 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicFuse: Single Image Fusion for Visual and Semantic Reinforcement
Feb 02, 2026This paper focuses on a highly practical scenario: how to continue benefiting from the advantages of multi-modal image fusion under harsh conditions when only visible imaging sensors are available. To achieve this goal, we propose a novel concept of single-image fusion, which extends conventional data-level fusion to the knowledge level. Specifically, we develop MagicFuse, a novel single image fusion framework capable of deriving a comprehensive cross-spectral scene representation from a single low-quality visible image. MagicFuse first introduces an intra-spectral knowledge reinforcement branch and a cross-spectral knowledge generation branch based on the diffusion models. They mine scene information obscured in the visible spectrum and learn thermal radiation distribution patterns transferred to the infrared spectrum, respectively. Building on them, we design a multi-domain knowledge fusion branch that integrates the probabilistic noise from the diffusion streams of these two branches, from which a cross-spectral scene representation can be obtained through successive sampling. Then, we impose both visual and semantic constraints to ensure that this scene representation can satisfy human observation while supporting downstream semantic decision-making. Extensive experiments show that our MagicFuse achieves visual and semantic representation performance comparable to or even better than state-of-the-art fusion methods with multi-modal inputs, despite relying solely on a single degraded visible image.
TemCoCo: Temporally Consistent Multi-modal Video Fusion with Visual-Semantic Collaboration
Aug 25, 2025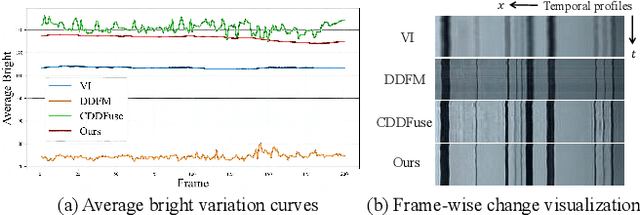
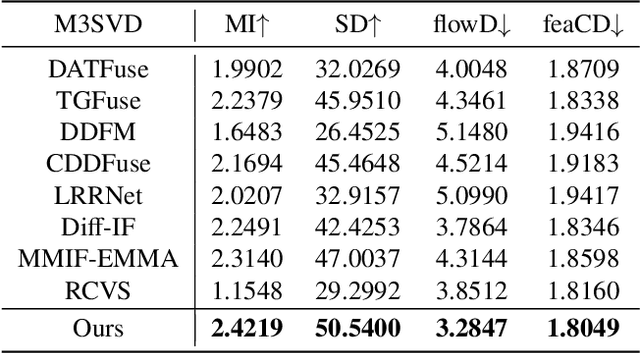
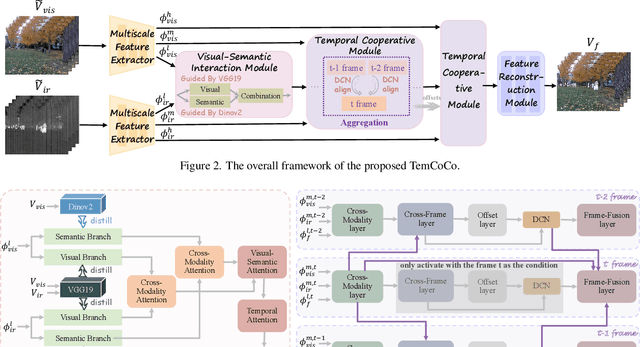
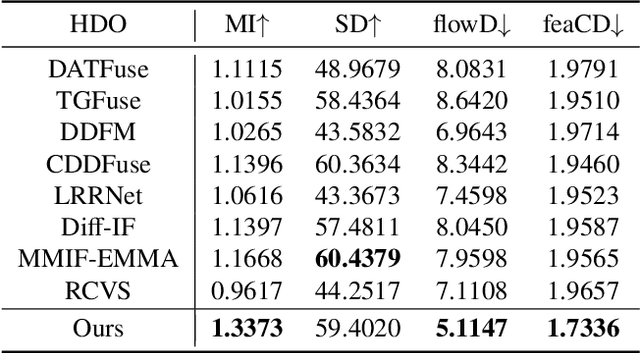
Existing multi-modal fusion methods typically apply static frame-based image fusion techniques directly to video fusion tasks, neglecting inherent temporal dependencies and leading to inconsistent results across frames. To address this limitation, we propose the first video fusion framework that explicitly incorporates temporal modeling with visual-semantic collaboration to simultaneously ensure visual fidelity, semantic accuracy, and temporal consistency. First, we introduce a visual-semantic interaction module consisting of a semantic branch and a visual branch, with Dinov2 and VGG19 employed for targeted distillation, allowing simultaneous enhancement of both the visual and semantic representations. Second, we pioneer integrate the video degradation enhancement task into the video fusion pipeline by constructing a temporal cooperative module, which leverages temporal dependencies to facilitate weak information recovery. Third, to ensure temporal consistency, we embed a temporal-enhanced mechanism into the network and devise a temporal loss to guide the optimization process. Finally, we introduce two innovative evaluation metrics tailored for video fusion, aimed at assessing the temporal consistency of the generated fused videos. Extensive experimental results on public video datasets demonstrate the superiority of our method. Our code is released at https://github.com/Meiqi-Gong/TemCoCo.
VideoFusion: A Spatio-Temporal Collaborative Network for Mutli-modal Video Fusion and Restoration
Mar 30, 2025Compared to images, videos better align with real-world acquisition scenarios and possess valuable temporal cues. However, existing multi-sensor fusion research predominantly integrates complementary context from multiple images rather than videos. This primarily stems from two factors: 1) the scarcity of large-scale multi-sensor video datasets, limiting research in video fusion, and 2) the inherent difficulty of jointly modeling spatial and temporal dependencies in a unified framework. This paper proactively compensates for the dilemmas. First, we construct M3SVD, a benchmark dataset with $220$ temporally synchronized and spatially registered infrared-visible video pairs comprising 153,797 frames, filling the data gap for the video fusion community. Secondly, we propose VideoFusion, a multi-modal video fusion model that fully exploits cross-modal complementarity and temporal dynamics to generate spatio-temporally coherent videos from (potentially degraded) multi-modal inputs. Specifically, 1) a differential reinforcement module is developed for cross-modal information interaction and enhancement, 2) a complete modality-guided fusion strategy is employed to adaptively integrate multi-modal features, and 3) a bi-temporal co-attention mechanism is devised to dynamically aggregate forward-backward temporal contexts to reinforce cross-frame feature representations. Extensive experiments reveal that VideoFusion outperforms existing image-oriented fusion paradigms in sequential scenarios, effectively mitigating temporal inconsistency and interference.