 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Level Optimization for Single Domain Generalization
Apr 07, 2026Generalizing from a single labeled source domain to unseen target domains, without access to any target data during training, remains a fundamental challenge in robust machine learning. We address this underexplored setting, known as Single Domain Generalization (SDG), by proposing BiSDG, a bi-level optimization framework that explicitly decouples task learning from domain modeling. BiSDG simulates distribution shifts through surrogate domains constructed via label-preserving transformations of the source data. To capture domain-specific context, we propose a domain prompt encoder that generates lightweight modulation signals to produce augmenting features via feature-wise linear modulation. The learning process is formulated as a bi-level optimization problem: the inner objective optimizes task performance under fixed prompts, while the outer objective maximizes generalization across the surrogate domains by updating the domain prompt encoder. We further develop a practical gradient approximation scheme that enables efficient bi-level training without second-order derivatives. Extensive experiments on various SGD benchmarks demonstrate that BiSDG consistently outperforms prior methods, setting new state-of-the-art performance in the SDG setting.
Single Domain Generalization with Adversarial Memory
Mar 08, 2025



Domain Generalization (DG) aims to train models that can generalize to unseen testing domains by leveraging data from multiple training domains. However, traditional DG methods rely on the availability of multiple diverse training domains, limiting their applicability in data-constrained scenarios. Single Domain Generalization (SDG) addresses the more realistic and challenging setting by restricting the training data to a single domain distribution. The main challenges in SDG stem from the limited diversity of training data and the inaccessibility of unseen testing data distributions. To tackle these challenges, we propose a single domain generalization method that leverages an adversarial memory bank to augment training features. Our memory-based feature augmentation network maps both training and testing features into an invariant subspace spanned by diverse memory features, implicitly aligning the training and testing domains in the projected space. To maintain a diverse and representative feature memory bank, we introduce an adversarial feature generation method that creates features extending beyond the training domain distribution. Experimental results demonstrate that our approach achieves state-of-the-art performance on standard single domain generalization benchmarks.
Single Domain Generalization with Model-aware Parametric Batch-wise Mixup
Feb 22, 2025Single Domain Generalization (SDG) remains a formidable challenge in the field of machine learning, particularly when models are deployed in environments that differ significantly from their training domains. In this paper, we propose a novel data augmentation approach, named as Model-aware Parametric Batch-wise Mixup (MPBM), to tackle the challenge of SDG. MPBM deploys adversarial queries generated with stochastic gradient Langevin dynamics, and produces model-aware augmenting instances with a parametric batch-wise mixup generator network that is carefully designed through an innovative attention mechanism. By exploiting inter-feature correlations, the parameterized mixup generator introduces additional versatility in combining features across a batch of instances, thereby enhancing the capacity to generate highly adaptive and informative synthetic instances for specific queries. The synthetic data produced by this adaptable generator network, guided by informative queries, is expected to significantly enrich the representation space covered by the original training dataset and subsequently enhance the prediction model's generalizability across diverse and previously unseen domains. To prevent excessive deviation from the training data, we further incorporate a real-data alignment-based adversarial loss into the learning process of MPBM, regularizing any tendencies toward undesirable expansions. We conduct extensive experiments on several benchmark datasets. The empirical results demonstrate that by augmenting the training set with informative synthesis data, our proposed MPBM method achieves the state-of-the-art performance for single domain generalization.
Reinforcement Learning-Guided Semi-Supervised Learning
May 02, 2024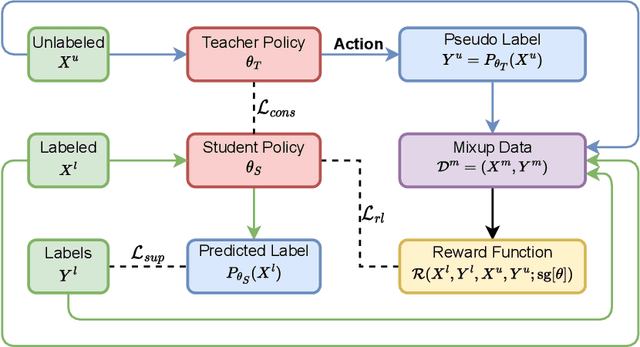
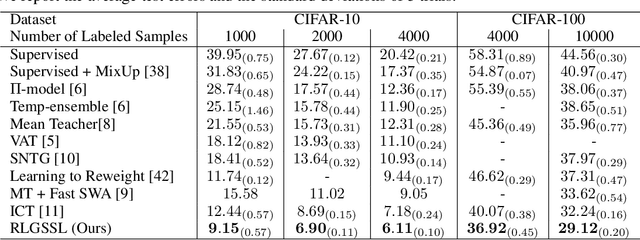

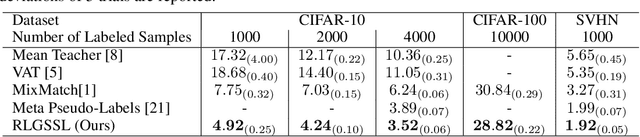
In recent years, semi-supervised learning (SSL) has gained significant attention due to its ability to leverage both labeled and unlabeled data to improve model performance, especially when labeled data is scarce. However, most current SSL methods rely on heuristics or predefined rules for generating pseudo-labels and leveraging unlabeled data. They are limited to exploiting loss functions and regularization methods within the standard norm. In this paper, we propose a novel Reinforcement Learning (RL) Guided SSL method, RLGSSL, that formulates SSL as a one-armed bandit problem and deploys an innovative RL loss based on weighted reward to adaptively guide the learning process of the prediction model. RLGSSL incorporates a carefully designed reward function that balances the use of labeled and unlabeled data to enhance generalization performance. A semi-supervised teacher-student framework is further deployed to increase the learning stability. We demonstrate the effectiveness of RLGSSL through extensive experiments on several benchmark datasets and show that our approach achieves consistent superior performance compared to state-of-the-art SSL methods.
Prompt-Driven Feature Diffusion for Open-World Semi-Supervised Learning
Apr 17, 2024In this paper, we present a novel approach termed Prompt-Driven Feature Diffusion (PDFD) within a semi-supervised learning framework for Open World Semi-Supervised Learning (OW-SSL). At its core, PDFD deploys an efficient feature-level diffusion model with the guidance of class-specific prompts to support discriminative feature representation learning and feature generation, tackling the challenge of the non-availability of labeled data for unseen classes in OW-SSL. In particular, PDFD utilizes class prototypes as prompts in the diffusion model, leveraging their class-discriminative and semantic generalization ability to condition and guide the diffusion process across all the seen and unseen classes. Furthermore, PDFD incorporates a class-conditional adversarial loss for diffusion model training, ensuring that the features generated via the diffusion process can be discriminatively aligned with the class-conditional features of the real data. Additionally, the class prototypes of the unseen classes are computed using only unlabeled instances with confident predictions within a semi-supervised learning framework. We conduct extensive experiments to evaluate the proposed PDFD. The empirical results show PDFD exhibits remarkable performance enhancements over many state-of-the-art existing methods.
Adaptive Weighted Co-Learning for Cross-Domain Few-Shot Learning
Dec 06, 2023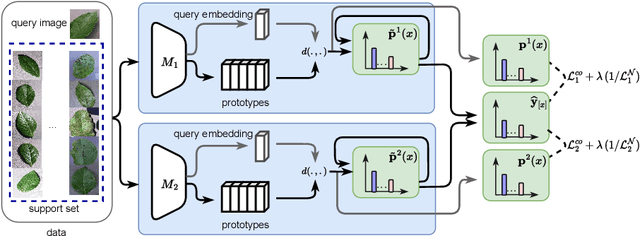
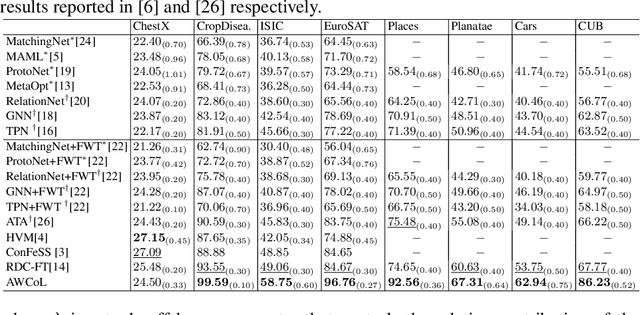
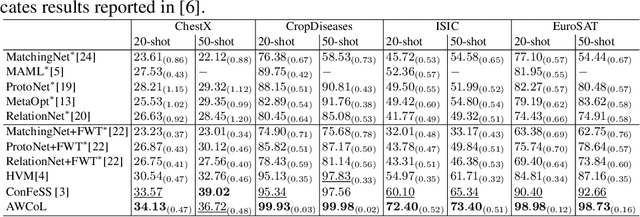

Due to the availability of only a few labeled instances for the novel target prediction task and the significant domain shift between the well annotated source domain and the target domain, cross-domain few-shot learning (CDFSL) induces a very challenging adaptation problem. In this paper, we propose a simple Adaptive Weighted Co-Learning (AWCoL) method to address the CDFSL challenge by adapting two independently trained source prototypical classification models to the target task in a weighted co-learning manner. The proposed method deploys a weighted moving average prediction strategy to generate probabilistic predictions from each model, and then conducts adaptive co-learning by jointly fine-tuning the two models in an alternating manner based on the pseudo-labels and instance weights produced from the predictions. Moreover, a negative pseudo-labeling regularizer is further deployed to improve the fine-tuning process by penalizing false predictions. Comprehensive experiments are conducted on multiple benchmark datasets and the empirical results demonstrate that the proposed method produces state-of-the-art CDFSL performance.
Adaptive Parametric Prototype Learning for Cross-Domain Few-Shot Classification
Sep 04, 2023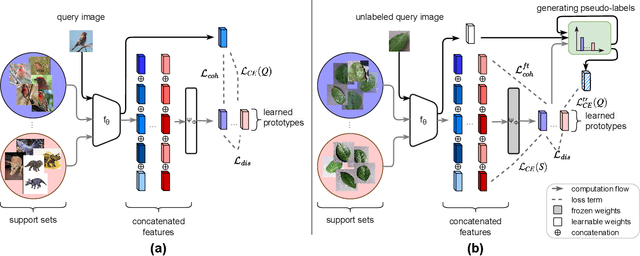
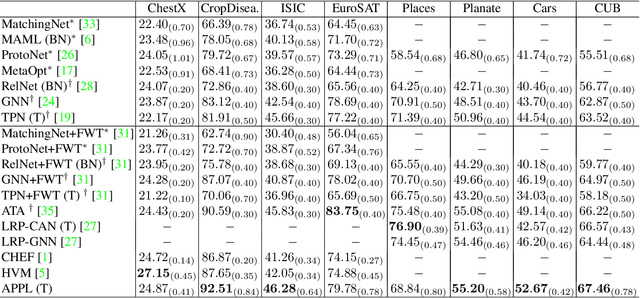
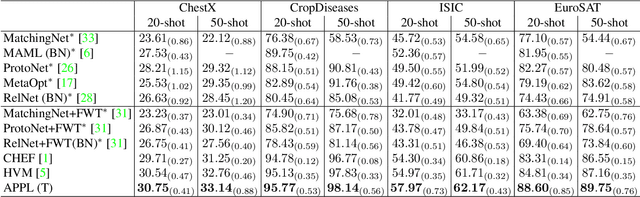
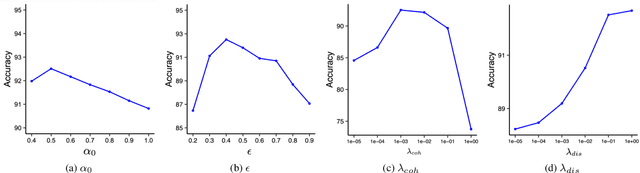
Cross-domain few-shot classification induces a much more challenging problem than its in-domain counterpart due to the existence of domain shifts between the training and test tasks. In this paper, we develop a novel Adaptive Parametric Prototype Learning (APPL) method under the meta-learning convention for cross-domain few-shot classification. Different from existing prototypical few-shot methods that use the averages of support instances to calculate the class prototypes, we propose to learn class prototypes from the concatenated features of the support set in a parametric fashion and meta-learn the model by enforcing prototype-based regularization on the query set. In addition, we fine-tune the model in the target domain in a transductive manner using a weighted-moving-average self-training approach on the query instances. We conduct experiments on multiple cross-domain few-shot benchmark datasets. The empirical results demonstrate that APPL yields superior performance than many state-of-the-art cross-domain few-shot learning methods.