 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency-Driven Dual LSTM Models for Kinematic Control of a Wearable Soft Robotic Arm
Mar 18, 2026In this paper, we introduce a consistency-driven dual LSTM framework for accurately learning both the forward and inverse kinematics of a pneumatically actuated soft robotic arm integrated into a wearable device. This approach effectively captures the nonlinear and hysteretic behaviors of soft pneumatic actuators while addressing the one-to-many mapping challenge between actuation inputs and end-effector positions. By incorporating a cycle consistency loss, we enhance physical realism and improve the stability of inverse predictions. Extensive experiments-including trajectory tracking, ablation studies, and wearable demonstrations-confirm the effectiveness of our method. Results indicate that the inclusion of the consistency loss significantly boosts prediction accuracy and promotes physical consistency over conventional approaches. Moreover, the wearable soft robotic arm demonstrates strong human-robot collaboration capabilities and adaptability in everyday tasks such as object handover, obstacle-aware pick-and-place, and drawer operation. This work underscores the promising potential of learning-based kinematic models for human-centric, wearable robotic systems.
Serving Large Language Models on Huawei CloudMatrix384
Jun 15, 2025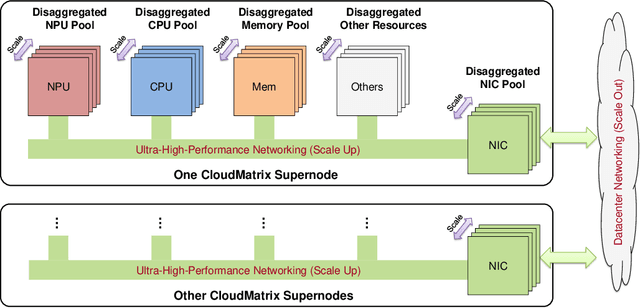
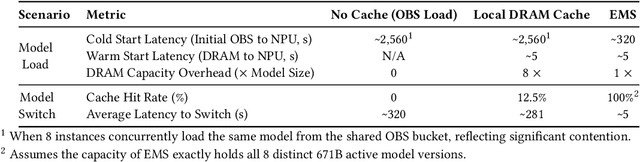
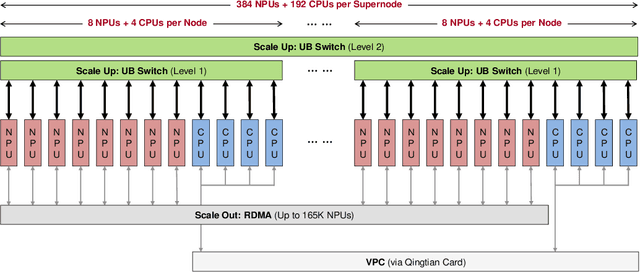
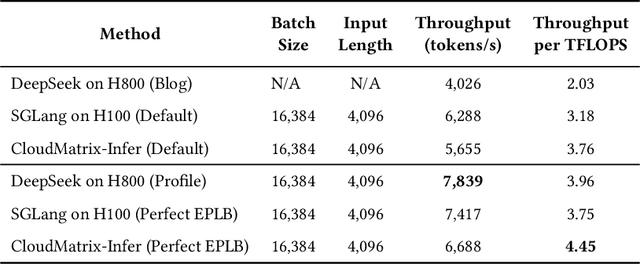
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
High-Throughput LLM inference on Heterogeneous Clusters
Apr 18, 2025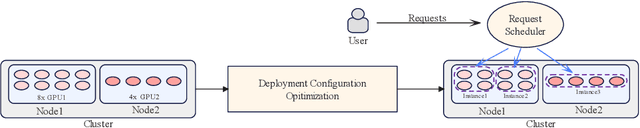


Nowadays, many companies possess various types of AI accelerators, forming heterogeneous clusters. Efficiently leveraging these clusters for high-throughput large language model (LLM) inference services can significantly reduce costs and expedite task processing. However, LLM inference on heterogeneous clusters presents two main challenges. Firstly, different deployment configurations can result in vastly different performance. The number of possible configurations is large, and evaluating the effectiveness of a specific setup is complex. Thus, finding an optimal configuration is not an easy task. Secondly, LLM inference instances within a heterogeneous cluster possess varying processing capacities, leading to different processing speeds for handling inference requests. Evaluating these capacities and designing a request scheduling algorithm that fully maximizes the potential of each instance is challenging. In this paper, we propose a high-throughput inference service system on heterogeneous clusters. First, the deployment configuration is optimized by modeling the resource amount and expected throughput and using the exhaustive search method. Second, a novel mechanism is proposed to schedule requests among instances, which fully considers the different processing capabilities of various instances. Extensive experiments show that the proposed scheduler improves throughput by 122.5% and 33.6% on two heterogeneous clusters, respectively.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
LayerKV: Optimizing Large Language Model Serving with Layer-wise KV Cache Management
Oct 01, 2024



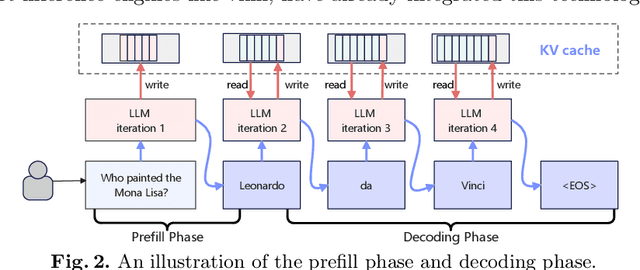
The expanding context windows in large language models (LLMs) have greatly enhanced their capabilities in various applications, but they also introduce significant challenges in maintaining low latency, particularly in Time to First Token (TTFT). This paper identifies that the sharp rise in TTFT as context length increases is predominantly driven by queuing delays, which are caused by the growing demands for GPU Key-Value (KV) cache allocation clashing with the limited availability of KV cache blocks. To address this issue, we propose LayerKV, a simple yet effective plug-in method that effectively reduces TTFT without requiring additional hardware or compromising output performance, while seamlessly integrating with existing parallelism strategies and scheduling techniques. Specifically, LayerKV introduces layer-wise KV block allocation, management, and offloading for fine-grained control over system memory, coupled with an SLO-aware scheduler to optimize overall Service Level Objectives (SLOs). Comprehensive evaluations on representative models, ranging from 7B to 70B parameters, across various GPU configurations, demonstrate that LayerKV improves TTFT latency up to 11x and reduces SLO violation rates by 28.7\%, significantly enhancing the user experience
No Algorithmic Collusion in Two-Player Blindfolded Game with Thompson Sampling
May 23, 2024

When two players are engaged in a repeated game with unknown payoff matrices, they may be completely unaware of the existence of each other and use multi-armed bandit algorithms to choose the actions, which is referred to as the ``blindfolded game'' in this paper. We show that when the players use Thompson sampling, the game dynamics converges to the Nash equilibrium under a mild assumption on the payoff matrices. Therefore, algorithmic collusion doesn't arise in this case despite the fact that the players do not intentionally deploy competitive strategies. To prove the convergence result, we find that the framework developed in stochastic approximation doesn't apply, because of the sporadic and infrequent updates of the inferior actions and the lack of Lipschitz continuity. We develop a novel sample-path-wise approach to show the convergence.
FetusMapV2: Enhanced Fetal Pose Estimation in 3D Ultrasound
Oct 30, 2023Fetal pose estimation in 3D ultrasound (US) involves identifying a set of associated fetal anatomical landmarks. Its primary objective is to provide comprehensive information about the fetus through landmark connections, thus benefiting various critical applications, such as biometric measurements, plane localization, and fetal movement monitoring. However, accurately estimating the 3D fetal pose in US volume has several challenges, including poor image quality, limited GPU memory for tackling high dimensional data, symmetrical or ambiguous anatomical structures, and considerable variations in fetal poses. In this study, we propose a novel 3D fetal pose estimation framework (called FetusMapV2) to overcome the above challenges. Our contribution is three-fold. First, we propose a heuristic scheme that explores the complementary network structure-unconstrained and activation-unreserved GPU memory management approaches, which can enlarge the input image resolution for better results under limited GPU memory. Second, we design a novel Pair Loss to mitigate confusion caused by symmetrical and similar anatomical structures. It separates the hidden classification task from the landmark localization task and thus progressively eases model learning. Last, we propose a shape priors-based self-supervised learning by selecting the relatively stable landmarks to refine the pose online. Extensive experiments and diverse applications on a large-scale fetal US dataset including 1000 volumes with 22 landmarks per volume demonstrate that our method outperforms other strong competitors.
SESNet: sequence-structure feature-integrated deep learning method for data-efficient protein engineering
Dec 29, 2022Deep learning has been widely used for protein engineering. However, it is limited by the lack of sufficient experimental data to train an accurate model for predicting the functional fitness of high-order mutants. Here, we develop SESNet, a supervised deep-learning model to predict the fitness for protein mutants by leveraging both sequence and structure information, and exploiting attention mechanism. Our model integrates local evolutionary context from homologous sequences, the global evolutionary context encoding rich semantic from the universal protein sequence space and the structure information accounting for the microenvironment around each residue in a protein. We show that SESNet outperforms state-of-the-art models for predicting the sequence-function relationship on 26 deep mutational scanning datasets. More importantly, we propose a data augmentation strategy by leveraging the data from unsupervised models to pre-train our model. After that, our model can achieve strikingly high accuracy in prediction of the fitness of protein mutants, especially for the higher order variants (> 4 mutation sites), when finetuned by using only a small number of experimental mutation data (<50). The strategy proposed is of great practical value as the required experimental effort, i.e., producing a few tens of experimental mutation data on a given protein, is generally affordable by an ordinary biochemical group and can be applied on almost any protein.
A Ligand-and-structure Dual-driven Deep Learning Method for the Discovery of Highly Potent GnRH1R Antagonist to treat Uterine Diseases
Jul 23, 2022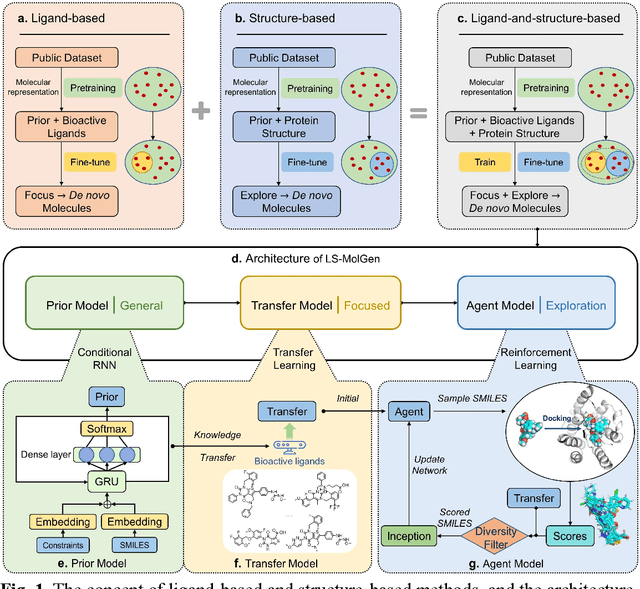
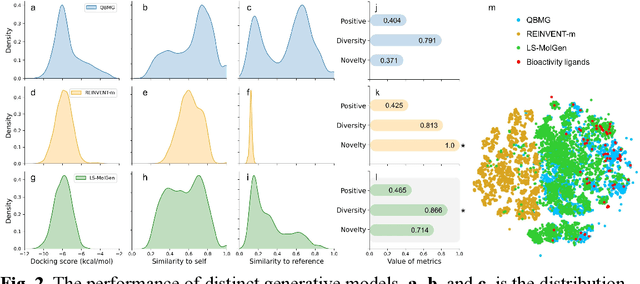
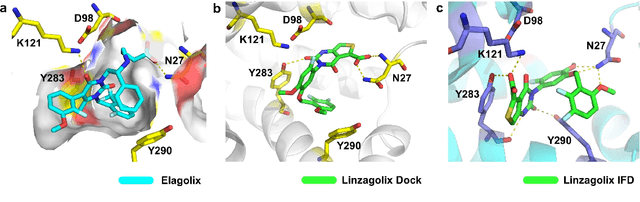
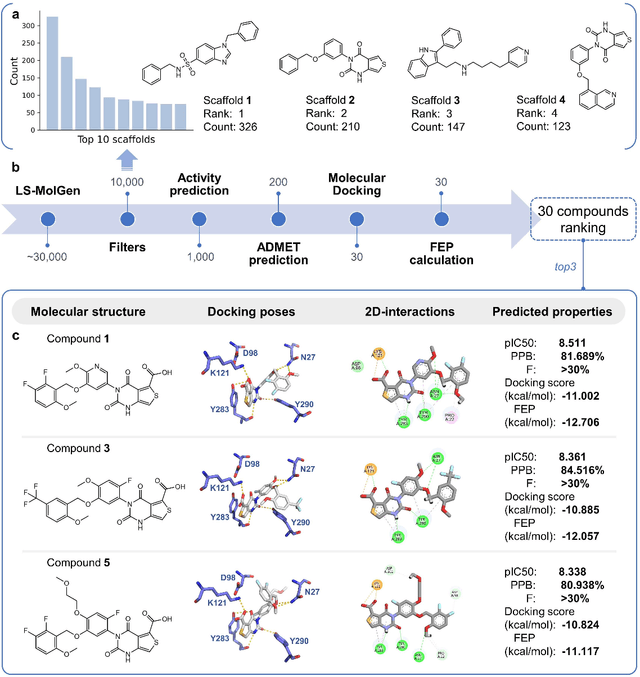
Gonadotrophin-releasing hormone receptor (GnRH1R) is a promising therapeutic target for the treatment of uterine diseases. To date, several GnRH1R antagonists are available in clinical investigation without satisfying multiple property constraints. To fill this gap, we aim to develop a deep learning-based framework to facilitate the effective and efficient discovery of a new orally active small-molecule drug targeting GnRH1R with desirable properties. In the present work, a ligand-and-structure combined model, namely LS-MolGen, was firstly proposed for molecular generation by fully utilizing the information on the known active compounds and the structure of the target protein, which was demonstrated by its superior performance than ligand- or structure-based methods separately. Then, a in silico screening including activity prediction, ADMET evaluation, molecular docking and FEP calculation was conducted, where ~30,000 generated novel molecules were narrowed down to 8 for experimental synthesis and validation. In vitro and in vivo experiments showed that three of them exhibited potent inhibition activities (compound 5 IC50 = 0.856 nM, compound 6 IC50 = 0.901 nM, compound 7 IC50 = 2.54 nM) against GnRH1R, and compound 5 performed well in fundamental PK properties, such as half-life, oral bioavailability, and PPB, etc. We believed that the proposed ligand-and-structure combined molecular generative model and the whole computer-aided workflow can potentially be extended to similar tasks for de novo drug design or lead optimization.
Weakly-supervised High-fidelity Ultrasound Video Synthesis with Feature Decoupling
Jul 01, 2022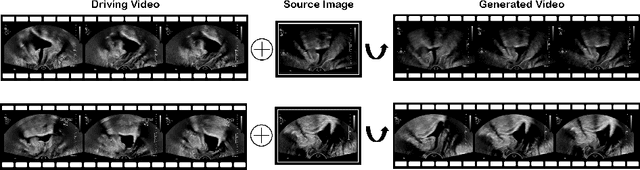
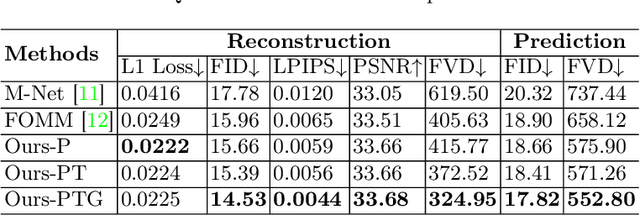
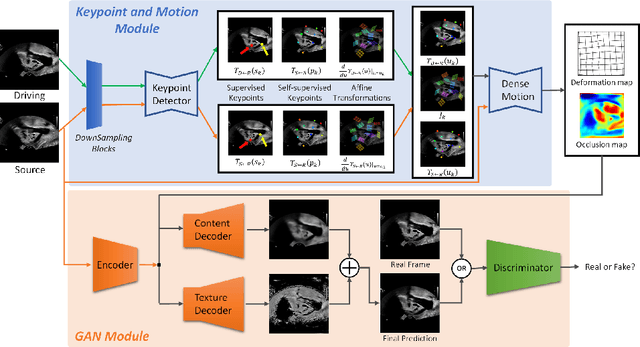

Ultrasound (US) is widely used for its advantages of real-time imaging, radiation-free and portability. In clinical practice, analysis and diagnosis often rely on US sequences rather than a single image to obtain dynamic anatomical information. This is challenging for novices to learn because practicing with adequate videos from patients is clinically unpractical. In this paper, we propose a novel framework to synthesize high-fidelity US videos. Specifically, the synthesis videos are generated by animating source content images based on the motion of given driving videos. Our highlights are three-fold. First, leveraging the advantages of self- and fully-supervised learning, our proposed system is trained in weakly-supervised manner for keypoint detection. These keypoints then provide vital information for handling complex high dynamic motions in US videos. Second, we decouple content and texture learning using the dual decoders to effectively reduce the model learning difficulty. Last, we adopt the adversarial training strategy with GAN losses for further improving the sharpness of the generated videos, narrowing the gap between real and synthesis videos. We validate our method on a large in-house pelvic dataset with high dynamic motion. Extensive evaluation metrics and user study prove the effectiveness of our proposed method.