 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReDFeat: Recoupling Detection and Description for Multimodal Feature Learning
Paper and Code
May 16, 2022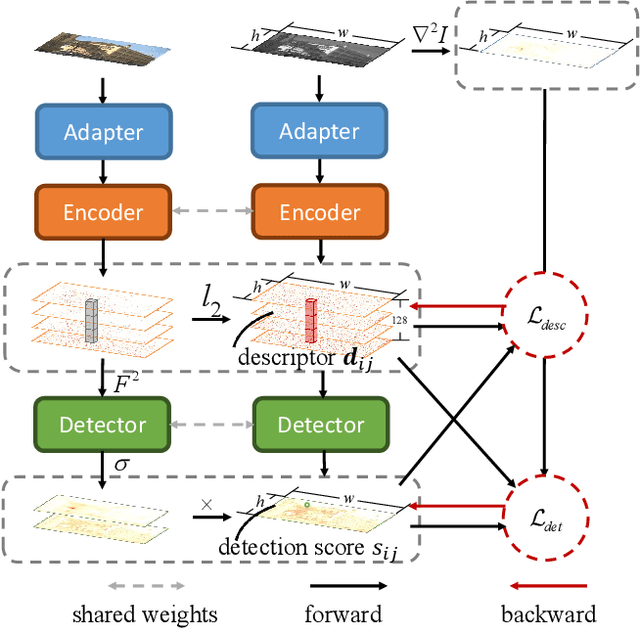


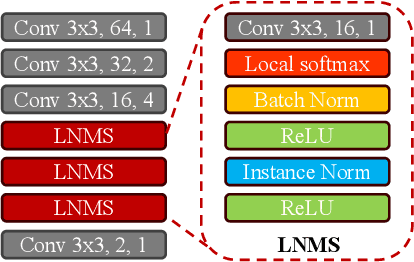
Deep-learning-based local feature extraction algorithms that combine detection and description have made significant progress in visible image matching. However, the end-to-end training of such frameworks is notoriously unstable due to the lack of strong supervision of detection and the inappropriate coupling between detection and description. The problem is magnified in cross-modal scenarios, in which most methods heavily rely on the pre-training. In this paper, we recouple independent constraints of detection and description of multimodal feature learning with a mutual weighting strategy, in which the detected probabilities of robust features are forced to peak and repeat, while features with high detection scores are emphasized during optimization. Different from previous works, those weights are detached from back propagation so that the detected probability of indistinct features would not be directly suppressed and the training would be more stable. Moreover, we propose the Super Detector, a detector that possesses a large receptive field and is equipped with learnable non-maximum suppression layers, to fulfill the harsh terms of detection. Finally, we build a benchmark that contains cross visible, infrared, near-infrared and synthetic aperture radar image pairs for evaluating the performance of features in feature matching and image registration tasks. Extensive experiments demonstrate that features trained with the recoulped detection and description, named ReDFeat, surpass previous state-of-the-arts in the benchmark, while the model can be readily trained from scratch.