 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Action Generalization with Limited Observations
Mar 11, 2025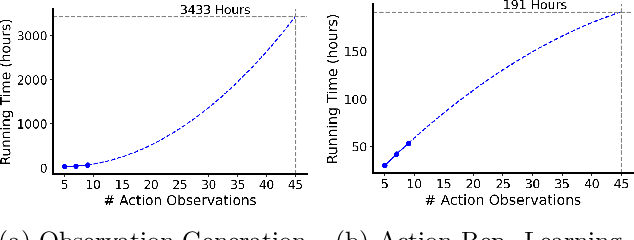
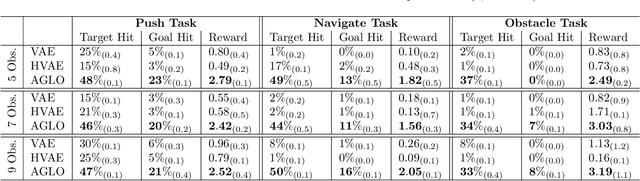
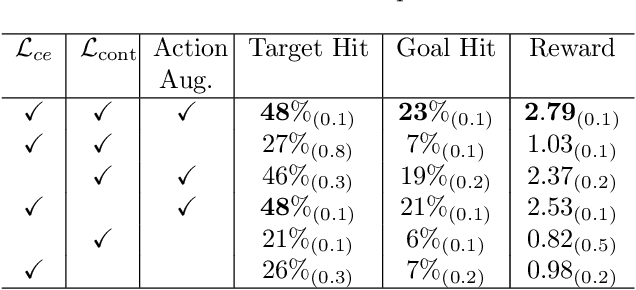
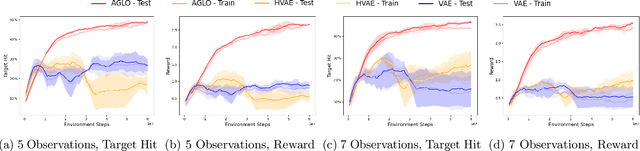
Reinforcement Learning (RL) has demonstrated remarkable success in solving sequential decision-making problems. However, in real-world scenarios, RL agents often struggle to generalize when faced with unseen actions that were not encountered during training. Some previous works on zero-shot action generalization rely on large datasets of action observations to capture the behaviors of new actions, making them impractical for real-world applications. In this paper, we introduce a novel zero-shot framework, Action Generalization from Limited Observations (AGLO). Our framework has two main components: an action representation learning module and a policy learning module. The action representation learning module extracts discriminative embeddings of actions from limited observations, while the policy learning module leverages the learned action representations, along with augmented synthetic action representations, to learn a policy capable of handling tasks with unseen actions. The experimental results demonstrate that our framework significantly outperforms state-of-the-art methods for zero-shot action generalization across multiple benchmark tasks, showcasing its effectiveness in generalizing to new actions with minimal action observations.
Unbiased GNN Learning via Fairness-Aware Subgraph Diffusion
Dec 31, 2024



Graph Neural Networks (GNNs) have demonstrated remarkable efficacy in tackling a wide array of graph-related tasks across diverse domains. However, a significant challenge lies in their propensity to generate biased predictions, particularly with respect to sensitive node attributes such as age and gender. These biases, inherent in many machine learning models, are amplified in GNNs due to the message-passing mechanism, which allows nodes to influence each other, rendering the task of making fair predictions notably challenging. This issue is particularly pertinent in critical domains where model fairness holds paramount importance. In this paper, we propose a novel generative Fairness-Aware Subgraph Diffusion (FASD) method for unbiased GNN learning. The method initiates by strategically sampling small subgraphs from the original large input graph, and then proceeds to conduct subgraph debiasing via generative fairness-aware graph diffusion processes based on stochastic differential equations (SDEs). To effectively diffuse unfairness in the input data, we introduce additional adversary bias perturbations to the subgraphs during the forward diffusion process, and train score-based models to predict these applied perturbations, enabling them to learn the underlying dynamics of the biases present in the data. Subsequently, the trained score-based models are utilized to further debias the original subgraph samples through the reverse diffusion process. Finally, FASD induces fair node predictions on the input graph by performing standard GNN learning on the debiased subgraphs. Experimental results demonstrate the superior performance of the proposed method over state-of-the-art Fair GNN baselines across multiple benchmark datasets.
Overcoming Class Imbalance: Unified GNN Learning with Structural and Semantic Connectivity Representations
Dec 30, 2024



Class imbalance is pervasive in real-world graph datasets, where the majority of annotated nodes belong to a small set of classes (majority classes), leaving many other classes (minority classes) with only a handful of labeled nodes. Graph Neural Networks (GNNs) suffer from significant performance degradation in the presence of class imbalance, exhibiting bias towards majority classes and struggling to generalize effectively on minority classes. This limitation stems, in part, from the message passing process, leading GNNs to overfit to the limited neighborhood of annotated nodes from minority classes and impeding the propagation of discriminative information throughout the entire graph. In this paper, we introduce a novel Unified Graph Neural Network Learning (Uni-GNN) framework to tackle class-imbalanced node classification. The proposed framework seamlessly integrates both structural and semantic connectivity representations through semantic and structural node encoders. By combining these connectivity types, Uni-GNN extends the propagation of node embeddings beyond immediate neighbors, encompassing non-adjacent structural nodes and semantically similar nodes, enabling efficient diffusion of discriminative information throughout the graph. Moreover, to harness the potential of unlabeled nodes within the graph, we employ a balanced pseudo-label generation mechanism that augments the pool of available labeled nodes from minority classes in the training set. Experimental results underscore the superior performance of our proposed Uni-GNN framework compared to state-of-the-art class-imbalanced graph learning baselines across multiple benchmark datasets.
Adaptive Weighted Co-Learning for Cross-Domain Few-Shot Learning
Dec 06, 2023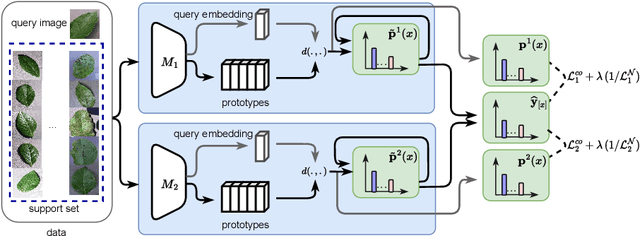
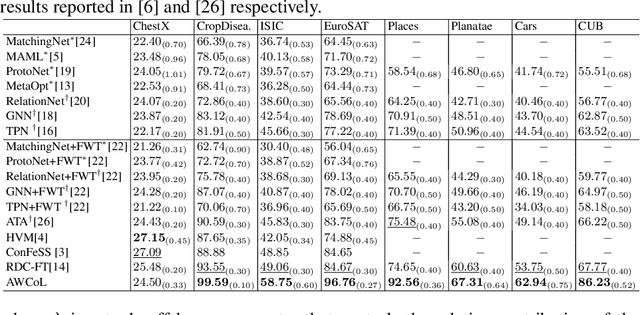
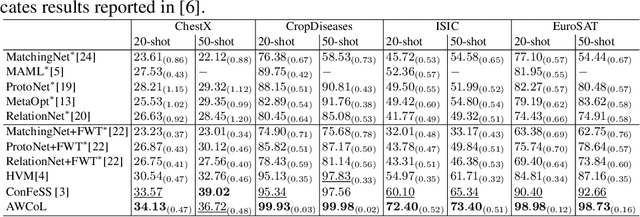

Due to the availability of only a few labeled instances for the novel target prediction task and the significant domain shift between the well annotated source domain and the target domain, cross-domain few-shot learning (CDFSL) induces a very challenging adaptation problem. In this paper, we propose a simple Adaptive Weighted Co-Learning (AWCoL) method to address the CDFSL challenge by adapting two independently trained source prototypical classification models to the target task in a weighted co-learning manner. The proposed method deploys a weighted moving average prediction strategy to generate probabilistic predictions from each model, and then conducts adaptive co-learning by jointly fine-tuning the two models in an alternating manner based on the pseudo-labels and instance weights produced from the predictions. Moreover, a negative pseudo-labeling regularizer is further deployed to improve the fine-tuning process by penalizing false predictions. Comprehensive experiments are conducted on multiple benchmark datasets and the empirical results demonstrate that the proposed method produces state-of-the-art CDFSL performance.
GDM: Dual Mixup for Graph Classification with Limited Supervision
Sep 18, 2023Graph Neural Networks (GNNs) require a large number of labeled graph samples to obtain good performance on the graph classification task. The performance of GNNs degrades significantly as the number of labeled graph samples decreases. To reduce the annotation cost, it is therefore important to develop graph augmentation methods that can generate new graph instances to increase the size and diversity of the limited set of available labeled graph samples. In this work, we propose a novel mixup-based graph augmentation method, Graph Dual Mixup (GDM), that leverages both functional and structural information of the graph instances to generate new labeled graph samples. GDM employs a graph structural auto-encoder to learn structural embeddings of the graph samples, and then applies mixup to the structural information of the graphs in the learned structural embedding space and generates new graph structures from the mixup structural embeddings. As for the functional information, GDM applies mixup directly to the input node features of the graph samples to generate functional node feature information for new mixup graph instances. Jointly, the generated input node features and graph structures yield new graph samples which can supplement the set of original labeled graphs. Furthermore, we propose two novel Balanced Graph Sampling methods to enhance the balanced difficulty and diversity for the generated graph samples. Experimental results on the benchmark datasets demonstrate that our proposed method substantially outperforms the state-of-the-art graph augmentation methods when the labeled graphs are scarce.
Efficient Low-Rank GNN Defense Against Structural Attacks
Sep 18, 2023Graph Neural Networks (GNNs) have been shown to possess strong representation abilities over graph data. However, GNNs are vulnerable to adversarial attacks, and even minor perturbations to the graph structure can significantly degrade their performance. Existing methods either are ineffective against sophisticated attacks or require the optimization of dense adjacency matrices, which is time-consuming and prone to local minima. To remedy this problem, we propose an Efficient Low-Rank Graph Neural Network (ELR-GNN) defense method, which aims to learn low-rank and sparse graph structures for defending against adversarial attacks, ensuring effective defense with greater efficiency. Specifically, ELR-GNN consists of two modules: a Coarse Low-Rank Estimation Module and a Fine-Grained Estimation Module. The first module adopts the truncated Singular Value Decomposition (SVD) to initialize the low-rank adjacency matrix estimation, which serves as a starting point for optimizing the low-rank matrix. In the second module, the initial estimate is refined by jointly learning a low-rank sparse graph structure with the GNN model. Sparsity is incorporated into the learned low-rank adjacency matrix by pruning weak connections, which can reduce redundant data while maintaining valuable information. As a result, instead of using the dense adjacency matrix directly, ELR-GNN can learn a low-rank and sparse estimate of it in a simple, efficient and easy to optimize manner. The experimental results demonstrate that ELR-GNN outperforms the state-of-the-art GNN defense methods in the literature, in addition to being very efficient and easy to train.
Adaptive Parametric Prototype Learning for Cross-Domain Few-Shot Classification
Sep 04, 2023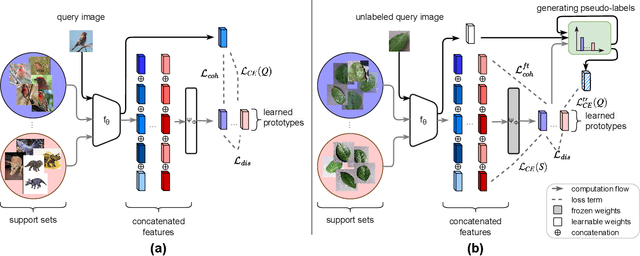
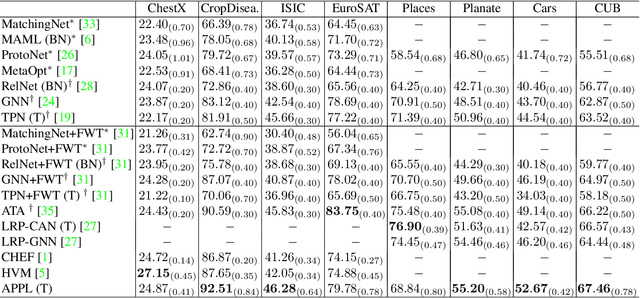
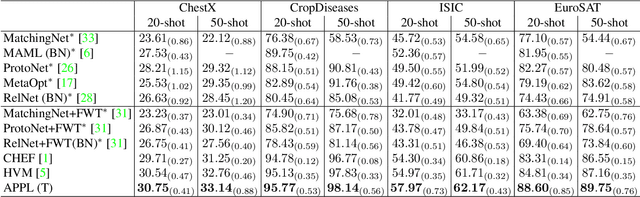
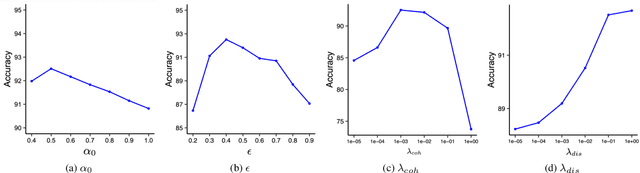
Cross-domain few-shot classification induces a much more challenging problem than its in-domain counterpart due to the existence of domain shifts between the training and test tasks. In this paper, we develop a novel Adaptive Parametric Prototype Learning (APPL) method under the meta-learning convention for cross-domain few-shot classification. Different from existing prototypical few-shot methods that use the averages of support instances to calculate the class prototypes, we propose to learn class prototypes from the concatenated features of the support set in a parametric fashion and meta-learn the model by enforcing prototype-based regularization on the query set. In addition, we fine-tune the model in the target domain in a transductive manner using a weighted-moving-average self-training approach on the query instances. We conduct experiments on multiple cross-domain few-shot benchmark datasets. The empirical results demonstrate that APPL yields superior performance than many state-of-the-art cross-domain few-shot learning methods.
Dual GNNs: Graph Neural Network Learning with Limited Supervision
Jun 29, 2021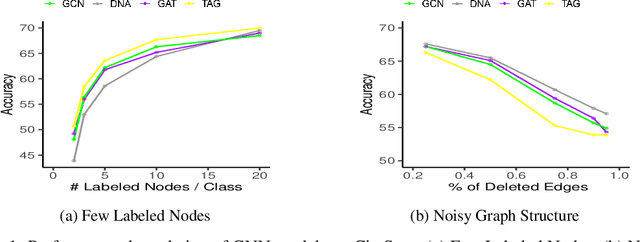
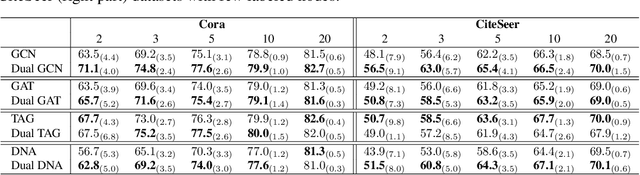
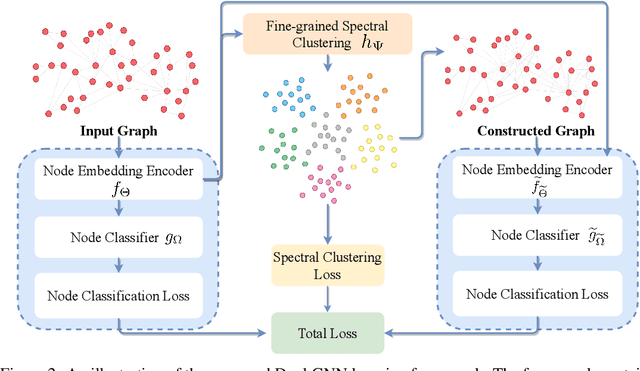
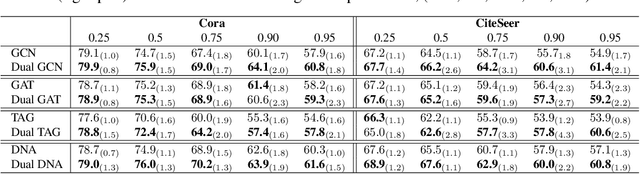
Graph Neural Networks (GNNs) require a relatively large number of labeled nodes and a reliable/uncorrupted graph connectivity structure in order to obtain good performance on the semi-supervised node classification task. The performance of GNNs can degrade significantly as the number of labeled nodes decreases or the graph connectivity structure is corrupted by adversarial attacks or due to noises in data measurement /collection. Therefore, it is important to develop GNN models that are able to achieve good performance when there is limited supervision knowledge -- a few labeled nodes and noisy graph structures. In this paper, we propose a novel Dual GNN learning framework to address this challenge task. The proposed framework has two GNN based node prediction modules. The primary module uses the input graph structure to induce regular node embeddings and predictions with a regular GNN baseline, while the auxiliary module constructs a new graph structure through fine-grained spectral clusterings and learns new node embeddings and predictions. By integrating the two modules in a dual GNN learning framework, we perform joint learning in an end-to-end fashion. This general framework can be applied on many GNN baseline models. The experimental results validate that the proposed dual GNN framework can greatly outperform the GNN baseline methods when the labeled nodes are scarce and the graph connectivity structure is noisy.
On the Brain Networks of Complex Problem Solving
Oct 10, 2018


Complex problem solving is a high level cognitive process which has been thoroughly studied over the last decade. The Tower of London (TOL) is a task that has been widely used to study problem-solving. In this study, we aim to explore the underlying cognitive network dynamics among anatomical regions of complex problem solving and its sub-phases, namely planning and execution. A new brain network construction model establishing dynamic functional brain networks using fMRI is proposed. The first step of the model is a preprocessing pipeline that manages to decrease the spatial redundancy while increasing the temporal resolution of the fMRI recordings. Then, dynamic brain networks are estimated using artificial neural networks. The network properties of the estimated brain networks are studied in order to identify regions of interest, such as hubs and subgroups of densely connected brain regions. The major similarities and dissimilarities of the network structure of planning and execution phases are highlighted. Our findings show the hubs and clusters of densely interconnected regions during both subtasks. It is observed that there are more hubs during the planning phase compared to the execution phase, and the clusters are more strongly connected during planning compared to execution.
Encoding Multi-Resolution Brain Networks Using Unsupervised Deep Learning
Aug 13, 2017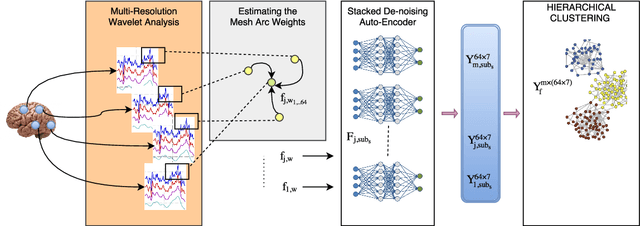


The main goal of this study is to extract a set of brain networks in multiple time-resolutions to analyze the connectivity patterns among the anatomic regions for a given cognitive task. We suggest a deep architecture which learns the natural groupings of the connectivity patterns of human brain in multiple time-resolutions. The suggested architecture is tested on task data set of Human Connectome Project (HCP) where we extract multi-resolution networks, each of which corresponds to a cognitive task. At the first level of this architecture, we decompose the fMRI signal into multiple sub-bands using wavelet decompositions. At the second level, for each sub-band, we estimate a brain network extracted from short time windows of the fMRI signal. At the third level, we feed the adjacency matrices of each mesh network at each time-resolution into an unsupervised deep learning algorithm, namely, a Stacked De- noising Auto-Encoder (SDAE). The outputs of the SDAE provide a compact connectivity representation for each time window at each sub-band of the fMRI signal. We concatenate the learned representations of all sub-bands at each window and cluster them by a hierarchical algorithm to find the natural groupings among the windows. We observe that each cluster represents a cognitive task with a performance of 93% Rand Index and 71% Adjusted Rand Index. We visualize the mean values and the precisions of the networks at each component of the cluster mixture. The mean brain networks at cluster centers show the variations among cognitive tasks and the precision of each cluster shows the within cluster variability of networks, across the subjects.