 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemCoCo: Temporally Consistent Multi-modal Video Fusion with Visual-Semantic Collaboration
Aug 25, 2025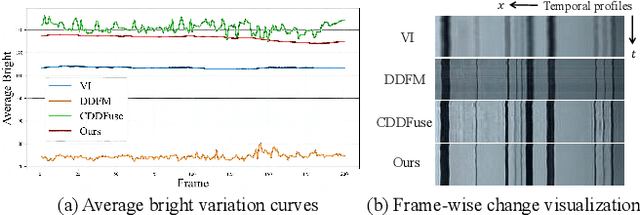
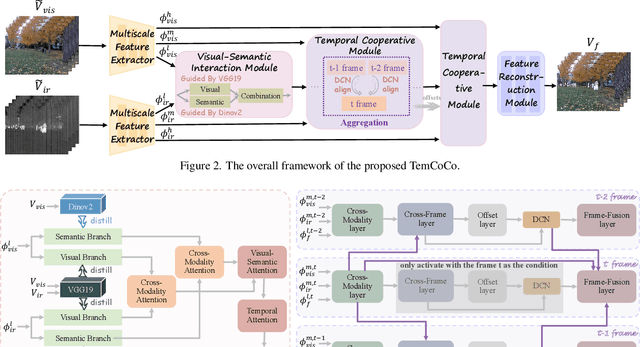
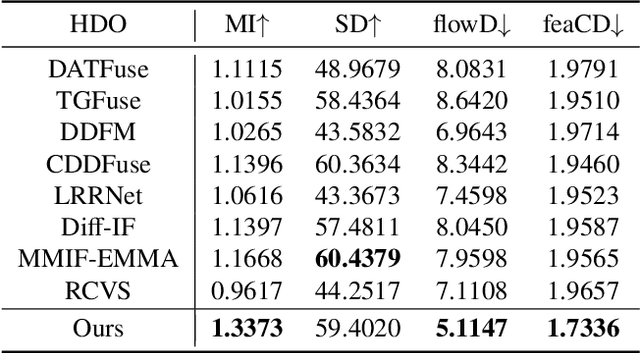
Existing multi-modal fusion methods typically apply static frame-based image fusion techniques directly to video fusion tasks, neglecting inherent temporal dependencies and leading to inconsistent results across frames. To address this limitation, we propose the first video fusion framework that explicitly incorporates temporal modeling with visual-semantic collaboration to simultaneously ensure visual fidelity, semantic accuracy, and temporal consistency. First, we introduce a visual-semantic interaction module consisting of a semantic branch and a visual branch, with Dinov2 and VGG19 employed for targeted distillation, allowing simultaneous enhancement of both the visual and semantic representations. Second, we pioneer integrate the video degradation enhancement task into the video fusion pipeline by constructing a temporal cooperative module, which leverages temporal dependencies to facilitate weak information recovery. Third, to ensure temporal consistency, we embed a temporal-enhanced mechanism into the network and devise a temporal loss to guide the optimization process. Finally, we introduce two innovative evaluation metrics tailored for video fusion, aimed at assessing the temporal consistency of the generated fused videos. Extensive experimental results on public video datasets demonstrate the superiority of our method. Our code is released at https://github.com/Meiqi-Gong/TemCoCo.
VideoFusion: A Spatio-Temporal Collaborative Network for Mutli-modal Video Fusion and Restoration
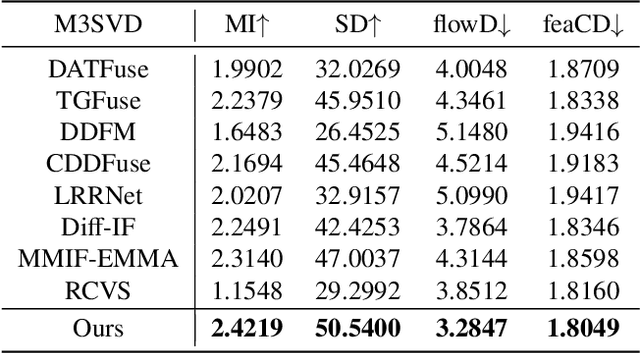
Mar 30, 2025Compared to images, videos better align with real-world acquisition scenarios and possess valuable temporal cues. However, existing multi-sensor fusion research predominantly integrates complementary context from multiple images rather than videos. This primarily stems from two factors: 1) the scarcity of large-scale multi-sensor video datasets, limiting research in video fusion, and 2) the inherent difficulty of jointly modeling spatial and temporal dependencies in a unified framework. This paper proactively compensates for the dilemmas. First, we construct M3SVD, a benchmark dataset with $220$ temporally synchronized and spatially registered infrared-visible video pairs comprising 153,797 frames, filling the data gap for the video fusion community. Secondly, we propose VideoFusion, a multi-modal video fusion model that fully exploits cross-modal complementarity and temporal dynamics to generate spatio-temporally coherent videos from (potentially degraded) multi-modal inputs. Specifically, 1) a differential reinforcement module is developed for cross-modal information interaction and enhancement, 2) a complete modality-guided fusion strategy is employed to adaptively integrate multi-modal features, and 3) a bi-temporal co-attention mechanism is devised to dynamically aggregate forward-backward temporal contexts to reinforce cross-frame feature representations. Extensive experiments reveal that VideoFusion outperforms existing image-oriented fusion paradigms in sequential scenarios, effectively mitigating temporal inconsistency and interference.
Text-IF: Leveraging Semantic Text Guidance for Degradation-Aware and Interactive Image Fusion
Mar 25, 2024



Image fusion aims to combine information from different source images to create a comprehensively representative image. Existing fusion methods are typically helpless in dealing with degradations in low-quality source images and non-interactive to multiple subjective and objective needs. To solve them, we introduce a novel approach that leverages semantic text guidance image fusion model for degradation-aware and interactive image fusion task, termed as Text-IF. It innovatively extends the classical image fusion to the text guided image fusion along with the ability to harmoniously address the degradation and interaction issues during fusion. Through the text semantic encoder and semantic interaction fusion decoder, Text-IF is accessible to the all-in-one infrared and visible image degradation-aware processing and the interactive flexible fusion outcomes. In this way, Text-IF achieves not only multi-modal image fusion, but also multi-modal information fusion. Extensive experiments prove that our proposed text guided image fusion strategy has obvious advantages over SOTA methods in the image fusion performance and degradation treatment. The code is available at https://github.com/XunpengYi/Text-IF.
Diff-Retinex: Rethinking Low-light Image Enhancement with A Generative Diffusion Model
Aug 25, 2023In this paper, we rethink the low-light image enhancement task and propose a physically explainable and generative diffusion model for low-light image enhancement, termed as Diff-Retinex. We aim to integrate the advantages of the physical model and the generative network. Furthermore, we hope to supplement and even deduce the information missing in the low-light image through the generative network. Therefore, Diff-Retinex formulates the low-light image enhancement problem into Retinex decomposition and conditional image generation. In the Retinex decomposition, we integrate the superiority of attention in Transformer and meticulously design a Retinex Transformer decomposition network (TDN) to decompose the image into illumination and reflectance maps. Then, we design multi-path generative diffusion networks to reconstruct the normal-light Retinex probability distribution and solve the various degradations in these components respectively, including dark illumination, noise, color deviation, loss of scene contents, etc. Owing to generative diffusion model, Diff-Retinex puts the restoration of low-light subtle detail into practice. Extensive experiments conducted on real-world low-light datasets qualitatively and quantitatively demonstrate the effectiveness, superiority, and generalization of the proposed method.