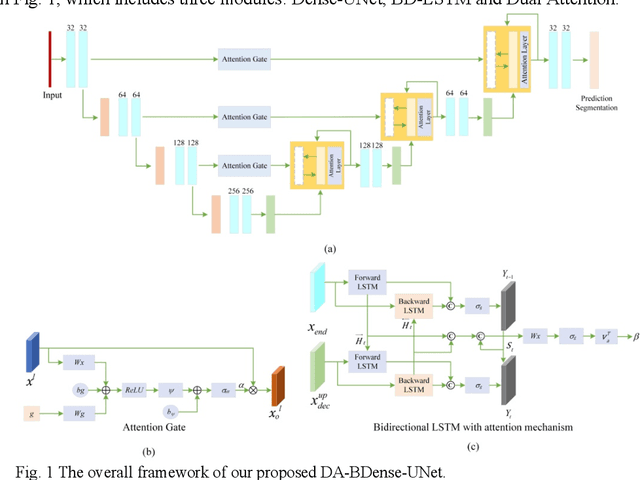
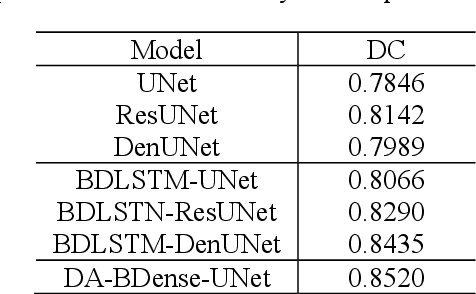
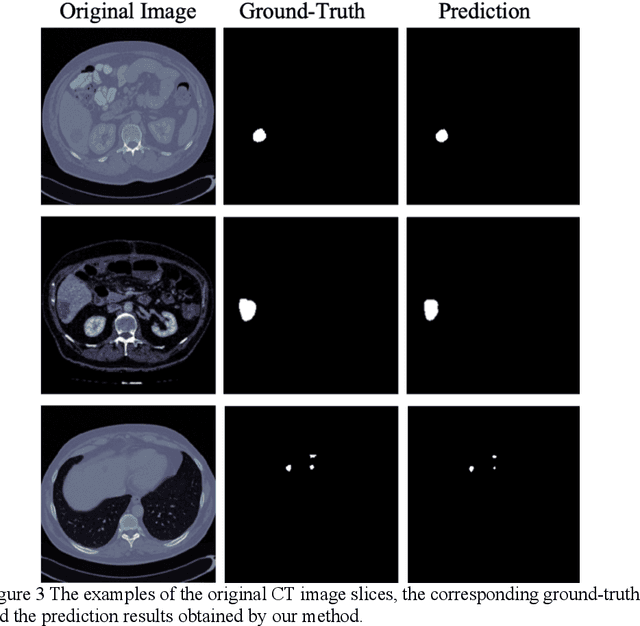
In this work, we propose a new segmentation network by integrating DenseUNet and bidirectional LSTM together with attention mechanism, termed as DA-BDense-UNet. DenseUNet allows learning enough diverse features and enhancing the representative power of networks by regulating the information flow. Bidirectional LSTM is responsible to explore the relationships between the encoded features and the up-sampled features in the encoding and decoding paths. Meanwhile, we introduce attention gates (AG) into DenseUNet to diminish responses of unrelated background regions and magnify responses of salient regions progressively. Besides, the attention in bidirectional LSTM takes into account the contribution differences of the encoded features and the up-sampled features in segmentation improvement, which can in turn adjust proper weights for these two kinds of features. We conduct experiments on liver CT image data sets collected from multiple hospitals by comparing them with state-of-the-art segmentation models. Experimental results indicate that our proposed method DA-BDense-UNet has achieved comparative performance in terms of dice coefficient, which demonstrates its effectiveness.
Inner-Imaging Convolutional Networks
Apr 22, 2019
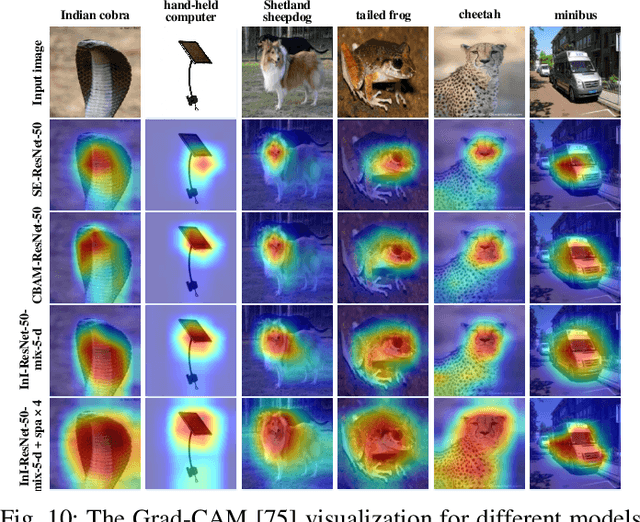
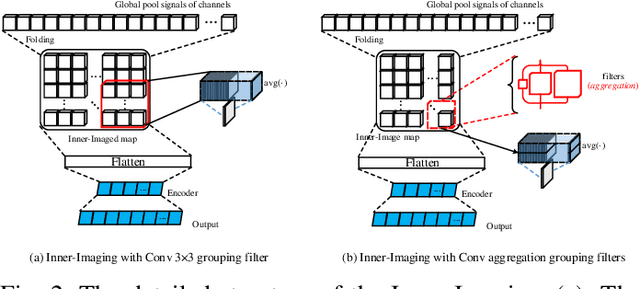
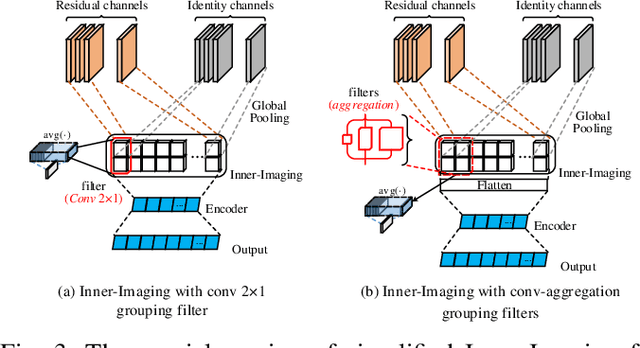
Despite the tremendous success in computer vision, deep convolutional networks suffer from serious computation cost and redundancies. Although previous works address this issue by enhancing diversities of filters, they ignore that both complementarity and completeness are required in the internal structure of convolutional network. In this setting, we propose a novel Inner-Imaging architecture, which allows relationships between channels to meet the above requirement. Specifically, we organize the filter signal points in groups using convolutional kernels to model both the intra- and inter-group relationships simultaneously. Consequently, we not only increase diversities of channels but also explicitly enhance the complementarity and completeness. Our proposed architecture is lightweight and easy to be implemented for improving the modelling efficiency and performance. We conduct extensive experiments on CIFAR, SVHN and ImageNet and verify the effectiveness of our inner-imaging architecture with residual networks as the backbone.