 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecDM: Hyperspectral Dataset Synthesis with Pixel-level Semantic Annotations
Feb 24, 2025

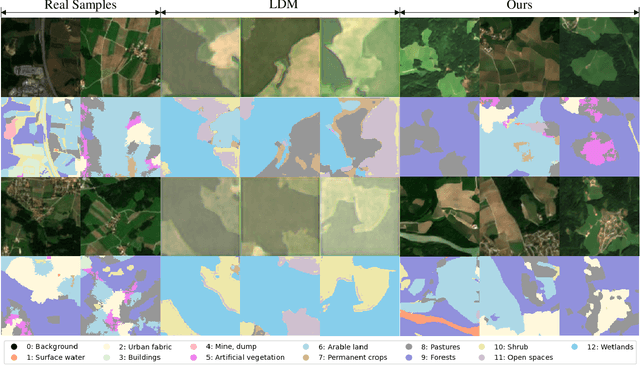

In hyperspectral remote sensing field, some downstream dense prediction tasks, such as semantic segmentation (SS) and change detection (CD), rely on supervised learning to improve model performance and require a large amount of manually annotated data for training. However, due to the needs of specific equipment and special application scenarios, the acquisition and annotation of hyperspectral images (HSIs) are often costly and time-consuming. To this end, our work explores the potential of generative diffusion model in synthesizing HSIs with pixel-level annotations. The main idea is to utilize a two-stream VAE to learn the latent representations of images and corresponding masks respectively, learn their joint distribution during the diffusion model training, and finally obtain the image and mask through their respective decoders. To the best of our knowledge, it is the first work to generate high-dimensional HSIs with annotations. Our proposed approach can be applied in various kinds of dataset generation. We select two of the most widely used dense prediction tasks: semantic segmentation and change detection, and generate datasets suitable for these tasks. Experiments demonstrate that our synthetic datasets have a positive impact on the improvement of these downstream tasks.
Physics-Informed Graph Neural Network for Spatial-temporal Production Forecasting
Sep 23, 2022

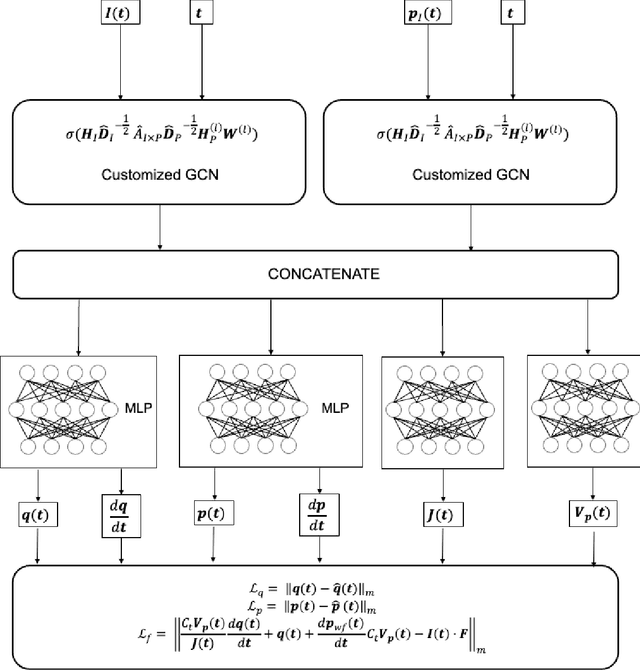
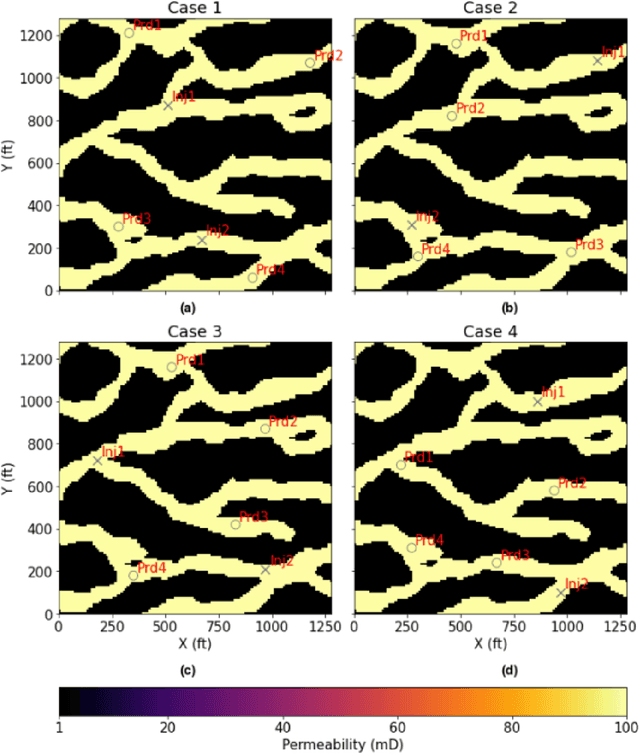
Production forecast based on historical data provides essential value for developing hydrocarbon resources. Classic history matching workflow is often computationally intense and geometry-dependent. Analytical data-driven models like decline curve analysis (DCA) and capacitance resistance models (CRM) provide a grid-free solution with a relatively simple model capable of integrating some degree of physics constraints. However, the analytical solution may ignore subsurface geometries and is appropriate only for specific flow regimes and otherwise may violate physics conditions resulting in degraded model prediction accuracy. Machine learning-based predictive model for time series provides non-parametric, assumption-free solutions for production forecasting, but are prone to model overfit due to training data sparsity; therefore may be accurate over short prediction time intervals. We propose a grid-free, physics-informed graph neural network (PI-GNN) for production forecasting. A customized graph convolution layer aggregates neighborhood information from historical data and has the flexibility to integrate domain expertise into the data-driven model. The proposed method relaxes the dependence on close-form solutions like CRM and honors the given physics-based constraints. Our proposed method is robust, with improved performance and model interpretability relative to the conventional CRM and GNN baseline without physics constraints.
A deep learning pipeline for localization, differentiation, and uncertainty estimation of liver lesions using multi-phasic and multi-sequence MRI
Oct 17, 2021
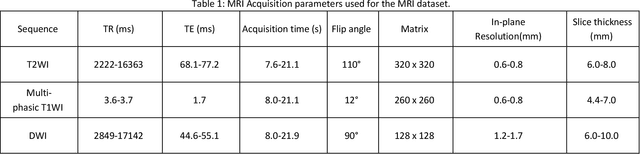
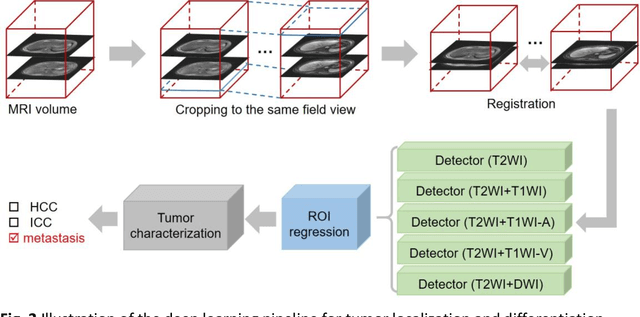
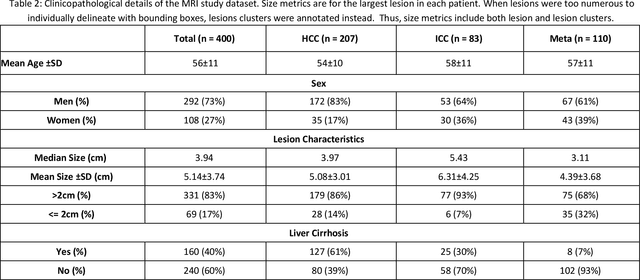
Objectives: to propose a fully-automatic computer-aided diagnosis (CAD) solution for liver lesion characterization, with uncertainty estimation. Methods: we enrolled 400 patients who had either liver resection or a biopsy and was diagnosed with either hepatocellular carcinoma (HCC), intrahepatic cholangiocarcinoma, or secondary metastasis, from 2006 to 2019. Each patient was scanned with T1WI, T2WI, T1WI venous phase (T2WI-V), T1WI arterial phase (T1WI-A), and DWI MRI sequences. We propose a fully-automatic deep CAD pipeline that localizes lesions from 3D MRI studies using key-slice parsing and provides a confidence measure for its diagnoses. We evaluate using five-fold cross validation and compare performance against three radiologists, including a senior hepatology radiologist, a junior hepatology radiologist and an abdominal radiologist. Results: the proposed CAD solution achieves a mean F1 score of 0.62, outperforming the abdominal radiologist (0.47), matching the junior hepatology radiologist (0.61), and underperforming the senior hepatology radiologist (0.68). The CAD system can informatively assess its diagnostic confidence, i.e., when only evaluating on the 70% most confident cases the mean f1 score and sensitivity at 80% specificity for HCC vs. others are boosted from 0.62 to 0.71 and 0.84 to 0.92, respectively. Conclusion: the proposed fully-automatic CAD solution can provide good diagnostic performance with informative confidence assessments in finding and discriminating liver lesions from MRI studies.
Large-scale multilingual audio visual dubbing
Nov 06, 2020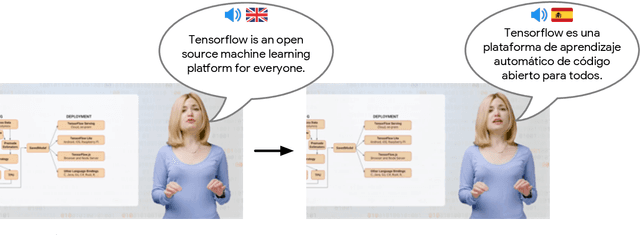
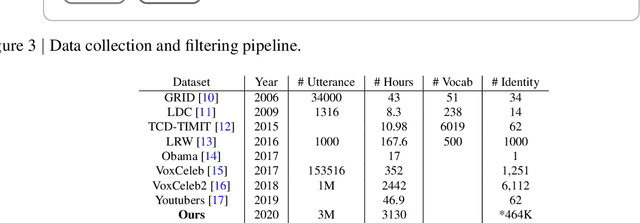
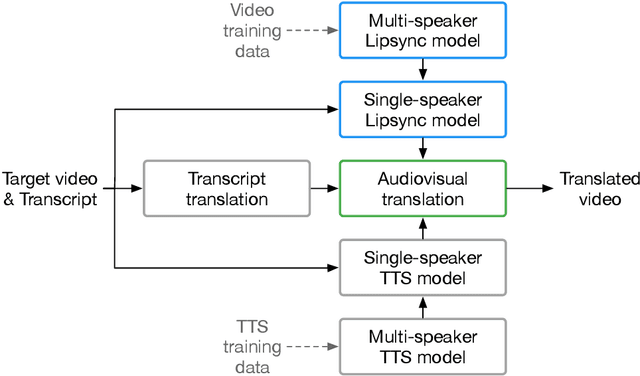
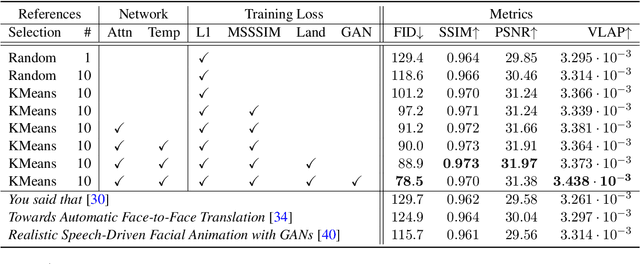
We describe a system for large-scale audiovisual translation and dubbing, which translates videos from one language to another. The source language's speech content is transcribed to text, translated, and automatically synthesized into target language speech using the original speaker's voice. The visual content is translated by synthesizing lip movements for the speaker to match the translated audio, creating a seamless audiovisual experience in the target language. The audio and visual translation subsystems each contain a large-scale generic synthesis model trained on thousands of hours of data in the corresponding domain. These generic models are fine-tuned to a specific speaker before translation, either using an auxiliary corpus of data from the target speaker, or using the video to be translated itself as the input to the fine-tuning process. This report gives an architectural overview of the full system, as well as an in-depth discussion of the video dubbing component. The role of the audio and text components in relation to the full system is outlined, but their design is not discussed in detail. Translated and dubbed demo videos generated using our system can be viewed at https://www.youtube.com/playlist?list=PLSi232j2ZA6_1Exhof5vndzyfbxAhhEs5