 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Level Optimization for Single Domain Generalization
Apr 07, 2026Generalizing from a single labeled source domain to unseen target domains, without access to any target data during training, remains a fundamental challenge in robust machine learning. We address this underexplored setting, known as Single Domain Generalization (SDG), by proposing BiSDG, a bi-level optimization framework that explicitly decouples task learning from domain modeling. BiSDG simulates distribution shifts through surrogate domains constructed via label-preserving transformations of the source data. To capture domain-specific context, we propose a domain prompt encoder that generates lightweight modulation signals to produce augmenting features via feature-wise linear modulation. The learning process is formulated as a bi-level optimization problem: the inner objective optimizes task performance under fixed prompts, while the outer objective maximizes generalization across the surrogate domains by updating the domain prompt encoder. We further develop a practical gradient approximation scheme that enables efficient bi-level training without second-order derivatives. Extensive experiments on various SGD benchmarks demonstrate that BiSDG consistently outperforms prior methods, setting new state-of-the-art performance in the SDG setting.
Bridging Dynamics Gaps via Diffusion Schrödinger Bridge for Cross-Domain Reinforcement Learning
Feb 27, 2026Cross-domain reinforcement learning (RL) aims to learn transferable policies under dynamics shifts between source and target domains. A key challenge lies in the lack of target-domain environment interaction and reward supervision, which prevents direct policy learning. To address this challenge, we propose Bridging Dynamics Gaps for Cross-Domain Reinforcement Learning (BDGxRL), a novel framework that leverages Diffusion Schrödinger Bridge (DSB) to align source transitions with target-domain dynamics encoded in offline demonstrations. Moreover, we introduce a reward modulation mechanism that estimates rewards based on state transitions, applying to DSB-aligned samples to ensure consistency between rewards and target-domain dynamics. BDGxRL performs target-oriented policy learning entirely within the source domain, without access to the target environment or its rewards. Experiments on MuJoCo cross-domain benchmarks demonstrate that BDGxRL outperforms state-of-the-art baselines and shows strong adaptability under transition dynamics shifts.
Diffusion Modulation via Environment Mechanism Modeling for Planning
Feb 23, 2026Diffusion models have shown promising capabilities in trajectory generation for planning in offline reinforcement learning (RL). However, conventional diffusion-based planning methods often fail to account for the fact that generating trajectories in RL requires unique consistency between transitions to ensure coherence in real environments. This oversight can result in considerable discrepancies between the generated trajectories and the underlying mechanisms of a real environment. To address this problem, we propose a novel diffusion-based planning method, termed as Diffusion Modulation via Environment Mechanism Modeling (DMEMM). DMEMM modulates diffusion model training by incorporating key RL environment mechanisms, particularly transition dynamics and reward functions. Experimental results demonstrate that DMEMM achieves state-of-the-art performance for planning with offline reinforcement learning.
Skill-based Safe Reinforcement Learning with Risk Planning
May 02, 2025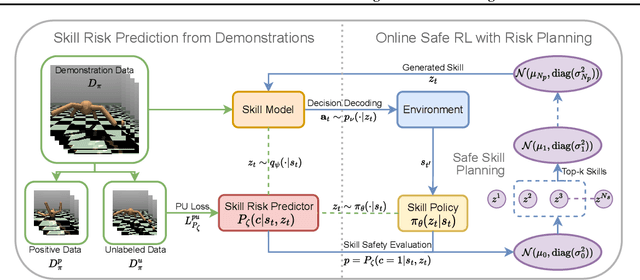
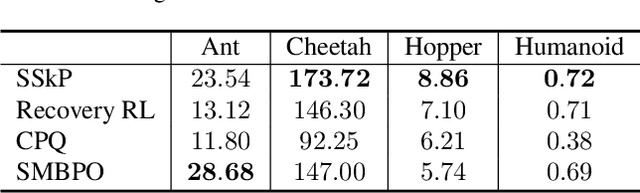


Safe Reinforcement Learning (Safe RL) aims to ensure safety when an RL agent conducts learning by interacting with real-world environments where improper actions can induce high costs or lead to severe consequences. In this paper, we propose a novel Safe Skill Planning (SSkP) approach to enhance effective safe RL by exploiting auxiliary offline demonstration data. SSkP involves a two-stage process. First, we employ PU learning to learn a skill risk predictor from the offline demonstration data. Then, based on the learned skill risk predictor, we develop a novel risk planning process to enhance online safe RL and learn a risk-averse safe policy efficiently through interactions with the online RL environment, while simultaneously adapting the skill risk predictor to the environment. We conduct experiments in several benchmark robotic simulation environments. The experimental results demonstrate that the proposed approach consistently outperforms previous state-of-the-art safe RL methods.
Zero-Shot Action Generalization with Limited Observations
Mar 11, 2025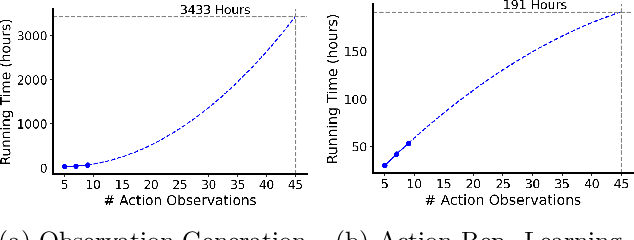
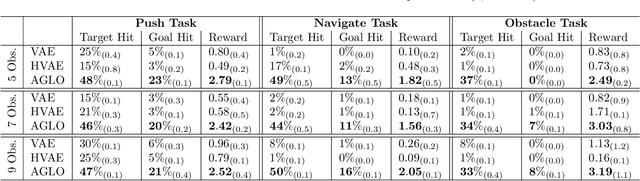
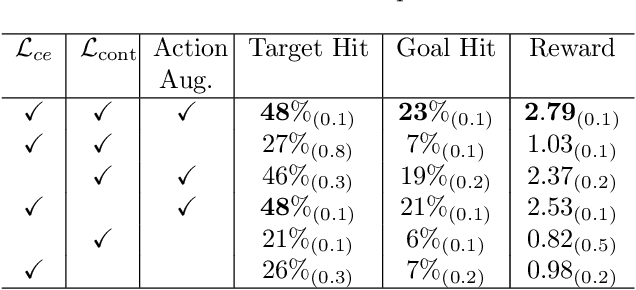
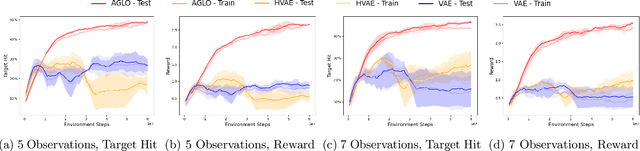
Reinforcement Learning (RL) has demonstrated remarkable success in solving sequential decision-making problems. However, in real-world scenarios, RL agents often struggle to generalize when faced with unseen actions that were not encountered during training. Some previous works on zero-shot action generalization rely on large datasets of action observations to capture the behaviors of new actions, making them impractical for real-world applications. In this paper, we introduce a novel zero-shot framework, Action Generalization from Limited Observations (AGLO). Our framework has two main components: an action representation learning module and a policy learning module. The action representation learning module extracts discriminative embeddings of actions from limited observations, while the policy learning module leverages the learned action representations, along with augmented synthetic action representations, to learn a policy capable of handling tasks with unseen actions. The experimental results demonstrate that our framework significantly outperforms state-of-the-art methods for zero-shot action generalization across multiple benchmark tasks, showcasing its effectiveness in generalizing to new actions with minimal action observations.
Skill-Enhanced Reinforcement Learning Acceleration from Demonstrations
Dec 09, 2024
Learning from Demonstration (LfD) aims to facilitate rapid Reinforcement Learning (RL) by leveraging expert demonstrations to pre-train the RL agent. However, the limited availability of expert demonstration data often hinders its ability to effectively aid downstream RL learning. To address this problem, we propose a novel two-stage method dubbed as Skill-enhanced Reinforcement Learning Acceleration (SeRLA). SeRLA introduces a skill-level adversarial Positive-Unlabeled (PU) learning model to extract useful skill prior knowledge by enabling learning from both limited expert data and general low-cost demonstration data in the offline prior learning stage. Subsequently, it deploys a skill-based soft actor-critic algorithm to leverage this acquired prior knowledge in the downstream online RL stage for efficient training of a skill policy network. Moreover, we develop a simple skill-level data enhancement technique to further alleviate data sparsity and improve both skill prior learning and downstream skill policy training. Our experimental results on multiple standard RL environments show the proposed SeRLA method achieves state-of-the-art performance on accelerating reinforcement learning on downstream tasks, especially in the early learning phase.
Reinforcement Learning-Guided Semi-Supervised Learning
May 02, 2024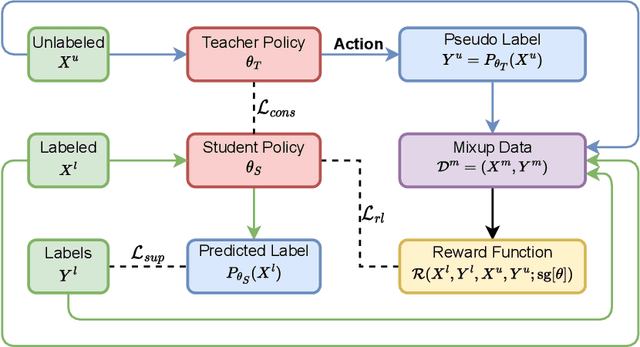
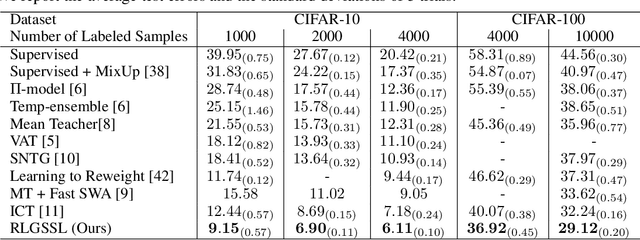

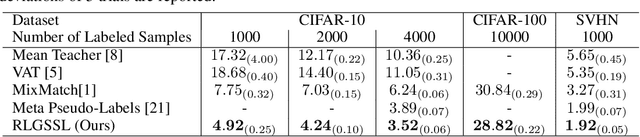
In recent years, semi-supervised learning (SSL) has gained significant attention due to its ability to leverage both labeled and unlabeled data to improve model performance, especially when labeled data is scarce. However, most current SSL methods rely on heuristics or predefined rules for generating pseudo-labels and leveraging unlabeled data. They are limited to exploiting loss functions and regularization methods within the standard norm. In this paper, we propose a novel Reinforcement Learning (RL) Guided SSL method, RLGSSL, that formulates SSL as a one-armed bandit problem and deploys an innovative RL loss based on weighted reward to adaptively guide the learning process of the prediction model. RLGSSL incorporates a carefully designed reward function that balances the use of labeled and unlabeled data to enhance generalization performance. A semi-supervised teacher-student framework is further deployed to increase the learning stability. We demonstrate the effectiveness of RLGSSL through extensive experiments on several benchmark datasets and show that our approach achieves consistent superior performance compared to state-of-the-art SSL methods.
Prompt-Driven Feature Diffusion for Open-World Semi-Supervised Learning
Apr 17, 2024In this paper, we present a novel approach termed Prompt-Driven Feature Diffusion (PDFD) within a semi-supervised learning framework for Open World Semi-Supervised Learning (OW-SSL). At its core, PDFD deploys an efficient feature-level diffusion model with the guidance of class-specific prompts to support discriminative feature representation learning and feature generation, tackling the challenge of the non-availability of labeled data for unseen classes in OW-SSL. In particular, PDFD utilizes class prototypes as prompts in the diffusion model, leveraging their class-discriminative and semantic generalization ability to condition and guide the diffusion process across all the seen and unseen classes. Furthermore, PDFD incorporates a class-conditional adversarial loss for diffusion model training, ensuring that the features generated via the diffusion process can be discriminatively aligned with the class-conditional features of the real data. Additionally, the class prototypes of the unseen classes are computed using only unlabeled instances with confident predictions within a semi-supervised learning framework. We conduct extensive experiments to evaluate the proposed PDFD. The empirical results show PDFD exhibits remarkable performance enhancements over many state-of-the-art existing methods.
Safe Reinforcement Learning with Contrastive Risk Prediction
Sep 10, 2022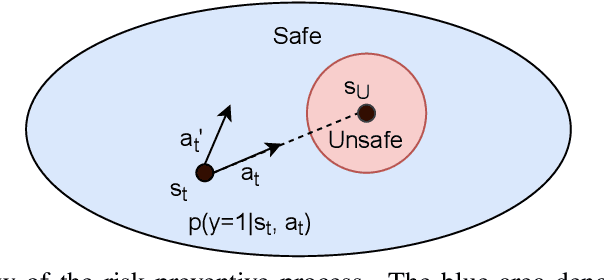
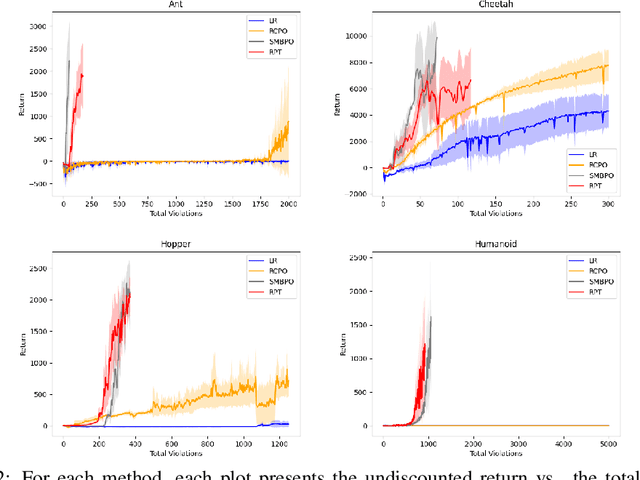
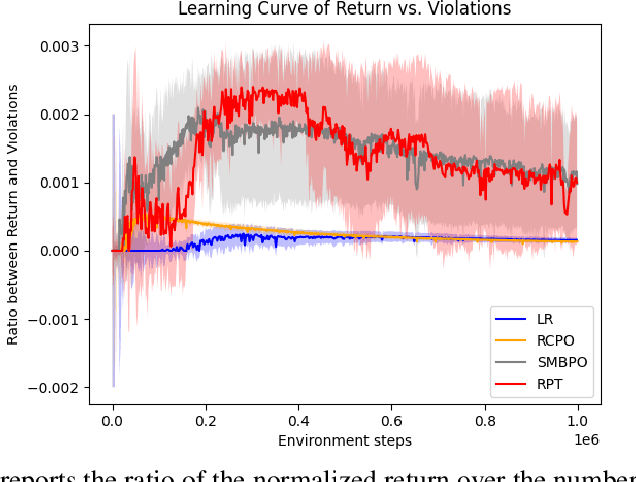
As safety violations can lead to severe consequences in real-world robotic applications, the increasing deployment of Reinforcement Learning (RL) in robotic domains has propelled the study of safe exploration for reinforcement learning (safe RL). In this work, we propose a risk preventive training method for safe RL, which learns a statistical contrastive classifier to predict the probability of a state-action pair leading to unsafe states. Based on the predicted risk probabilities, we can collect risk preventive trajectories and reshape the reward function with risk penalties to induce safe RL policies. We conduct experiments in robotic simulation environments. The results show the proposed approach has comparable performance with the state-of-the-art model-based methods and outperforms conventional model-free safe RL approaches.
Generalization of Reinforcement Learning with Policy-Aware Adversarial Data Augmentation
Jun 29, 2021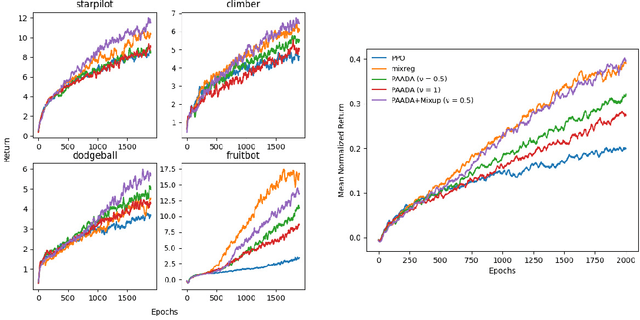
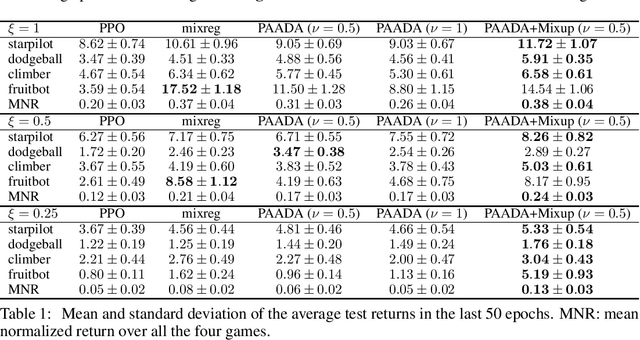
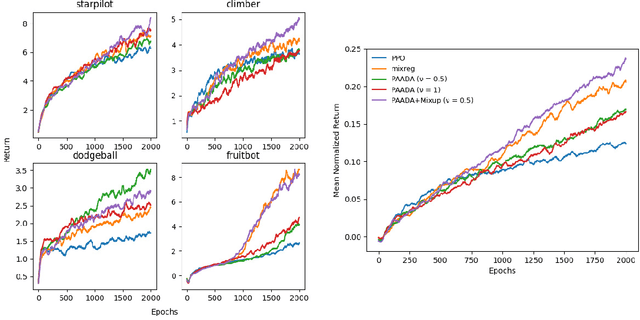

The generalization gap in reinforcement learning (RL) has been a significant obstacle that prevents the RL agent from learning general skills and adapting to varying environments. Increasing the generalization capacity of the RL systems can significantly improve their performance on real-world working environments. In this work, we propose a novel policy-aware adversarial data augmentation method to augment the standard policy learning method with automatically generated trajectory data. Different from the commonly used observation transformation based data augmentations, our proposed method adversarially generates new trajectory data based on the policy gradient objective and aims to more effectively increase the RL agent's generalization ability with the policy-aware data augmentation. Moreover, we further deploy a mixup step to integrate the original and generated data to enhance the generalization capacity while mitigating the over-deviation of the adversarial data. We conduct experiments on a number of RL tasks to investigate the generalization performance of the proposed method by comparing it with the standard baselines and the state-of-the-art mixreg approach. The results show our method can generalize well with limited training diversity, and achieve the state-of-the-art generalization test performance.