 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecDM: Hyperspectral Dataset Synthesis with Pixel-level Semantic Annotations
Feb 24, 2025In hyperspectral remote sensing field, some downstream dense prediction tasks, such as semantic segmentation (SS) and change detection (CD), rely on supervised learning to improve model performance and require a large amount of manually annotated data for training. However, due to the needs of specific equipment and special application scenarios, the acquisition and annotation of hyperspectral images (HSIs) are often costly and time-consuming. To this end, our work explores the potential of generative diffusion model in synthesizing HSIs with pixel-level annotations. The main idea is to utilize a two-stream VAE to learn the latent representations of images and corresponding masks respectively, learn their joint distribution during the diffusion model training, and finally obtain the image and mask through their respective decoders. To the best of our knowledge, it is the first work to generate high-dimensional HSIs with annotations. Our proposed approach can be applied in various kinds of dataset generation. We select two of the most widely used dense prediction tasks: semantic segmentation and change detection, and generate datasets suitable for these tasks. Experiments demonstrate that our synthetic datasets have a positive impact on the improvement of these downstream tasks.
HASA: Hybrid Architecture Search with Aggregation Strategy for Echinococcosis Classification and Ovary Segmentation in Ultrasound Images
Apr 20, 2022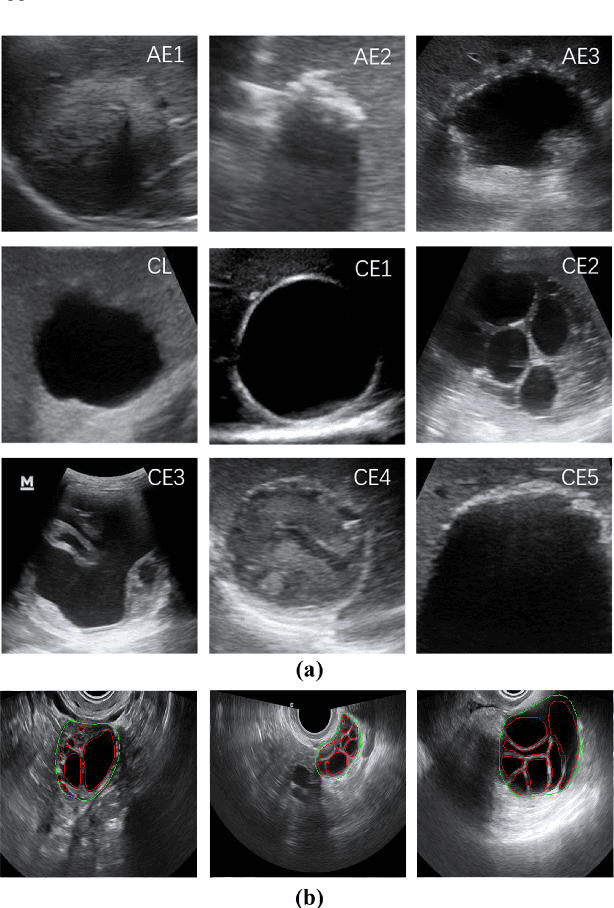
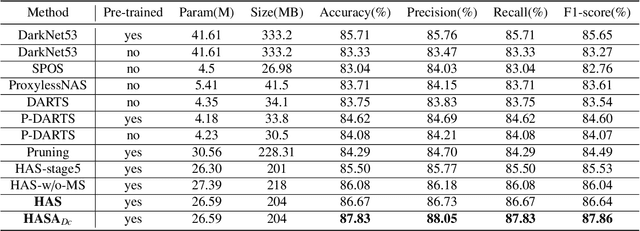
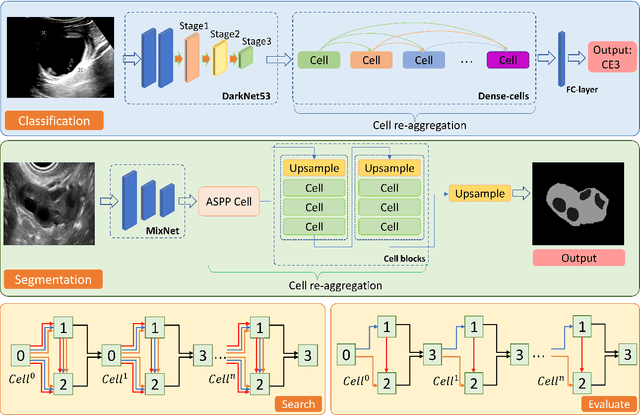
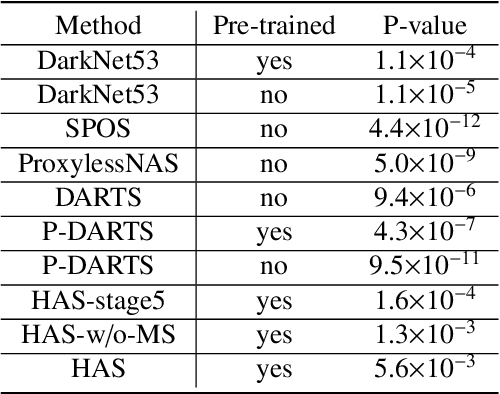
Different from handcrafted features, deep neural networks can automatically learn task-specific features from data. Due to this data-driven nature, they have achieved remarkable success in various areas. However, manual design and selection of suitable network architectures are time-consuming and require substantial effort of human experts. To address this problem, researchers have proposed neural architecture search (NAS) algorithms which can automatically generate network architectures but suffer from heavy computational cost and instability if searching from scratch. In this paper, we propose a hybrid NAS framework for ultrasound (US) image classification and segmentation. The hybrid framework consists of a pre-trained backbone and several searched cells (i.e., network building blocks), which takes advantage of the strengths of both NAS and the expert knowledge from existing convolutional neural networks. Specifically, two effective and lightweight operations, a mixed depth-wise convolution operator and a squeeze-and-excitation block, are introduced into the candidate operations to enhance the variety and capacity of the searched cells. These two operations not only decrease model parameters but also boost network performance. Moreover, we propose a re-aggregation strategy for the searched cells, aiming to further improve the performance for different vision tasks. We tested our method on two large US image datasets, including a 9-class echinococcosis dataset containing 9566 images for classification and an ovary dataset containing 3204 images for segmentation. Ablation experiments and comparison with other handcrafted or automatically searched architectures demonstrate that our method can generate more powerful and lightweight models for the above US image classification and segmentation tasks.