 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Reforms Image Matching: A Survey and Outlook
Jun 05, 2025Image matching, which establishes correspondences between two-view images to recover 3D structure and camera geometry, serves as a cornerstone in computer vision and underpins a wide range of applications, including visual localization, 3D reconstruction, and simultaneous localization and mapping (SLAM). Traditional pipelines composed of ``detector-descriptor, feature matcher, outlier filter, and geometric estimator'' falter in challenging scenarios. Recent deep-learning advances have significantly boosted both robustness and accuracy. This survey adopts a unique perspective by comprehensively reviewing how deep learning has incrementally transformed the classical image matching pipeline. Our taxonomy highly aligns with the traditional pipeline in two key aspects: i) the replacement of individual steps in the traditional pipeline with learnable alternatives, including learnable detector-descriptor, outlier filter, and geometric estimator; and ii) the merging of multiple steps into end-to-end learnable modules, encompassing middle-end sparse matcher, end-to-end semi-dense/dense matcher, and pose regressor. We first examine the design principles, advantages, and limitations of both aspects, and then benchmark representative methods on relative pose recovery, homography estimation, and visual localization tasks. Finally, we discuss open challenges and outline promising directions for future research. By systematically categorizing and evaluating deep learning-driven strategies, this survey offers a clear overview of the evolving image matching landscape and highlights key avenues for further innovation.
VideoFusion: A Spatio-Temporal Collaborative Network for Mutli-modal Video Fusion and Restoration
Mar 30, 2025Compared to images, videos better align with real-world acquisition scenarios and possess valuable temporal cues. However, existing multi-sensor fusion research predominantly integrates complementary context from multiple images rather than videos. This primarily stems from two factors: 1) the scarcity of large-scale multi-sensor video datasets, limiting research in video fusion, and 2) the inherent difficulty of jointly modeling spatial and temporal dependencies in a unified framework. This paper proactively compensates for the dilemmas. First, we construct M3SVD, a benchmark dataset with $220$ temporally synchronized and spatially registered infrared-visible video pairs comprising 153,797 frames, filling the data gap for the video fusion community. Secondly, we propose VideoFusion, a multi-modal video fusion model that fully exploits cross-modal complementarity and temporal dynamics to generate spatio-temporally coherent videos from (potentially degraded) multi-modal inputs. Specifically, 1) a differential reinforcement module is developed for cross-modal information interaction and enhancement, 2) a complete modality-guided fusion strategy is employed to adaptively integrate multi-modal features, and 3) a bi-temporal co-attention mechanism is devised to dynamically aggregate forward-backward temporal contexts to reinforce cross-frame feature representations. Extensive experiments reveal that VideoFusion outperforms existing image-oriented fusion paradigms in sequential scenarios, effectively mitigating temporal inconsistency and interference.
Trusta: Reasoning about Assurance Cases with Formal Methods and Large Language Models
Sep 22, 2023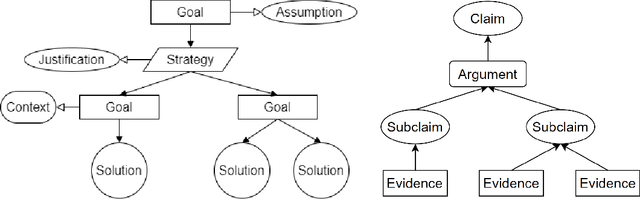



Assurance cases can be used to argue for the safety of products in safety engineering. In safety-critical areas, the construction of assurance cases is indispensable. Trustworthiness Derivation Trees (TDTs) enhance assurance cases by incorporating formal methods, rendering it possible for automatic reasoning about assurance cases. We present Trustworthiness Derivation Tree Analyzer (Trusta), a desktop application designed to automatically construct and verify TDTs. The tool has a built-in Prolog interpreter in its backend, and is supported by the constraint solvers Z3 and MONA. Therefore, it can solve constraints about logical formulas involving arithmetic, sets, Horn clauses etc. Trusta also utilizes large language models to make the creation and evaluation of assurance cases more convenient. It allows for interactive human examination and modification. We evaluated top language models like ChatGPT-3.5, ChatGPT-4, and PaLM 2 for generating assurance cases. Our tests showed a 50%-80% similarity between machine-generated and human-created cases. In addition, Trusta can extract formal constraints from text in natural languages, facilitating an easier interpretation and validation process. This extraction is subject to human review and correction, blending the best of automated efficiency with human insight. To our knowledge, this marks the first integration of large language models in automatic creating and reasoning about assurance cases, bringing a novel approach to a traditional challenge. Through several industrial case studies, Trusta has proven to quickly find some subtle issues that are typically missed in manual inspection, demonstrating its practical value in enhancing the assurance case development process.
ResMatch: Residual Attention Learning for Local Feature Matching
Jul 11, 2023



Attention-based graph neural networks have made great progress in feature matching learning. However, insight of how attention mechanism works for feature matching is lacked in the literature. In this paper, we rethink cross- and self-attention from the viewpoint of traditional feature matching and filtering. In order to facilitate the learning of matching and filtering, we inject the similarity of descriptors and relative positions into cross- and self-attention score, respectively. In this way, the attention can focus on learning residual matching and filtering functions with reference to the basic functions of measuring visual and spatial correlation. Moreover, we mine intra- and inter-neighbors according to the similarity of descriptors and relative positions. Then sparse attention for each point can be performed only within its neighborhoods to acquire higher computation efficiency. Feature matching networks equipped with our full and sparse residual attention learning strategies are termed ResMatch and sResMatch respectively. Extensive experiments, including feature matching, pose estimation and visual localization, confirm the superiority of our networks.
ReDFeat: Recoupling Detection and Description for Multimodal Feature Learning
May 16, 2022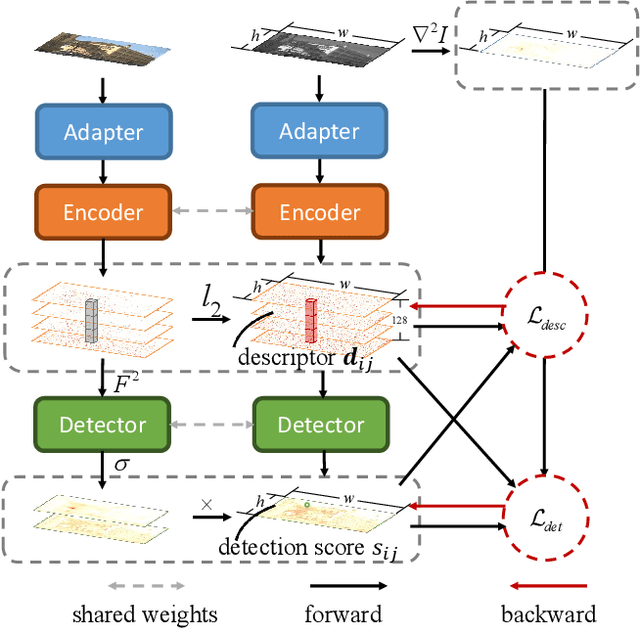


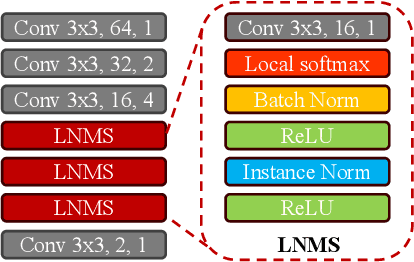
Deep-learning-based local feature extraction algorithms that combine detection and description have made significant progress in visible image matching. However, the end-to-end training of such frameworks is notoriously unstable due to the lack of strong supervision of detection and the inappropriate coupling between detection and description. The problem is magnified in cross-modal scenarios, in which most methods heavily rely on the pre-training. In this paper, we recouple independent constraints of detection and description of multimodal feature learning with a mutual weighting strategy, in which the detected probabilities of robust features are forced to peak and repeat, while features with high detection scores are emphasized during optimization. Different from previous works, those weights are detached from back propagation so that the detected probability of indistinct features would not be directly suppressed and the training would be more stable. Moreover, we propose the Super Detector, a detector that possesses a large receptive field and is equipped with learnable non-maximum suppression layers, to fulfill the harsh terms of detection. Finally, we build a benchmark that contains cross visible, infrared, near-infrared and synthetic aperture radar image pairs for evaluating the performance of features in feature matching and image registration tasks. Extensive experiments demonstrate that features trained with the recoulped detection and description, named ReDFeat, surpass previous state-of-the-arts in the benchmark, while the model can be readily trained from scratch.
SDGMNet: Statistic-based Dynamic Gradient Modulation for Local Descriptor Learning
Jun 09, 2021



Modifications on triplet loss that rescale the back-propagated gradients of special pairs have made significant progress on local descriptor learning. However, current gradient modulation strategies are mainly static so that they would suffer from changes of training phases or datasets. In this paper, we propose a dynamic gradient modulation, named SDGMNet, to improve triplet loss for local descriptor learning. The core of our method is formulating modulation functions with statistical characteristics which are estimated dynamically. Firstly, we perform deep analysis on back propagation of general triplet-based loss and introduce included angle for distance measure. On this basis, auto-focus modulation is employed to moderate the impact of statistically uncommon individual pairs in stochastic gradient descent optimization; probabilistic margin cuts off the gradients of proportional Siamese pairs that are believed to reach the optimum; power adjustment balances the total weights of negative pairs and positive pairs. Extensive experiments demonstrate that our novel descriptor surpasses previous state-of-the-arts on standard benchmarks including patch verification, matching and retrieval tasks.