 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnostic Performance of Universal-Learning Ultrasound AI Across Multiple Organs and Tasks: the UUSIC25 Challenge
Dec 19, 2025IMPORTANCE: Current ultrasound AI remains fragmented into single-task tools, limiting clinical utility compared to versatile modern ultrasound systems. OBJECTIVE: To evaluate the diagnostic accuracy and efficiency of single general-purpose deep learning models for multi-organ classification and segmentation. DESIGN: The Universal UltraSound Image Challenge 2025 (UUSIC25) involved developing algorithms on 11,644 images (public/private). Evaluation used an independent, multi-center test set of 2,479 images, including data from a center completely unseen during training to assess generalization. OUTCOMES: Diagnostic performance (Dice Similarity Coefficient [DSC]; Area Under the Receiver Operating Characteristic Curve [AUC]) and computational efficiency (inference time, GPU memory). RESULTS: Of 15 valid algorithms, the top model (SMART) achieved a macro-averaged DSC of 0.854 across 5 segmentation tasks and AUC of 0.766 for binary classification. Models showed high capability in segmentation (e.g., fetal head DSC: 0.942) but variability in complex tasks subject to domain shift. Notably, in breast cancer molecular subtyping, the top model's performance dropped from AUC 0.571 (internal) to 0.508 (unseen external center), highlighting generalization challenges. CONCLUSIONS: General-purpose AI models achieve high accuracy and efficiency across multiple tasks using a single architecture. However, performance degradation on unseen data suggests domain generalization is critical for future clinical deployment.
S-DAG: A Subject-Based Directed Acyclic Graph for Multi-Agent Heterogeneous Reasoning
Nov 19, 2025Large Language Models (LLMs) have achieved impressive performance in complex reasoning problems. Their effectiveness highly depends on the specific nature of the task, especially the required domain knowledge. Existing approaches, such as mixture-of-experts, typically operate at the task level; they are too coarse to effectively solve the heterogeneous problems involving multiple subjects. This work proposes a novel framework that performs fine-grained analysis at subject level equipped with a designated multi-agent collaboration strategy for addressing heterogeneous problem reasoning. Specifically, given an input query, we first employ a Graph Neural Network to identify the relevant subjects and infer their interdependencies to generate an \textit{Subject-based Directed Acyclic Graph} (S-DAG), where nodes represent subjects and edges encode information flow. Then we profile the LLM models by assigning each model a subject-specific expertise score, and select the top-performing one for matching corresponding subject of the S-DAG. Such subject-model matching enables graph-structured multi-agent collaboration where information flows from the starting model to the ending model over S-DAG. We curate and release multi-subject subsets of standard benchmarks (MMLU-Pro, GPQA, MedMCQA) to better reflect complex, real-world reasoning tasks. Extensive experiments show that our approach significantly outperforms existing task-level model selection and multi-agent collaboration baselines in accuracy and efficiency. These results highlight the effectiveness of subject-aware reasoning and structured collaboration in addressing complex and multi-subject problems.
Hypothesis Testing for Progressive Kernel Estimation and VCM Framework
Apr 06, 2025



Identifying an appropriate radius for unbiased kernel estimation is crucial for the efficiency of radiance estimation. However, determining both the radius and unbiasedness still faces big challenges. In this paper, we first propose a statistical model of photon samples and associated contributions for progressive kernel estimation, under which the kernel estimation is unbiased if the null hypothesis of this statistical model stands. Then, we present a method to decide whether to reject the null hypothesis about the statistical population (i.e., photon samples) by the F-test in the Analysis of Variance. Hereby, we implement a progressive photon mapping (PPM) algorithm, wherein the kernel radius is determined by this hypothesis test for unbiased radiance estimation. Secondly, we propose VCM+, a reinforcement of Vertex Connection and Merging (VCM), and derive its theoretically unbiased formulation. VCM+ combines hypothesis testing-based PPM with bidirectional path tracing (BDPT) via multiple importance sampling (MIS), wherein our kernel radius can leverage the contributions from PPM and BDPT. We test our new algorithms, improved PPM and VCM+, on diverse scenarios with different lighting settings. The experimental results demonstrate that our method can alleviate light leaks and visual blur artifacts of prior radiance estimate algorithms. We also evaluate the asymptotic performance of our approach and observe an overall improvement over the baseline in all testing scenarios.
DeepUniUSTransformer: Towards A Universal UltraSound Model with Prompted Guidance
Jun 03, 2024Ultrasound is a widely used imaging modality in clinical practice due to its low cost, portability, and safety. Current research in general AI for healthcare focuses on large language models and general segmentation models, with insufficient attention to solutions addressing both disease prediction and tissue segmentation. In this study, we propose a novel universal framework for ultrasound, namely DeepUniUSTransformer, which is a promptable model accommodating multiple clinical task. The universality of this model is derived from its versatility across various aspects. It proficiently manages any ultrasound nature, any anatomical position, any input type and excelling not only in segmentation tasks but also in computer-aided diagnosis tasks. We introduce a novel module that incorporates this information as a prompt and seamlessly embedding it within the model's learning process. To train and validate our proposed model, we curated a comprehensive ultrasound dataset from publicly accessible sources, encompassing up to 7 distinct anatomical positions with over 9.7K annotations. Experimental results demonstrate that our model surpasses both a model trained on a single dataset and an ablated version of the network lacking prompt guidance. We will continuously expand the dataset and optimize the task specific prompting mechanism towards the universality in medical ultrasound. Model weights, datasets, and code will be open source to the public.
Explainable Molecular Property Prediction: Aligning Chemical Concepts with Predictions via Language Models
May 25, 2024



Providing explainable molecule property predictions is critical for many scientific domains, such as drug discovery and material science. Though transformer-based language models have shown great potential in accurate molecular property prediction, they neither provide chemically meaningful explanations nor faithfully reveal the molecular structure-property relationships. In this work, we develop a new framework for explainable molecular property prediction based on language models, dubbed as Lamole, which can provide chemical concepts-aligned explanations. We first leverage a designated molecular representation -- the Group SELFIES -- as it can provide chemically meaningful semantics. Because attention mechanisms in Transformers can inherently capture relationships within the input, we further incorporate the attention weights and gradients together to generate explanations for capturing the functional group interactions. We then carefully craft a marginal loss to explicitly optimize the explanations to be able to align with the chemists' annotations. We bridge the manifold hypothesis with the elaborated marginal loss to prove that the loss can align the explanations with the tangent space of the data manifold, leading to concept-aligned explanations. Experimental results over six mutagenicity datasets and one hepatotoxicity dataset demonstrate Lamole can achieve comparable classification accuracy and boost the explanation accuracy by up to 14.8%, being the state-of-the-art in explainable molecular property prediction.
Masked Video Modeling with Correlation-aware Contrastive Learning for Breast Cancer Diagnosis in Ultrasound
Aug 21, 2022

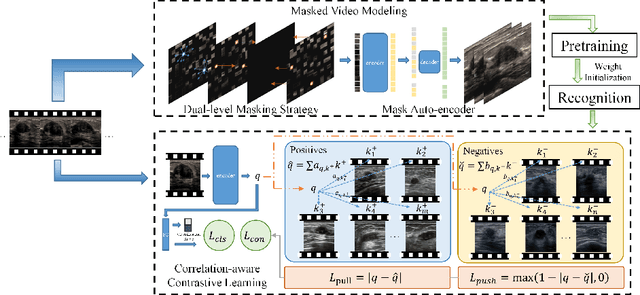
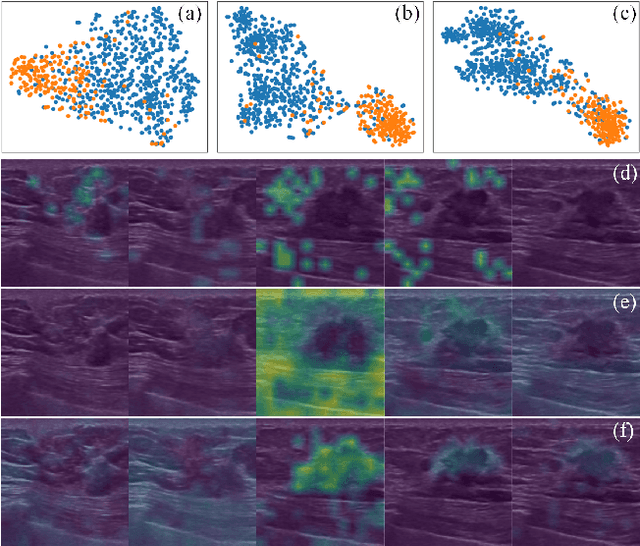
Breast cancer is one of the leading causes of cancer deaths in women. As the primary output of breast screening, breast ultrasound (US) video contains exclusive dynamic information for cancer diagnosis. However, training models for video analysis is non-trivial as it requires a voluminous dataset which is also expensive to annotate. Furthermore, the diagnosis of breast lesion faces unique challenges such as inter-class similarity and intra-class variation. In this paper, we propose a pioneering approach that directly utilizes US videos in computer-aided breast cancer diagnosis. It leverages masked video modeling as pretraning to reduce reliance on dataset size and detailed annotations. Moreover, a correlation-aware contrastive loss is developed to facilitate the identifying of the internal and external relationship between benign and malignant lesions. Experimental results show that our proposed approach achieved promising classification performance and can outperform other state-of-the-art methods.
Multi-Attribute Attention Network for Interpretable Diagnosis of Thyroid Nodules in Ultrasound Images
Jul 09, 2022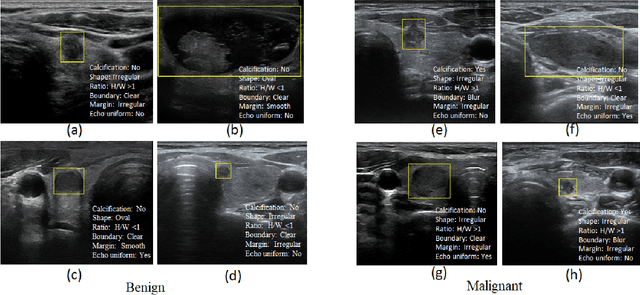
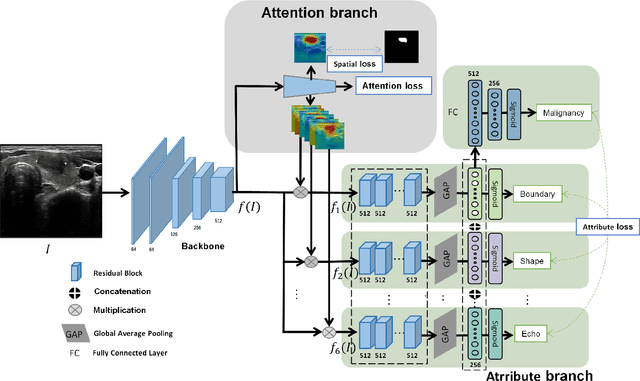
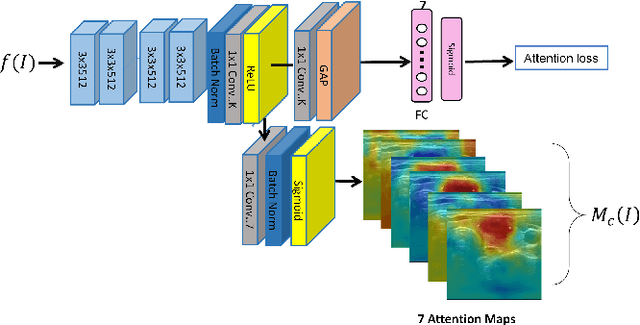
Ultrasound (US) is the primary imaging technique for the diagnosis of thyroid cancer. However, accurate identification of nodule malignancy is a challenging task that can elude less-experienced clinicians. Recently, many computer-aided diagnosis (CAD) systems have been proposed to assist this process. However, most of them do not provide the reasoning of their classification process, which may jeopardize their credibility in practical use. To overcome this, we propose a novel deep learning framework called multi-attribute attention network (MAA-Net) that is designed to mimic the clinical diagnosis process. The proposed model learns to predict nodular attributes and infer their malignancy based on these clinically-relevant features. A multi-attention scheme is adopted to generate customized attention to improve each task and malignancy diagnosis. Furthermore, MAA-Net utilizes nodule delineations as nodules spatial prior guidance for the training rather than cropping the nodules with additional models or human interventions to prevent losing the context information. Validation experiments were performed on a large and challenging dataset containing 4554 patients. Results show that the proposed method outperformed other state-of-the-art methods and provides interpretable predictions that may better suit clinical needs.
Weakly-supervised High-fidelity Ultrasound Video Synthesis with Feature Decoupling
Jul 01, 2022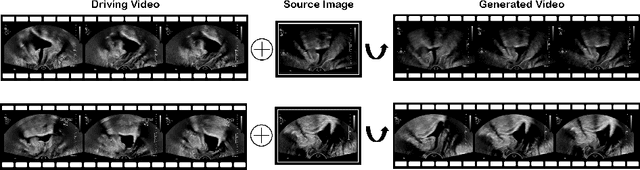
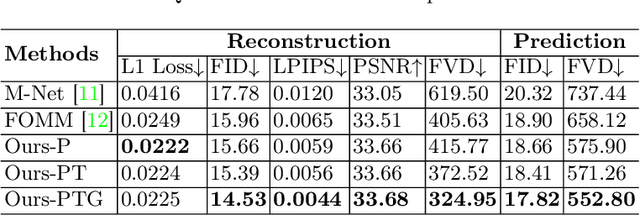
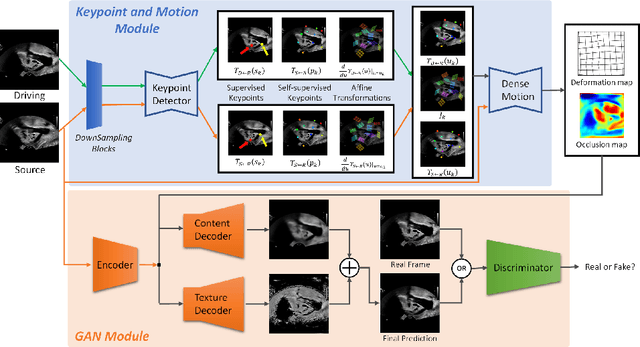

Ultrasound (US) is widely used for its advantages of real-time imaging, radiation-free and portability. In clinical practice, analysis and diagnosis often rely on US sequences rather than a single image to obtain dynamic anatomical information. This is challenging for novices to learn because practicing with adequate videos from patients is clinically unpractical. In this paper, we propose a novel framework to synthesize high-fidelity US videos. Specifically, the synthesis videos are generated by animating source content images based on the motion of given driving videos. Our highlights are three-fold. First, leveraging the advantages of self- and fully-supervised learning, our proposed system is trained in weakly-supervised manner for keypoint detection. These keypoints then provide vital information for handling complex high dynamic motions in US videos. Second, we decouple content and texture learning using the dual decoders to effectively reduce the model learning difficulty. Last, we adopt the adversarial training strategy with GAN losses for further improving the sharpness of the generated videos, narrowing the gap between real and synthesis videos. We validate our method on a large in-house pelvic dataset with high dynamic motion. Extensive evaluation metrics and user study prove the effectiveness of our proposed method.
HASA: Hybrid Architecture Search with Aggregation Strategy for Echinococcosis Classification and Ovary Segmentation in Ultrasound Images
Apr 20, 2022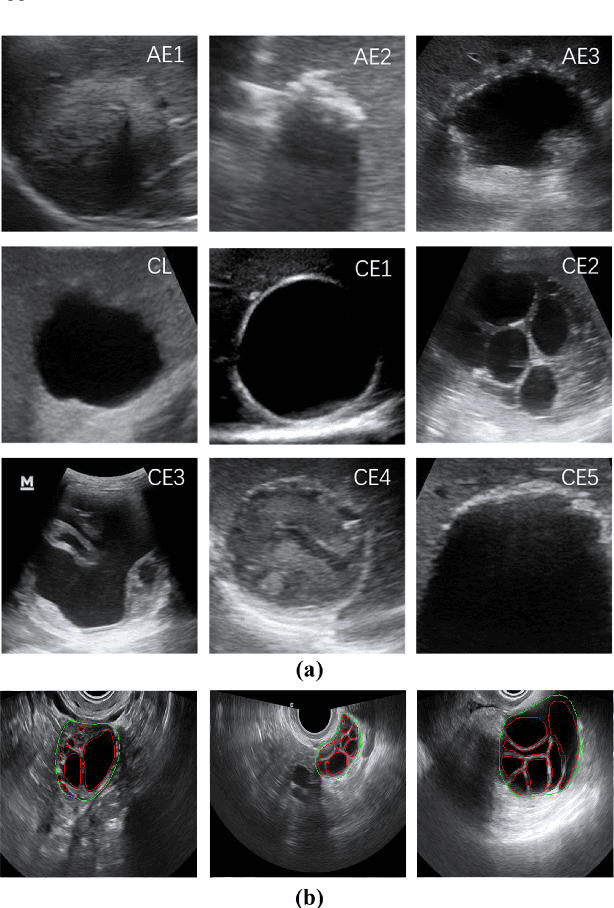
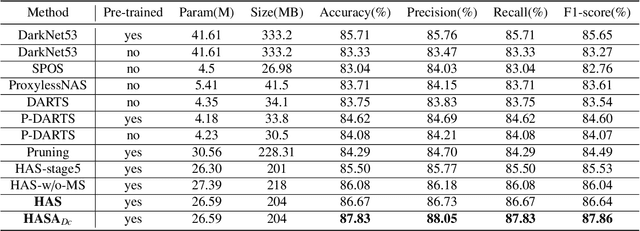
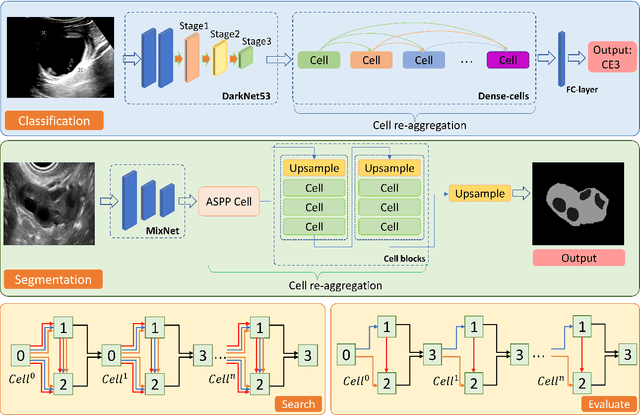
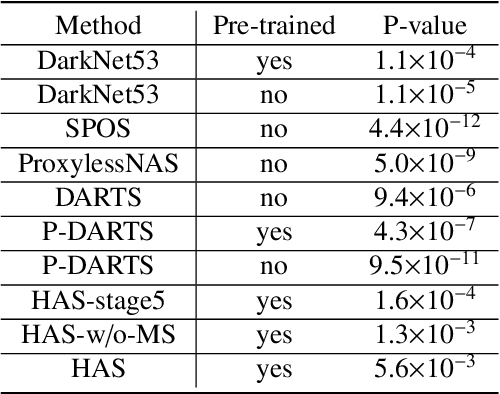
Different from handcrafted features, deep neural networks can automatically learn task-specific features from data. Due to this data-driven nature, they have achieved remarkable success in various areas. However, manual design and selection of suitable network architectures are time-consuming and require substantial effort of human experts. To address this problem, researchers have proposed neural architecture search (NAS) algorithms which can automatically generate network architectures but suffer from heavy computational cost and instability if searching from scratch. In this paper, we propose a hybrid NAS framework for ultrasound (US) image classification and segmentation. The hybrid framework consists of a pre-trained backbone and several searched cells (i.e., network building blocks), which takes advantage of the strengths of both NAS and the expert knowledge from existing convolutional neural networks. Specifically, two effective and lightweight operations, a mixed depth-wise convolution operator and a squeeze-and-excitation block, are introduced into the candidate operations to enhance the variety and capacity of the searched cells. These two operations not only decrease model parameters but also boost network performance. Moreover, we propose a re-aggregation strategy for the searched cells, aiming to further improve the performance for different vision tasks. We tested our method on two large US image datasets, including a 9-class echinococcosis dataset containing 9566 images for classification and an ovary dataset containing 3204 images for segmentation. Ablation experiments and comparison with other handcrafted or automatically searched architectures demonstrate that our method can generate more powerful and lightweight models for the above US image classification and segmentation tasks.
The Volctrans GLAT System: Non-autoregressive Translation Meets WMT21
Sep 24, 2021
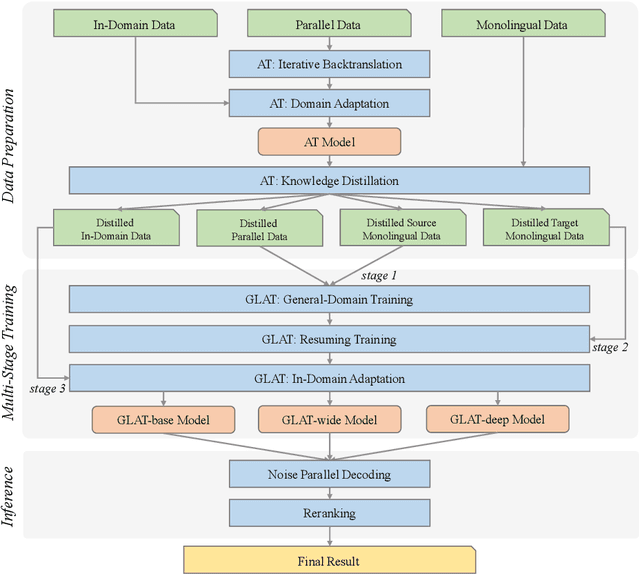
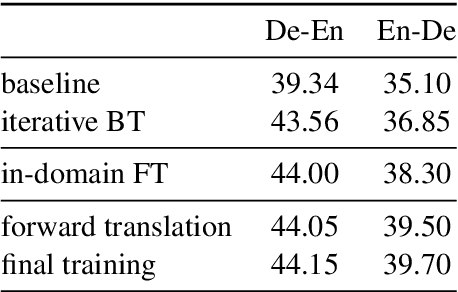
This paper describes the Volctrans' submission to the WMT21 news translation shared task for German->English translation. We build a parallel (i.e., non-autoregressive) translation system using the Glancing Transformer, which enables fast and accurate parallel decoding in contrast to the currently prevailing autoregressive models. To the best of our knowledge, this is the first parallel translation system that can be scaled to such a practical scenario like WMT competition. More importantly, our parallel translation system achieves the best BLEU score (35.0) on German->English translation task, outperforming all strong autoregressive counterparts.