 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAOI: Turning Failed Trajectories into Training Signals for Autonomous Cloud Diagnosis
Mar 05, 2026Large language model (LLM) agents offer a promising data-driven approach to automating Site Reliability Engineering (SRE), yet their enterprise deployment is constrained by three challenges: restricted access to proprietary data, unsafe action execution under permission-governed environments, and the inability of closed systems to improve from failures. We present AOI (Autonomous Operations Intelligence), a trainable multi-agent framework formulating automated operations as a structured trajectory learning problem under security constraints. Our approach integrates three key components. First, a trainable diagnostic system applies Group Relative Policy Optimization (GRPO) to distill expert-level knowledge into locally deployed open-source models, enabling preference-based learning without exposing sensitive data. Second, a read-write separated execution architecture decomposes operational trajectories into observation, reasoning, and action phases, allowing safe learning while preventing unauthorized state mutation. Third, a Failure Trajectory Closed-Loop Evolver mines unsuccessful trajectories and converts them into corrective supervision signals, enabling continual data augmentation. Evaluated on the AIOpsLab benchmark, our contributions yield cumulative gains. (1) The AOI runtime alone achieves 66.3% best@5 success on all 86 tasks, outperforming the prior state-of-the-art (41.9%) by 24.4 points. (2) Adding Observer GRPO training, a locally deployed 14B model reaches 42.9% avg@1 on 63 held-out tasks with unseen fault types, surpassing Claude Sonnet 4.5. (3) The Evolver converts 37 failed trajectories into diagnostic guidance, improving end-to-end avg@5 by 4.8 points while reducing variance by 35%.
EVM-QuestBench: An Execution-Grounded Benchmark for Natural-Language Transaction Code Generation
Jan 10, 2026Large language models are increasingly applied to various development scenarios. However, in on-chain transaction scenarios, even a minor error can cause irreversible loss for users. Existing evaluations often overlook execution accuracy and safety. We introduce EVM-QuestBench, an execution-grounded benchmark for natural-language transaction-script generation on EVM-compatible chains. The benchmark employs dynamic evaluation: instructions are sampled from template pools, numeric parameters are drawn from predefined intervals, and validators verify outcomes against these instantiated values. EVM-QuestBench contains 107 tasks (62 atomic, 45 composite). Its modular architecture enables rapid task development. The runner executes scripts on a forked EVM chain with snapshot isolation; composite tasks apply step-efficiency decay. We evaluate 20 models and find large performance gaps, with split scores revealing persistent asymmetry between single-action precision and multi-step workflow completion. Code: https://anonymous.4open.science/r/bsc_quest_bench-A9CF/.
H2R-Grounder: A Paired-Data-Free Paradigm for Translating Human Interaction Videos into Physically Grounded Robot Videos
Dec 10, 2025



Robots that learn manipulation skills from everyday human videos could acquire broad capabilities without tedious robot data collection. We propose a video-to-video translation framework that converts ordinary human-object interaction videos into motion-consistent robot manipulation videos with realistic, physically grounded interactions. Our approach does not require any paired human-robot videos for training only a set of unpaired robot videos, making the system easy to scale. We introduce a transferable representation that bridges the embodiment gap: by inpainting the robot arm in training videos to obtain a clean background and overlaying a simple visual cue (a marker and arrow indicating the gripper's position and orientation), we can condition a generative model to insert the robot arm back into the scene. At test time, we apply the same process to human videos (inpainting the person and overlaying human pose cues) and generate high-quality robot videos that mimic the human's actions. We fine-tune a SOTA video diffusion model (Wan 2.2) in an in-context learning manner to ensure temporal coherence and leveraging of its rich prior knowledge. Empirical results demonstrate that our approach achieves significantly more realistic and grounded robot motions compared to baselines, pointing to a promising direction for scaling up robot learning from unlabeled human videos. Project page: https://showlab.github.io/H2R-Grounder/
Exploring Diffusion with Test-Time Training on Efficient Image Restoration
Jun 17, 2025Image restoration faces challenges including ineffective feature fusion, computational bottlenecks and inefficient diffusion processes. To address these, we propose DiffRWKVIR, a novel framework unifying Test-Time Training (TTT) with efficient diffusion. Our approach introduces three key innovations: (1) Omni-Scale 2D State Evolution extends RWKV's location-dependent parameterization to hierarchical multi-directional 2D scanning, enabling global contextual awareness with linear complexity O(L); (2) Chunk-Optimized Flash Processing accelerates intra-chunk parallelism by 3.2x via contiguous chunk processing (O(LCd) complexity), reducing sequential dependencies and computational overhead; (3) Prior-Guided Efficient Diffusion extracts a compact Image Prior Representation (IPR) in only 5-20 steps, proving 45% faster training/inference than DiffIR while solving computational inefficiency in denoising. Evaluated across super-resolution and inpainting benchmarks (Set5, Set14, BSD100, Urban100, Places365), DiffRWKVIR outperforms SwinIR, HAT, and MambaIR/v2 in PSNR, SSIM, LPIPS, and efficiency metrics. Our method establishes a new paradigm for adaptive, high-efficiency image restoration with optimized hardware utilization.
macOSWorld: A Multilingual Interactive Benchmark for GUI Agents
Jun 05, 2025

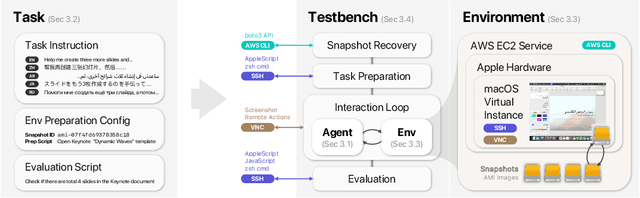

Graphical User Interface (GUI) agents show promising capabilities for automating computer-use tasks and facilitating accessibility, but existing interactive benchmarks are mostly English-only, covering web-use or Windows, Linux, and Android environments, but not macOS. macOS is a major OS with distinctive GUI patterns and exclusive applications. To bridge the gaps, we present macOSWorld, the first comprehensive benchmark for evaluating GUI agents on macOS. macOSWorld features 202 multilingual interactive tasks across 30 applications (28 macOS-exclusive), with task instructions and OS interfaces offered in 5 languages (English, Chinese, Arabic, Japanese, and Russian). As GUI agents are shown to be vulnerable to deception attacks, macOSWorld also includes a dedicated safety benchmarking subset. Our evaluation on six GUI agents reveals a dramatic gap: proprietary computer-use agents lead at above 30% success rate, while open-source lightweight research models lag at below 2%, highlighting the need for macOS domain adaptation. Multilingual benchmarks also expose common weaknesses, especially in Arabic, with a 27.5% average degradation compared to English. Results from safety benchmarking also highlight that deception attacks are more general and demand immediate attention. macOSWorld is available at https://github.com/showlab/macosworld.
In-Context Defense in Computer Agents: An Empirical Study
Mar 12, 2025Computer agents powered by vision-language models (VLMs) have significantly advanced human-computer interaction, enabling users to perform complex tasks through natural language instructions. However, these agents are vulnerable to context deception attacks, an emerging threat where adversaries embed misleading content into the agent's operational environment, such as a pop-up window containing deceptive instructions. Existing defenses, such as instructing agents to ignore deceptive elements, have proven largely ineffective. As the first systematic study on protecting computer agents, we introduce textbf{in-context defense}, leveraging in-context learning and chain-of-thought (CoT) reasoning to counter such attacks. Our approach involves augmenting the agent's context with a small set of carefully curated exemplars containing both malicious environments and corresponding defensive responses. These exemplars guide the agent to first perform explicit defensive reasoning before action planning, reducing susceptibility to deceptive attacks. Experiments demonstrate the effectiveness of our method, reducing attack success rates by 91.2% on pop-up window attacks, 74.6% on average on environment injection attacks, while achieving 100% successful defenses against distracting advertisements. Our findings highlight that (1) defensive reasoning must precede action planning for optimal performance, and (2) a minimal number of exemplars (fewer than three) is sufficient to induce an agent's defensive behavior.
Partial Distribution Alignment via Adaptive Optimal Transport
Mar 07, 2025To remedy the drawbacks of full-mass or fixed-mass constraints in classical optimal transport, we propose adaptive optimal transport which is distinctive from the classical optimal transport in its ability of adaptive-mass preserving. It aims to answer the mathematical problem of how to transport the probability mass adaptively between probability distributions, which is a fundamental topic in various areas of artificial intelligence. Adaptive optimal transport is able to transfer mass adaptively in the light of the intrinsic structure of the problem itself. The theoretical results shed light on the adaptive mechanism of mass transportation. Furthermore, we instantiate the adaptive optimal transport in machine learning application to align source and target distributions partially and adaptively by respecting the ubiquity of noises, outliers, and distribution shifts in the data. The experiment results on the domain adaptation benchmarks show that the proposed method significantly outperforms the state-of-the-art algorithms.
SpecDM: Hyperspectral Dataset Synthesis with Pixel-level Semantic Annotations
Feb 24, 2025

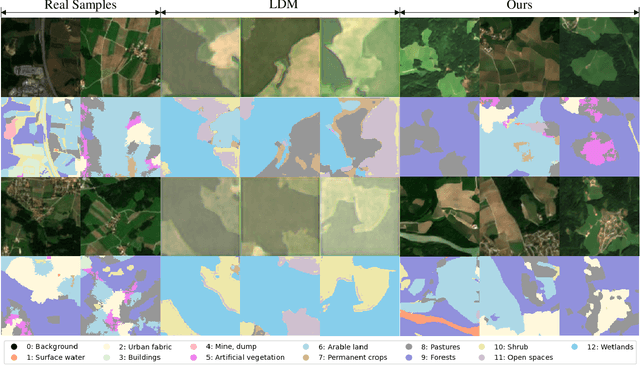

In hyperspectral remote sensing field, some downstream dense prediction tasks, such as semantic segmentation (SS) and change detection (CD), rely on supervised learning to improve model performance and require a large amount of manually annotated data for training. However, due to the needs of specific equipment and special application scenarios, the acquisition and annotation of hyperspectral images (HSIs) are often costly and time-consuming. To this end, our work explores the potential of generative diffusion model in synthesizing HSIs with pixel-level annotations. The main idea is to utilize a two-stream VAE to learn the latent representations of images and corresponding masks respectively, learn their joint distribution during the diffusion model training, and finally obtain the image and mask through their respective decoders. To the best of our knowledge, it is the first work to generate high-dimensional HSIs with annotations. Our proposed approach can be applied in various kinds of dataset generation. We select two of the most widely used dense prediction tasks: semantic segmentation and change detection, and generate datasets suitable for these tasks. Experiments demonstrate that our synthetic datasets have a positive impact on the improvement of these downstream tasks.
IDProtector: An Adversarial Noise Encoder to Protect Against ID-Preserving Image Generation
Dec 16, 2024



Recently, zero-shot methods like InstantID have revolutionized identity-preserving generation. Unlike multi-image finetuning approaches such as DreamBooth, these zero-shot methods leverage powerful facial encoders to extract identity information from a single portrait photo, enabling efficient identity-preserving generation through a single inference pass. However, this convenience introduces new threats to the facial identity protection. This paper aims to safeguard portrait photos from unauthorized encoder-based customization. We introduce IDProtector, an adversarial noise encoder that applies imperceptible adversarial noise to portrait photos in a single forward pass. Our approach offers universal protection for portraits against multiple state-of-the-art encoder-based methods, including InstantID, IP-Adapter, and PhotoMaker, while ensuring robustness to common image transformations such as JPEG compression, resizing, and affine transformations. Experiments across diverse portrait datasets and generative models reveal that IDProtector generalizes effectively to unseen data and even closed-source proprietary models.
Anti-Reference: Universal and Immediate Defense Against Reference-Based Generation
Dec 08, 2024Diffusion models have revolutionized generative modeling with their exceptional ability to produce high-fidelity images. However, misuse of such potent tools can lead to the creation of fake news or disturbing content targeting individuals, resulting in significant social harm. In this paper, we introduce Anti-Reference, a novel method that protects images from the threats posed by reference-based generation techniques by adding imperceptible adversarial noise to the images. We propose a unified loss function that enables joint attacks on fine-tuning-based customization methods, non-fine-tuning customization methods, and human-centric driving methods. Based on this loss, we train a Adversarial Noise Encoder to predict the noise or directly optimize the noise using the PGD method. Our method shows certain transfer attack capabilities, effectively challenging both gray-box models and some commercial APIs. Extensive experiments validate the performance of Anti-Reference, establishing a new benchmark in image security.