 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicFuse: Single Image Fusion for Visual and Semantic Reinforcement
Feb 02, 2026This paper focuses on a highly practical scenario: how to continue benefiting from the advantages of multi-modal image fusion under harsh conditions when only visible imaging sensors are available. To achieve this goal, we propose a novel concept of single-image fusion, which extends conventional data-level fusion to the knowledge level. Specifically, we develop MagicFuse, a novel single image fusion framework capable of deriving a comprehensive cross-spectral scene representation from a single low-quality visible image. MagicFuse first introduces an intra-spectral knowledge reinforcement branch and a cross-spectral knowledge generation branch based on the diffusion models. They mine scene information obscured in the visible spectrum and learn thermal radiation distribution patterns transferred to the infrared spectrum, respectively. Building on them, we design a multi-domain knowledge fusion branch that integrates the probabilistic noise from the diffusion streams of these two branches, from which a cross-spectral scene representation can be obtained through successive sampling. Then, we impose both visual and semantic constraints to ensure that this scene representation can satisfy human observation while supporting downstream semantic decision-making. Extensive experiments show that our MagicFuse achieves visual and semantic representation performance comparable to or even better than state-of-the-art fusion methods with multi-modal inputs, despite relying solely on a single degraded visible image.
Survey of Multimodal Geospatial Foundation Models: Techniques, Applications, and Challenges
Oct 27, 2025Foundation models have transformed natural language processing and computer vision, and their impact is now reshaping remote sensing image analysis. With powerful generalization and transfer learning capabilities, they align naturally with the multimodal, multi-resolution, and multi-temporal characteristics of remote sensing data. To address unique challenges in the field, multimodal geospatial foundation models (GFMs) have emerged as a dedicated research frontier. This survey delivers a comprehensive review of multimodal GFMs from a modality-driven perspective, covering five core visual and vision-language modalities. We examine how differences in imaging physics and data representation shape interaction design, and we analyze key techniques for alignment, integration, and knowledge transfer to tackle modality heterogeneity, distribution shifts, and semantic gaps. Advances in training paradigms, architectures, and task-specific adaptation strategies are systematically assessed alongside a wealth of emerging benchmarks. Representative multimodal visual and vision-language GFMs are evaluated across ten downstream tasks, with insights into their architectures, performance, and application scenarios. Real-world case studies, spanning land cover mapping, agricultural monitoring, disaster response, climate studies, and geospatial intelligence, demonstrate the practical potential of GFMs. Finally, we outline pressing challenges in domain generalization, interpretability, efficiency, and privacy, and chart promising avenues for future research.
Residual Diffusion Bridge Model for Image Restoration
Oct 27, 2025Diffusion bridge models establish probabilistic paths between arbitrary paired distributions and exhibit great potential for universal image restoration. Most existing methods merely treat them as simple variants of stochastic interpolants, lacking a unified analytical perspective. Besides, they indiscriminately reconstruct images through global noise injection and removal, inevitably distorting undegraded regions due to imperfect reconstruction. To address these challenges, we propose the Residual Diffusion Bridge Model (RDBM). Specifically, we theoretically reformulate the stochastic differential equations of generalized diffusion bridge and derive the analytical formulas of its forward and reverse processes. Crucially, we leverage the residuals from given distributions to modulate the noise injection and removal, enabling adaptive restoration of degraded regions while preserving intact others. Moreover, we unravel the fundamental mathematical essence of existing bridge models, all of which are special cases of RDBM and empirically demonstrate the optimality of our proposed models. Extensive experiments are conducted to demonstrate the state-of-the-art performance of our method both qualitatively and quantitatively across diverse image restoration tasks. Code is publicly available at https://github.com/MiliLab/RDBM.
DistillMatch: Leveraging Knowledge Distillation from Vision Foundation Model for Multimodal Image Matching
Sep 19, 2025Multimodal image matching seeks pixel-level correspondences between images of different modalities, crucial for cross-modal perception, fusion and analysis. However, the significant appearance differences between modalities make this task challenging. Due to the scarcity of high-quality annotated datasets, existing deep learning methods that extract modality-common features for matching perform poorly and lack adaptability to diverse scenarios. Vision Foundation Model (VFM), trained on large-scale data, yields generalizable and robust feature representations adapted to data and tasks of various modalities, including multimodal matching. Thus, we propose DistillMatch, a multimodal image matching method using knowledge distillation from VFM. DistillMatch employs knowledge distillation to build a lightweight student model that extracts high-level semantic features from VFM (including DINOv2 and DINOv3) to assist matching across modalities. To retain modality-specific information, it extracts and injects modality category information into the other modality's features, which enhances the model's understanding of cross-modal correlations. Furthermore, we design V2I-GAN to boost the model's generalization by translating visible to pseudo-infrared images for data augmentation. Experiments show that DistillMatch outperforms existing algorithms on public datasets.
TemCoCo: Temporally Consistent Multi-modal Video Fusion with Visual-Semantic Collaboration
Aug 25, 2025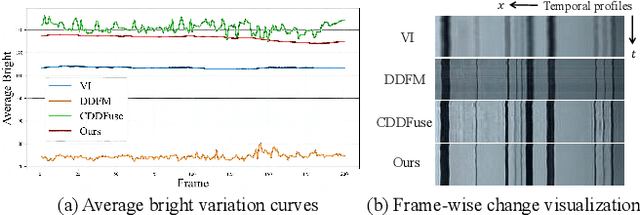
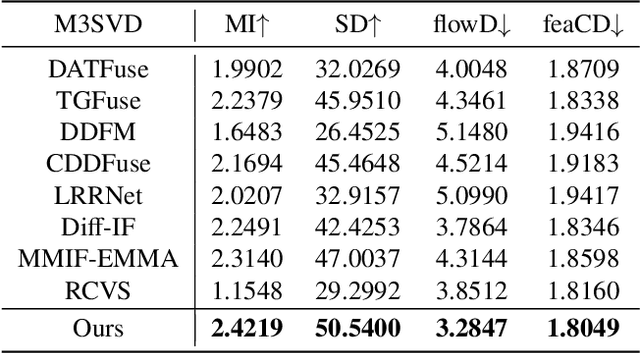
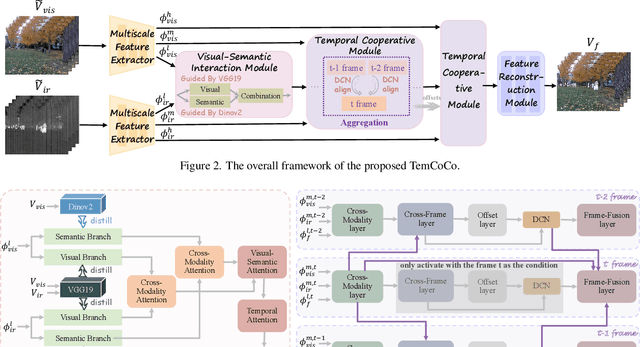
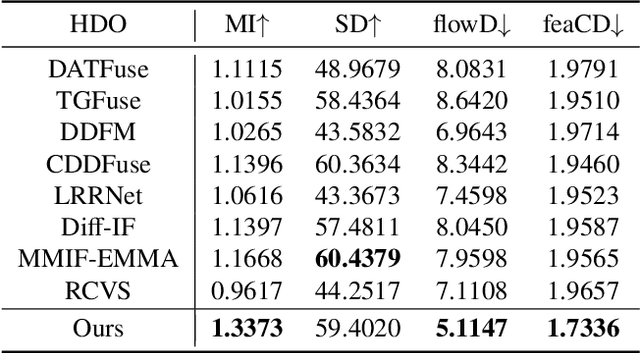
Existing multi-modal fusion methods typically apply static frame-based image fusion techniques directly to video fusion tasks, neglecting inherent temporal dependencies and leading to inconsistent results across frames. To address this limitation, we propose the first video fusion framework that explicitly incorporates temporal modeling with visual-semantic collaboration to simultaneously ensure visual fidelity, semantic accuracy, and temporal consistency. First, we introduce a visual-semantic interaction module consisting of a semantic branch and a visual branch, with Dinov2 and VGG19 employed for targeted distillation, allowing simultaneous enhancement of both the visual and semantic representations. Second, we pioneer integrate the video degradation enhancement task into the video fusion pipeline by constructing a temporal cooperative module, which leverages temporal dependencies to facilitate weak information recovery. Third, to ensure temporal consistency, we embed a temporal-enhanced mechanism into the network and devise a temporal loss to guide the optimization process. Finally, we introduce two innovative evaluation metrics tailored for video fusion, aimed at assessing the temporal consistency of the generated fused videos. Extensive experimental results on public video datasets demonstrate the superiority of our method. Our code is released at https://github.com/Meiqi-Gong/TemCoCo.
Towards Perfection: Building Inter-component Mutual Correction for Retinex-based Low-light Image Enhancement
Aug 12, 2025In low-light image enhancement, Retinex-based deep learning methods have garnered significant attention due to their exceptional interpretability. These methods decompose images into mutually independent illumination and reflectance components, allows each component to be enhanced separately. In fact, achieving perfect decomposition of illumination and reflectance components proves to be quite challenging, with some residuals still existing after decomposition. In this paper, we formally name these residuals as inter-component residuals (ICR), which has been largely underestimated by previous methods. In our investigation, ICR not only affects the accuracy of the decomposition but also causes enhanced components to deviate from the ideal outcome, ultimately reducing the final synthesized image quality. To address this issue, we propose a novel Inter-correction Retinex model (IRetinex) to alleviate ICR during the decomposition and enhancement stage. In the decomposition stage, we leverage inter-component residual reduction module to reduce the feature similarity between illumination and reflectance components. In the enhancement stage, we utilize the feature similarity between the two components to detect and mitigate the impact of ICR within each enhancement unit. Extensive experiments on three low-light benchmark datasets demonstrated that by reducing ICR, our method outperforms state-of-the-art approaches both qualitatively and quantitatively.
GeoMoE: Divide-and-Conquer Motion Field Modeling with Mixture-of-Experts for Two-View Geometry
Aug 01, 2025Recent progress in two-view geometry increasingly emphasizes enforcing smoothness and global consistency priors when estimating motion fields between pairs of images. However, in complex real-world scenes, characterized by extreme viewpoint and scale changes as well as pronounced depth discontinuities, the motion field often exhibits diverse and heterogeneous motion patterns. Most existing methods lack targeted modeling strategies and fail to explicitly account for this variability, resulting in estimated motion fields that diverge from their true underlying structure and distribution. We observe that Mixture-of-Experts (MoE) can assign dedicated experts to motion sub-fields, enabling a divide-and-conquer strategy for heterogeneous motion patterns. Building on this insight, we re-architect motion field modeling in two-view geometry with GeoMoE, a streamlined framework. Specifically, we first devise a Probabilistic Prior-Guided Decomposition strategy that exploits inlier probability signals to perform a structure-aware decomposition of the motion field into heterogeneous sub-fields, sharply curbing outlier-induced bias. Next, we introduce an MoE-Enhanced Bi-Path Rectifier that enhances each sub-field along spatial-context and channel-semantic paths and routes it to a customized expert for targeted modeling, thereby decoupling heterogeneous motion regimes, suppressing cross-sub-field interference and representational entanglement, and yielding fine-grained motion-field rectification. With this minimalist design, GeoMoE outperforms prior state-of-the-art methods in relative pose and homography estimation and shows strong generalization. The source code and pre-trained models are available at https://github.com/JiajunLe/GeoMoE.
Deep Learning Reforms Image Matching: A Survey and Outlook
Jun 05, 2025Image matching, which establishes correspondences between two-view images to recover 3D structure and camera geometry, serves as a cornerstone in computer vision and underpins a wide range of applications, including visual localization, 3D reconstruction, and simultaneous localization and mapping (SLAM). Traditional pipelines composed of ``detector-descriptor, feature matcher, outlier filter, and geometric estimator'' falter in challenging scenarios. Recent deep-learning advances have significantly boosted both robustness and accuracy. This survey adopts a unique perspective by comprehensively reviewing how deep learning has incrementally transformed the classical image matching pipeline. Our taxonomy highly aligns with the traditional pipeline in two key aspects: i) the replacement of individual steps in the traditional pipeline with learnable alternatives, including learnable detector-descriptor, outlier filter, and geometric estimator; and ii) the merging of multiple steps into end-to-end learnable modules, encompassing middle-end sparse matcher, end-to-end semi-dense/dense matcher, and pose regressor. We first examine the design principles, advantages, and limitations of both aspects, and then benchmark representative methods on relative pose recovery, homography estimation, and visual localization tasks. Finally, we discuss open challenges and outline promising directions for future research. By systematically categorizing and evaluating deep learning-driven strategies, this survey offers a clear overview of the evolving image matching landscape and highlights key avenues for further innovation.
DGSolver: Diffusion Generalist Solver with Universal Posterior Sampling for Image Restoration
Apr 30, 2025Diffusion models have achieved remarkable progress in universal image restoration. While existing methods speed up inference by reducing sampling steps, substantial step intervals often introduce cumulative errors. Moreover, they struggle to balance the commonality of degradation representations and restoration quality. To address these challenges, we introduce \textbf{DGSolver}, a diffusion generalist solver with universal posterior sampling. We first derive the exact ordinary differential equations for generalist diffusion models and tailor high-order solvers with a queue-based accelerated sampling strategy to improve both accuracy and efficiency. We then integrate universal posterior sampling to better approximate manifold-constrained gradients, yielding a more accurate noise estimation and correcting errors in inverse inference. Extensive experiments show that DGSolver outperforms state-of-the-art methods in restoration accuracy, stability, and scalability, both qualitatively and quantitatively. Code and models will be available at https://github.com/MiliLab/DGSolver.
Robust Fusion Controller: Degradation-aware Image Fusion with Fine-grained Language Instructions
Apr 09, 2025Current image fusion methods struggle to adapt to real-world environments encompassing diverse degradations with spatially varying characteristics. To address this challenge, we propose a robust fusion controller (RFC) capable of achieving degradation-aware image fusion through fine-grained language instructions, ensuring its reliable application in adverse environments. Specifically, RFC first parses language instructions to innovatively derive the functional condition and the spatial condition, where the former specifies the degradation type to remove, while the latter defines its spatial coverage. Then, a composite control priori is generated through a multi-condition coupling network, achieving a seamless transition from abstract language instructions to latent control variables. Subsequently, we design a hybrid attention-based fusion network to aggregate multi-modal information, in which the obtained composite control priori is deeply embedded to linearly modulate the intermediate fused features. To ensure the alignment between language instructions and control outcomes, we introduce a novel language-feature alignment loss, which constrains the consistency between feature-level gains and the composite control priori. Extensive experiments on publicly available datasets demonstrate that our RFC is robust against various composite degradations, particularly in highly challenging flare scenarios.