 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Distribution Alignment via Adaptive Optimal Transport
Mar 07, 2025To remedy the drawbacks of full-mass or fixed-mass constraints in classical optimal transport, we propose adaptive optimal transport which is distinctive from the classical optimal transport in its ability of adaptive-mass preserving. It aims to answer the mathematical problem of how to transport the probability mass adaptively between probability distributions, which is a fundamental topic in various areas of artificial intelligence. Adaptive optimal transport is able to transfer mass adaptively in the light of the intrinsic structure of the problem itself. The theoretical results shed light on the adaptive mechanism of mass transportation. Furthermore, we instantiate the adaptive optimal transport in machine learning application to align source and target distributions partially and adaptively by respecting the ubiquity of noises, outliers, and distribution shifts in the data. The experiment results on the domain adaptation benchmarks show that the proposed method significantly outperforms the state-of-the-art algorithms.
Unsupervised Domain Adaptation via Deep Hierarchical Optimal Transport
Nov 21, 2022



Unsupervised domain adaptation is a challenging task that aims to estimate a transferable model for unlabeled target domain by exploiting source labeled data. Optimal Transport (OT) based methods recently have been proven to be a promising direction for domain adaptation due to their competitive performance. However, most of these methods coarsely aligned source and target distributions, leading to the over-aligned problem where the category-discriminative information is mixed up although domain-invariant representations can be learned. In this paper, we propose a Deep Hierarchical Optimal Transport method (DeepHOT) for unsupervised domain adaptation. The main idea is to use hierarchical optimal transport to learn both domain-invariant and category-discriminative representations by mining the rich structural correlations among domain data. The DeepHOT framework consists of a domain-level OT and an image-level OT, where the latter is used as the ground distance metric for the former. The image-level OT captures structural associations of local image regions that are beneficial to image classification, while the domain-level OT learns domain-invariant representations by leveraging the underlying geometry of domains. However, due to the high computational complexity, the optimal transport based models are limited in some scenarios. To this end, we propose a robust and efficient implementation of the DeepHOT framework by approximating origin OT with sliced Wasserstein distance in image-level OT and using a mini-batch unbalanced optimal transport for domain-level OT. Extensive experiments show that DeepHOT surpasses the state-of-the-art methods in four benchmark datasets. Code will be released on GitHub.
Duck swarm algorithm: a novel swarm intelligence algorithm
Dec 27, 2021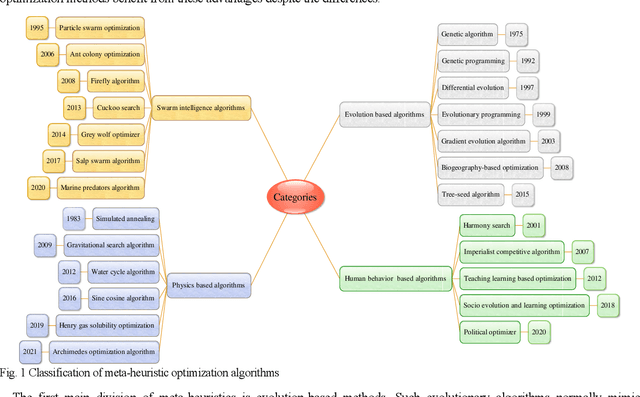
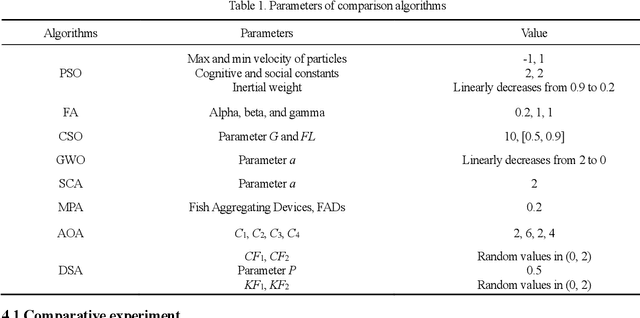

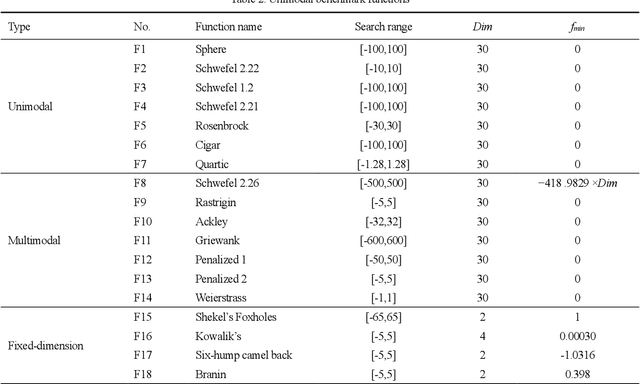
A swarm intelligence-based optimization algorithm, named Duck Swarm Algorithm (DSA), is proposed in this paper. This algorithm is inspired by the searching for food sources and foraging behaviors of the duck swarm. The performance of DSA is verified by using eighteen benchmark functions, where it is statistical (best, mean, standard deviation, and average running time) results are compared with seven well-known algorithms like Particle swarm optimization (PSO), Firefly algorithm (FA), Chicken swarm optimization (CSO), Grey wolf optimizer (GWO), Sine cosine algorithm (SCA), and Marine-predators algorithm (MPA), and Archimedes optimization algorithm (AOA). Moreover, the Wilcoxon rank-sum test, Friedman test, and convergence curves of the comparison results are used to prove the superiority of the DSA against other algorithms. The results demonstrate that DSA is a high-performance optimization method in terms of convergence speed and exploration-exploitation balance for solving high-dimension optimization functions. Also, DSA is applied for the optimal design of two constrained engineering problems (the Three-bar truss problem, and the Sawmill operation problem). Additionally, four engineering constraint problems have also been used to analyze the performance of the proposed DSA. Overall, the comparison results revealed that the DSA is a promising and very competitive algorithm for solving different optimization problems.
What Can Knowledge Bring to Machine Learning? -- A Survey of Low-shot Learning for Structured Data
Jun 11, 2021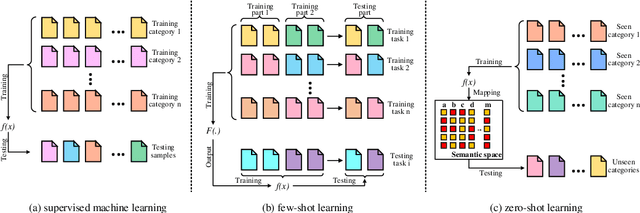

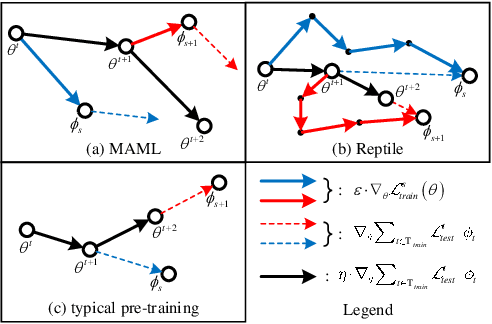
Supervised machine learning has several drawbacks that make it difficult to use in many situations. Drawbacks include: heavy reliance on massive training data, limited generalizability and poor expressiveness of high-level semantics. Low-shot Learning attempts to address these drawbacks. Low-shot learning allows the model to obtain good predictive power with very little or no training data, where structured knowledge plays a key role as a high-level semantic representation of human. This article will review the fundamental factors of low-shot learning technologies, with a focus on the operation of structured knowledge under different low-shot conditions. We also introduce other techniques relevant to low-shot learning. Finally, we point out the limitations of low-shot learning, the prospects and gaps of industrial applications, and future research directions.
Semantic Graph-enhanced Visual Network for Zero-shot Learning
Jun 08, 2020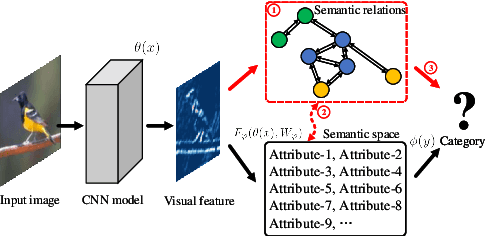
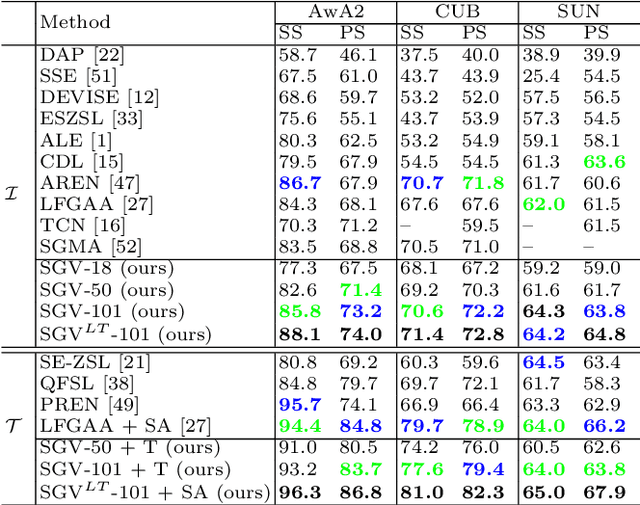

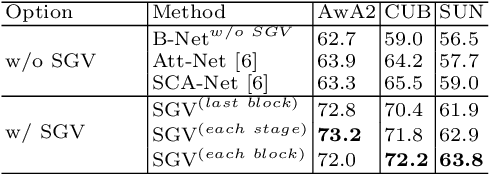
Zero-shot learning uses semantic attributes to connect the search space of unseen objects. In recent years, although the deep convolutional network brings powerful visual modeling capabilities to the ZSL task, its visual features have severe pattern inertia and lack of representation of semantic relationships, which leads to severe bias and ambiguity. In response to this, we propose the Graph-based Visual-Semantic Entanglement Network to conduct graph modeling of visual features, which is mapped to semantic attributes by using a knowledge graph, it contains several novel designs: 1. it establishes a multi-path entangled network with the convolutional neural network (CNN) and the graph convolutional network (GCN), which input the visual features from CNN to GCN to model the implicit semantic relations, then GCN feedback the graph modeled information to CNN features; 2. it uses attribute word vectors as the target for the graph semantic modeling of GCN, which forms a self-consistent regression for graph modeling and supervise GCN to learn more personalized attribute relations; 3. it fuses and supplements the hierarchical visual-semantic features refined by graph modeling into visual embedding. By promoting the semantic linkage modeling of visual features, our method outperforms state-of-the-art approaches on multiple representative ZSL datasets: AwA2, CUB, and SUN.
Multiple Attentional Pyramid Networks for Chinese Herbal Recognition
May 13, 2020
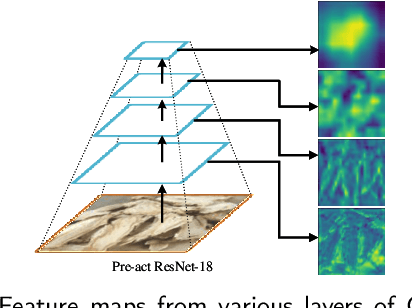
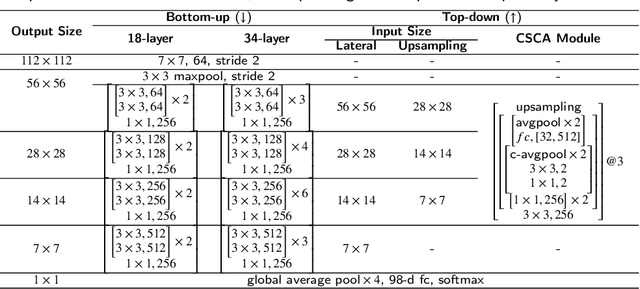
Chinese herbs play a critical role in Traditional Chinese Medicine. Due to different recognition granularity, they can be recognized accurately only by professionals with much experience. It is expected that they can be recognized automatically using new techniques like machine learning. However, there is no Chinese herbal image dataset available. Simultaneously, there is no machine learning method which can deal with Chinese herbal image recognition well. Therefore, this paper begins with building a new standard Chinese-Herbs dataset. Subsequently, a new Attentional Pyramid Networks (APN) for Chinese herbal recognition is proposed, where both novel competitive attention and spatial collaborative attention are proposed and then applied. APN can adaptively model Chinese herbal images with different feature scales. Finally, a new framework for Chinese herbal recognition is proposed as a new application of APN. Experiments are conducted on our constructed dataset and validate the effectiveness of our methods.
Inner-Imaging Convolutional Networks
Apr 22, 2019
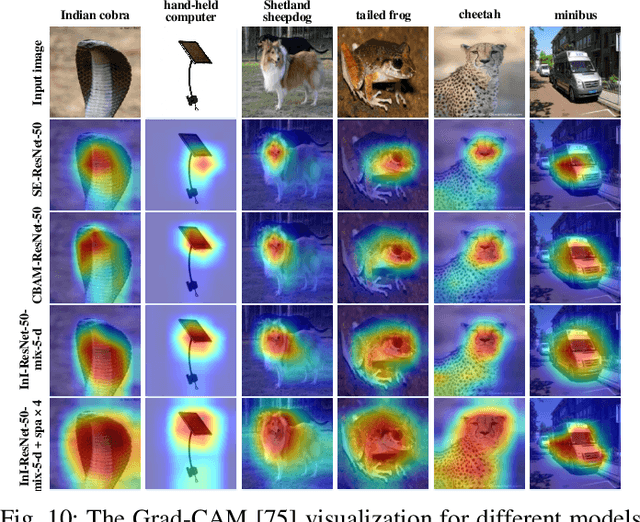
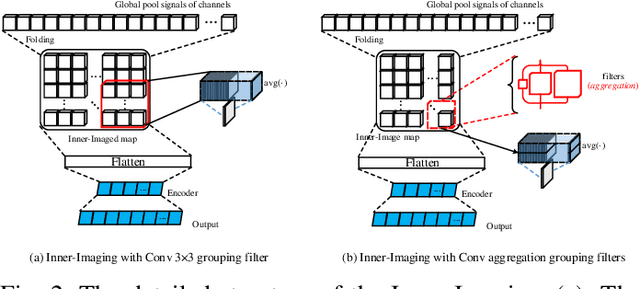
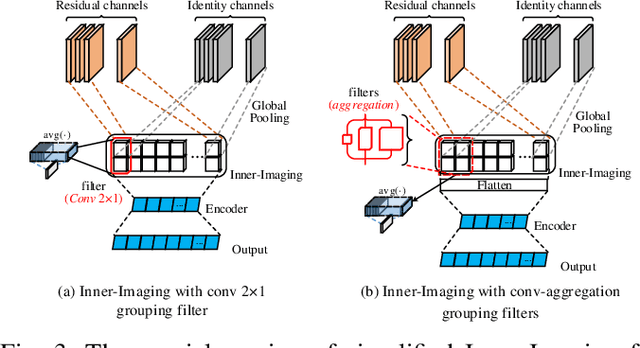
Despite the tremendous success in computer vision, deep convolutional networks suffer from serious computation cost and redundancies. Although previous works address this issue by enhancing diversities of filters, they ignore that both complementarity and completeness are required in the internal structure of convolutional network. In this setting, we propose a novel Inner-Imaging architecture, which allows relationships between channels to meet the above requirement. Specifically, we organize the filter signal points in groups using convolutional kernels to model both the intra- and inter-group relationships simultaneously. Consequently, we not only increase diversities of channels but also explicitly enhance the complementarity and completeness. Our proposed architecture is lightweight and easy to be implemented for improving the modelling efficiency and performance. We conduct extensive experiments on CIFAR, SVHN and ImageNet and verify the effectiveness of our inner-imaging architecture with residual networks as the backbone.
Stochastic Region Pooling: Make Attention More Expressive
Apr 22, 2019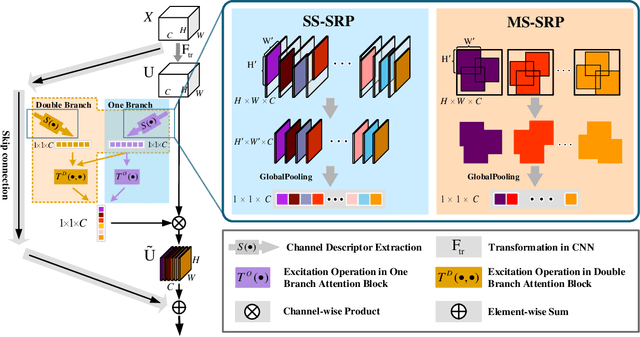
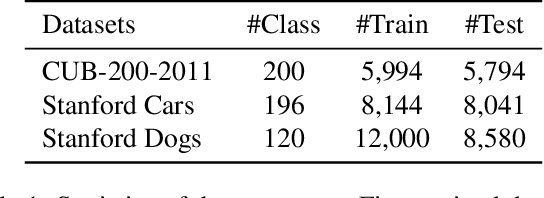
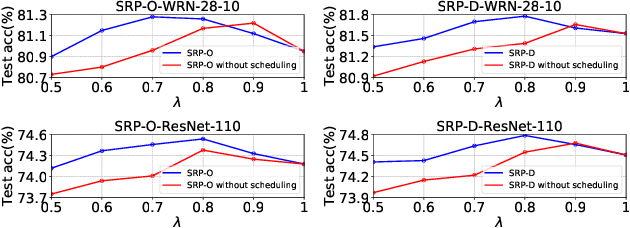
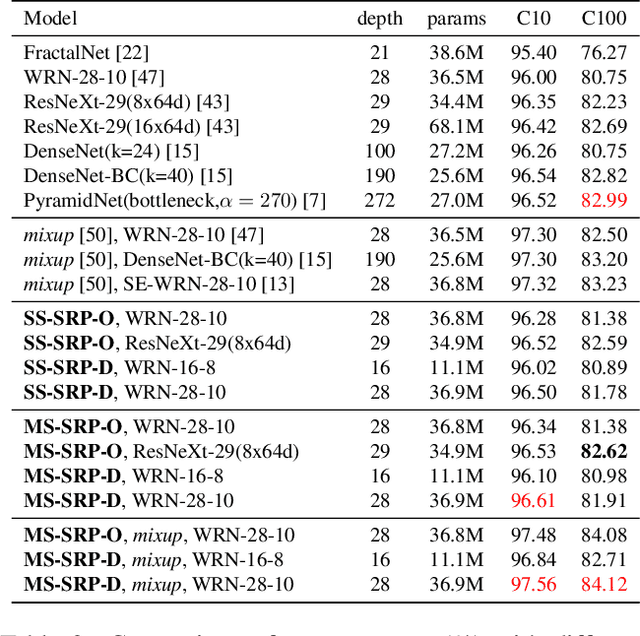
Global Average Pooling (GAP) is used by default on the channel-wise attention mechanism to extract channel descriptors. However, the simple global aggregation method of GAP is easy to make the channel descriptors have homogeneity, which weakens the detail distinction between feature maps, thus affecting the performance of the attention mechanism. In this work, we propose a novel method for channel-wise attention network, called Stochastic Region Pooling (SRP), which makes the channel descriptors more representative and diversity by encouraging the feature map to have more or wider important feature responses. Also, SRP is the general method for the attention mechanisms without any additional parameters or computation. It can be widely applied to attention networks without modifying the network structure. Experimental results on image recognition datasets including CIAFR-10/100, ImageNet and three Fine-grained datasets (CUB-200-2011, Stanford Cars and Stanford Dogs) show that SRP brings the significant improvements of the performance over efficient CNNs and achieves the state-of-the-art results.
Chinese Herbal Recognition based on Competitive Attentional Fusion of Multi-hierarchies Pyramid Features
Dec 23, 2018
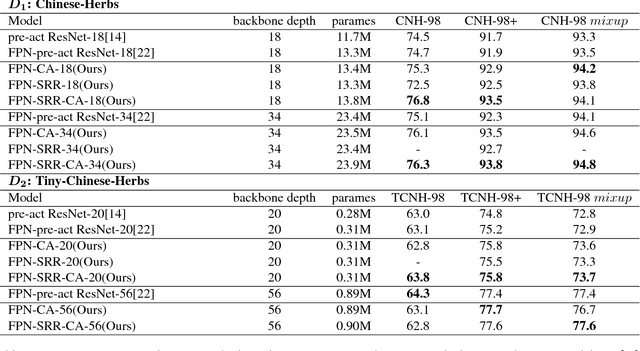

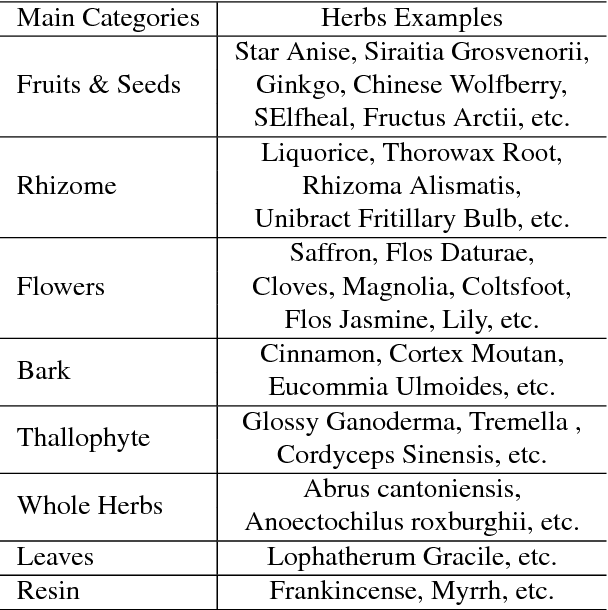
Convolution neural netwotks (CNNs) are successfully applied in image recognition task. In this study, we explore the approach of automatic herbal recognition with CNNs and build the standard Chinese herbs datasets firstly. According to the characteristics of herbal images, we proposed the competitive attentional fusion pyramid networks to model the features of herbal image, which mdoels the relationship of feature maps from different levels, and re-weights multi-level channels with channel-wise attention mechanism. In this way, we can dynamically adjust the weight of feature maps from various layers, according to the visual characteristics of each herbal image. Moreover, we also introduce the spatial attention to recalibrate the misaligned features caused by sampling in features amalgamation. Extensive experiments are conducted on our proposed datasets and validate the superior performance of our proposed models. The Chinese herbs datasets will be released upon acceptance to facilitate the research of Chinese herbal recognition.
Convolutional herbal prescription building method from multi-scale facial features
Dec 17, 2018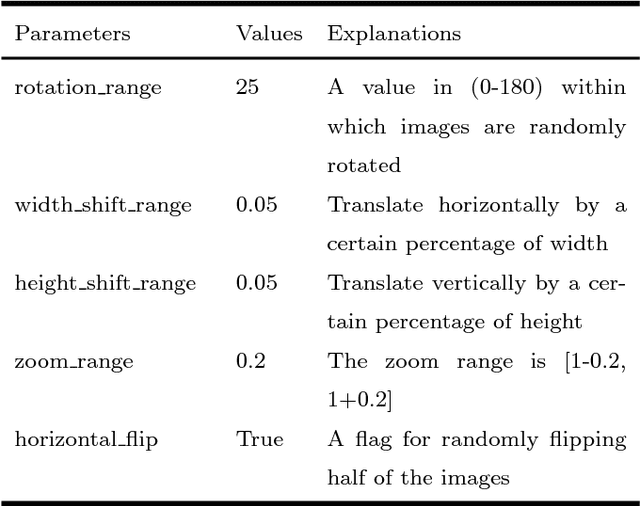
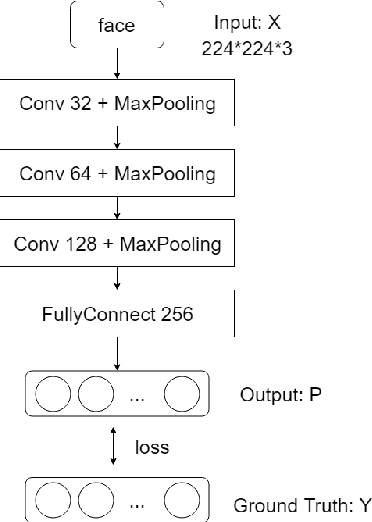
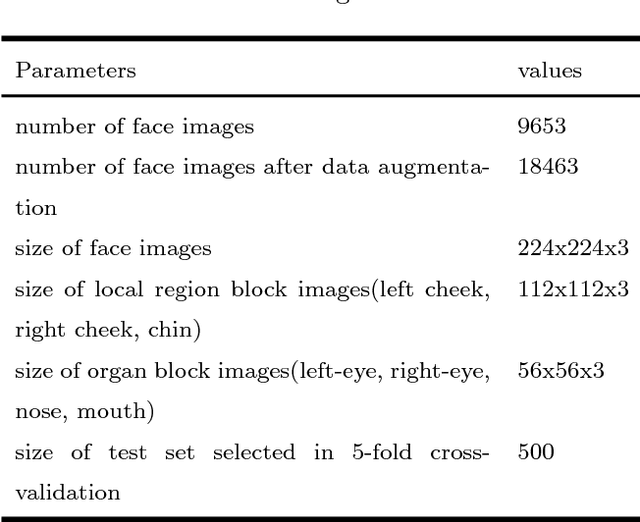
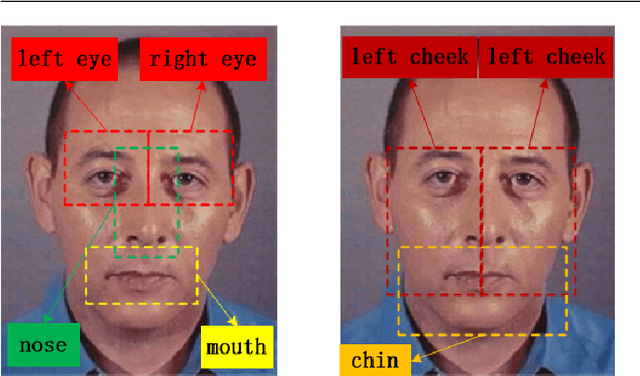
In Traditional Chinese Medicine (TCM), facial features are important basis for diagnosis and treatment. A doctor of TCM can prescribe according to a patient's physical indicators such as face, tongue, voice, symptoms, pulse. Previous works analyze and generate prescription according to symptoms. However, research work to mine the association between facial features and prescriptions has not been found for the time being. In this work, we try to use deep learning methods to mine the relationship between the patient's face and herbal prescriptions (TCM prescriptions), and propose to construct convolutional neural networks that generate TCM prescriptions according to the patient's face image. It is a novel and challenging job. In order to mine features from different granularities of faces, we design a multi-scale convolutional neural network based on three-grained face, which mines the patient's face information from the organs, local regions, and the entire face. Our experiments show that convolutional neural networks can learn relevant information from face to prescribe, and the multi-scale convolutional neural networks based on three-grained face perform better.