 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Skill-based Safe Reinforcement Learning with Risk Planning
May 02, 2025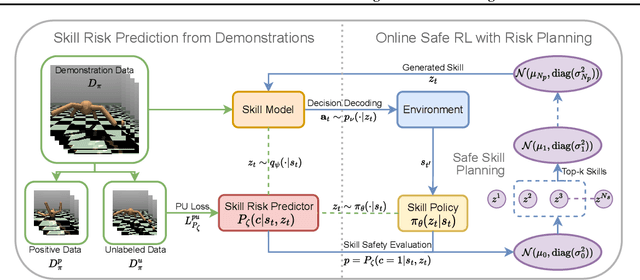
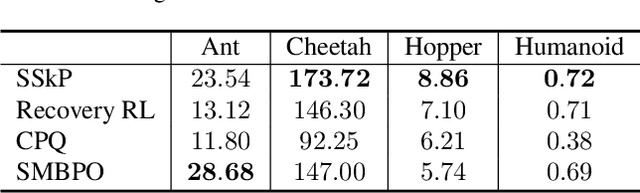


Safe Reinforcement Learning (Safe RL) aims to ensure safety when an RL agent conducts learning by interacting with real-world environments where improper actions can induce high costs or lead to severe consequences. In this paper, we propose a novel Safe Skill Planning (SSkP) approach to enhance effective safe RL by exploiting auxiliary offline demonstration data. SSkP involves a two-stage process. First, we employ PU learning to learn a skill risk predictor from the offline demonstration data. Then, based on the learned skill risk predictor, we develop a novel risk planning process to enhance online safe RL and learn a risk-averse safe policy efficiently through interactions with the online RL environment, while simultaneously adapting the skill risk predictor to the environment. We conduct experiments in several benchmark robotic simulation environments. The experimental results demonstrate that the proposed approach consistently outperforms previous state-of-the-art safe RL methods.
Context-Aware Self-Adaptation for Domain Generalization
Apr 03, 2025Domain generalization aims at developing suitable learning algorithms in source training domains such that the model learned can generalize well on a different unseen testing domain. We present a novel two-stage approach called Context-Aware Self-Adaptation (CASA) for domain generalization. CASA simulates an approximate meta-generalization scenario and incorporates a self-adaptation module to adjust pre-trained meta source models to the meta-target domains while maintaining their predictive capability on the meta-source domains. The core concept of self-adaptation involves leveraging contextual information, such as the mean of mini-batch features, as domain knowledge to automatically adapt a model trained in the first stage to new contexts in the second stage. Lastly, we utilize an ensemble of multiple meta-source models to perform inference on the testing domain. Experimental results demonstrate that our proposed method achieves state-of-the-art performance on standard benchmarks.
Zero-Shot Action Generalization with Limited Observations
Mar 11, 2025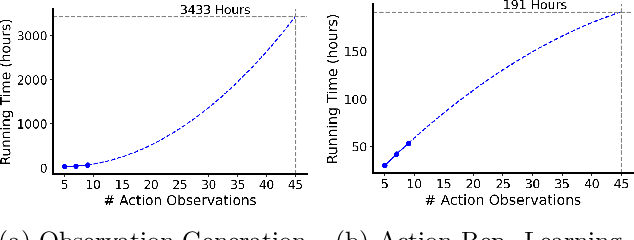
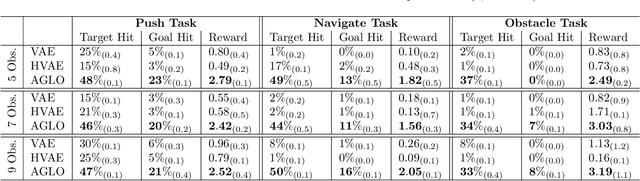
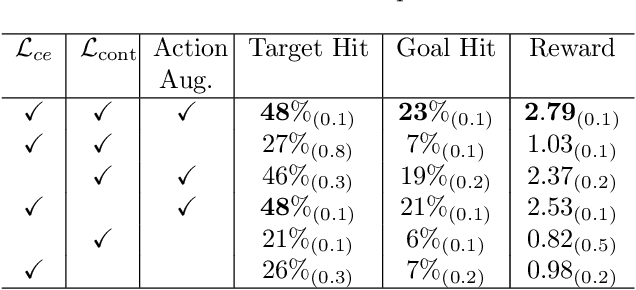
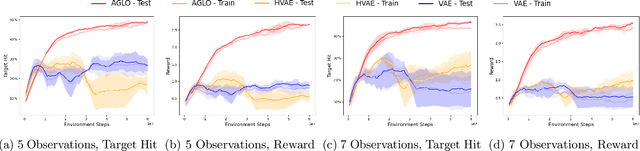
Reinforcement Learning (RL) has demonstrated remarkable success in solving sequential decision-making problems. However, in real-world scenarios, RL agents often struggle to generalize when faced with unseen actions that were not encountered during training. Some previous works on zero-shot action generalization rely on large datasets of action observations to capture the behaviors of new actions, making them impractical for real-world applications. In this paper, we introduce a novel zero-shot framework, Action Generalization from Limited Observations (AGLO). Our framework has two main components: an action representation learning module and a policy learning module. The action representation learning module extracts discriminative embeddings of actions from limited observations, while the policy learning module leverages the learned action representations, along with augmented synthetic action representations, to learn a policy capable of handling tasks with unseen actions. The experimental results demonstrate that our framework significantly outperforms state-of-the-art methods for zero-shot action generalization across multiple benchmark tasks, showcasing its effectiveness in generalizing to new actions with minimal action observations.
Single Domain Generalization with Adversarial Memory
Mar 08, 2025



Domain Generalization (DG) aims to train models that can generalize to unseen testing domains by leveraging data from multiple training domains. However, traditional DG methods rely on the availability of multiple diverse training domains, limiting their applicability in data-constrained scenarios. Single Domain Generalization (SDG) addresses the more realistic and challenging setting by restricting the training data to a single domain distribution. The main challenges in SDG stem from the limited diversity of training data and the inaccessibility of unseen testing data distributions. To tackle these challenges, we propose a single domain generalization method that leverages an adversarial memory bank to augment training features. Our memory-based feature augmentation network maps both training and testing features into an invariant subspace spanned by diverse memory features, implicitly aligning the training and testing domains in the projected space. To maintain a diverse and representative feature memory bank, we introduce an adversarial feature generation method that creates features extending beyond the training domain distribution. Experimental results demonstrate that our approach achieves state-of-the-art performance on standard single domain generalization benchmarks.
Single Domain Generalization with Model-aware Parametric Batch-wise Mixup
Feb 22, 2025Single Domain Generalization (SDG) remains a formidable challenge in the field of machine learning, particularly when models are deployed in environments that differ significantly from their training domains. In this paper, we propose a novel data augmentation approach, named as Model-aware Parametric Batch-wise Mixup (MPBM), to tackle the challenge of SDG. MPBM deploys adversarial queries generated with stochastic gradient Langevin dynamics, and produces model-aware augmenting instances with a parametric batch-wise mixup generator network that is carefully designed through an innovative attention mechanism. By exploiting inter-feature correlations, the parameterized mixup generator introduces additional versatility in combining features across a batch of instances, thereby enhancing the capacity to generate highly adaptive and informative synthetic instances for specific queries. The synthetic data produced by this adaptable generator network, guided by informative queries, is expected to significantly enrich the representation space covered by the original training dataset and subsequently enhance the prediction model's generalizability across diverse and previously unseen domains. To prevent excessive deviation from the training data, we further incorporate a real-data alignment-based adversarial loss into the learning process of MPBM, regularizing any tendencies toward undesirable expansions. We conduct extensive experiments on several benchmark datasets. The empirical results demonstrate that by augmenting the training set with informative synthesis data, our proposed MPBM method achieves the state-of-the-art performance for single domain generalization.
Unbiased GNN Learning via Fairness-Aware Subgraph Diffusion
Dec 31, 2024



Graph Neural Networks (GNNs) have demonstrated remarkable efficacy in tackling a wide array of graph-related tasks across diverse domains. However, a significant challenge lies in their propensity to generate biased predictions, particularly with respect to sensitive node attributes such as age and gender. These biases, inherent in many machine learning models, are amplified in GNNs due to the message-passing mechanism, which allows nodes to influence each other, rendering the task of making fair predictions notably challenging. This issue is particularly pertinent in critical domains where model fairness holds paramount importance. In this paper, we propose a novel generative Fairness-Aware Subgraph Diffusion (FASD) method for unbiased GNN learning. The method initiates by strategically sampling small subgraphs from the original large input graph, and then proceeds to conduct subgraph debiasing via generative fairness-aware graph diffusion processes based on stochastic differential equations (SDEs). To effectively diffuse unfairness in the input data, we introduce additional adversary bias perturbations to the subgraphs during the forward diffusion process, and train score-based models to predict these applied perturbations, enabling them to learn the underlying dynamics of the biases present in the data. Subsequently, the trained score-based models are utilized to further debias the original subgraph samples through the reverse diffusion process. Finally, FASD induces fair node predictions on the input graph by performing standard GNN learning on the debiased subgraphs. Experimental results demonstrate the superior performance of the proposed method over state-of-the-art Fair GNN baselines across multiple benchmark datasets.
Overcoming Class Imbalance: Unified GNN Learning with Structural and Semantic Connectivity Representations
Dec 30, 2024



Class imbalance is pervasive in real-world graph datasets, where the majority of annotated nodes belong to a small set of classes (majority classes), leaving many other classes (minority classes) with only a handful of labeled nodes. Graph Neural Networks (GNNs) suffer from significant performance degradation in the presence of class imbalance, exhibiting bias towards majority classes and struggling to generalize effectively on minority classes. This limitation stems, in part, from the message passing process, leading GNNs to overfit to the limited neighborhood of annotated nodes from minority classes and impeding the propagation of discriminative information throughout the entire graph. In this paper, we introduce a novel Unified Graph Neural Network Learning (Uni-GNN) framework to tackle class-imbalanced node classification. The proposed framework seamlessly integrates both structural and semantic connectivity representations through semantic and structural node encoders. By combining these connectivity types, Uni-GNN extends the propagation of node embeddings beyond immediate neighbors, encompassing non-adjacent structural nodes and semantically similar nodes, enabling efficient diffusion of discriminative information throughout the graph. Moreover, to harness the potential of unlabeled nodes within the graph, we employ a balanced pseudo-label generation mechanism that augments the pool of available labeled nodes from minority classes in the training set. Experimental results underscore the superior performance of our proposed Uni-GNN framework compared to state-of-the-art class-imbalanced graph learning baselines across multiple benchmark datasets.
Skill-Enhanced Reinforcement Learning Acceleration from Demonstrations
Dec 09, 2024
Learning from Demonstration (LfD) aims to facilitate rapid Reinforcement Learning (RL) by leveraging expert demonstrations to pre-train the RL agent. However, the limited availability of expert demonstration data often hinders its ability to effectively aid downstream RL learning. To address this problem, we propose a novel two-stage method dubbed as Skill-enhanced Reinforcement Learning Acceleration (SeRLA). SeRLA introduces a skill-level adversarial Positive-Unlabeled (PU) learning model to extract useful skill prior knowledge by enabling learning from both limited expert data and general low-cost demonstration data in the offline prior learning stage. Subsequently, it deploys a skill-based soft actor-critic algorithm to leverage this acquired prior knowledge in the downstream online RL stage for efficient training of a skill policy network. Moreover, we develop a simple skill-level data enhancement technique to further alleviate data sparsity and improve both skill prior learning and downstream skill policy training. Our experimental results on multiple standard RL environments show the proposed SeRLA method achieves state-of-the-art performance on accelerating reinforcement learning on downstream tasks, especially in the early learning phase.
LayerKV: Optimizing Large Language Model Serving with Layer-wise KV Cache Management
Oct 01, 2024The expanding context windows in large language models (LLMs) have greatly enhanced their capabilities in various applications, but they also introduce significant challenges in maintaining low latency, particularly in Time to First Token (TTFT). This paper identifies that the sharp rise in TTFT as context length increases is predominantly driven by queuing delays, which are caused by the growing demands for GPU Key-Value (KV) cache allocation clashing with the limited availability of KV cache blocks. To address this issue, we propose LayerKV, a simple yet effective plug-in method that effectively reduces TTFT without requiring additional hardware or compromising output performance, while seamlessly integrating with existing parallelism strategies and scheduling techniques. Specifically, LayerKV introduces layer-wise KV block allocation, management, and offloading for fine-grained control over system memory, coupled with an SLO-aware scheduler to optimize overall Service Level Objectives (SLOs). Comprehensive evaluations on representative models, ranging from 7B to 70B parameters, across various GPU configurations, demonstrate that LayerKV improves TTFT latency up to 11x and reduces SLO violation rates by 28.7\%, significantly enhancing the user experience