 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization of Reinforcement Learning with Policy-Aware Adversarial Data Augmentation
Paper and Code
Jun 29, 2021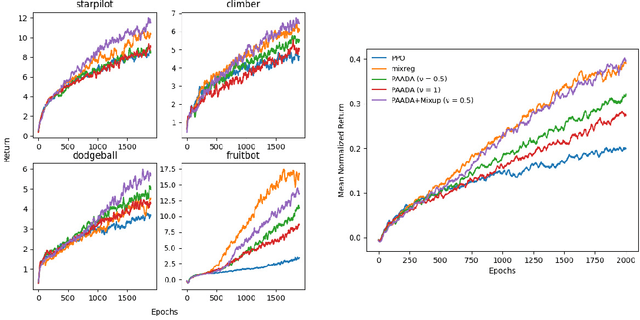
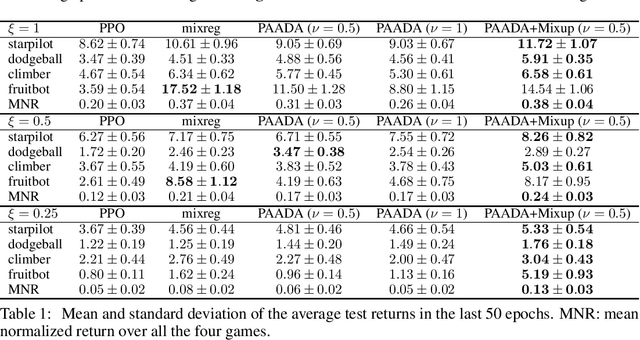
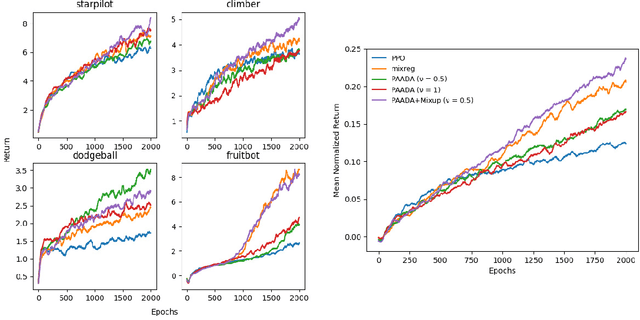

The generalization gap in reinforcement learning (RL) has been a significant obstacle that prevents the RL agent from learning general skills and adapting to varying environments. Increasing the generalization capacity of the RL systems can significantly improve their performance on real-world working environments. In this work, we propose a novel policy-aware adversarial data augmentation method to augment the standard policy learning method with automatically generated trajectory data. Different from the commonly used observation transformation based data augmentations, our proposed method adversarially generates new trajectory data based on the policy gradient objective and aims to more effectively increase the RL agent's generalization ability with the policy-aware data augmentation. Moreover, we further deploy a mixup step to integrate the original and generated data to enhance the generalization capacity while mitigating the over-deviation of the adversarial data. We conduct experiments on a number of RL tasks to investigate the generalization performance of the proposed method by comparing it with the standard baselines and the state-of-the-art mixreg approach. The results show our method can generalize well with limited training diversity, and achieve the state-of-the-art generalization test performance.