 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgevTensor: Flexible Virtual Tensor Management for Efficient LLM Serving
Jul 22, 2024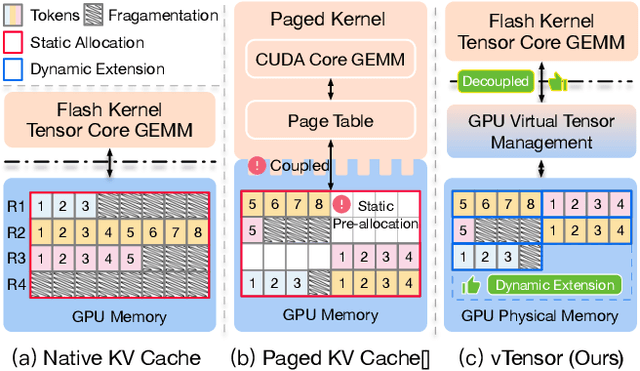

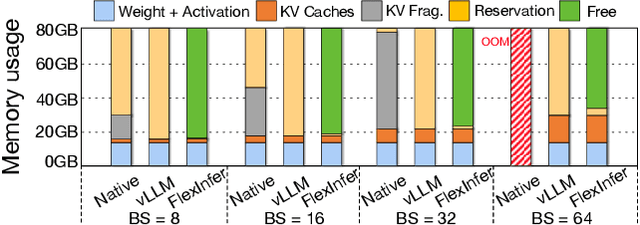
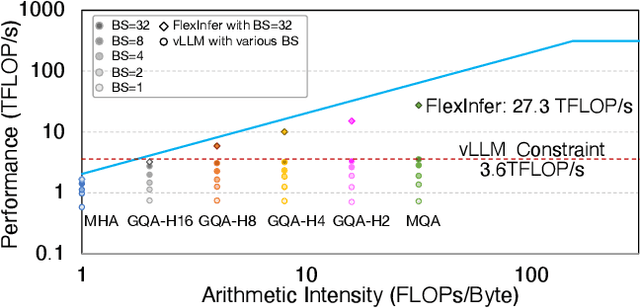
Large Language Models (LLMs) are widely used across various domains, processing millions of daily requests. This surge in demand poses significant challenges in optimizing throughput and latency while keeping costs manageable. The Key-Value (KV) cache, a standard method for retaining previous computations, makes LLM inference highly bounded by memory. While batching strategies can enhance performance, they frequently lead to significant memory fragmentation. Even though cutting-edge systems like vLLM mitigate KV cache fragmentation using paged Attention mechanisms, they still suffer from inefficient memory and computational operations due to the tightly coupled page management and computation kernels. This study introduces the vTensor, an innovative tensor structure for LLM inference based on GPU virtual memory management (VMM). vTensor addresses existing limitations by decoupling computation from memory defragmentation and offering dynamic extensibility. Our framework employs a CPU-GPU heterogeneous approach, ensuring efficient, fragmentation-free memory management while accommodating various computation kernels across different LLM architectures. Experimental results indicate that vTensor achieves an average speedup of 1.86x across different models, with up to 2.42x in multi-turn chat scenarios. Additionally, vTensor provides average speedups of 2.12x and 3.15x in kernel evaluation, reaching up to 3.92x and 3.27x compared to SGLang Triton prefix-prefilling kernels and vLLM paged Attention kernel, respectively. Furthermore, it frees approximately 71.25% (57GB) of memory on the NVIDIA A100 GPU compared to vLLM, enabling more memory-intensive workloads.
Learn to Teach: Improve Sample Efficiency in Teacher-student Learning for Sim-to-Real Transfer
Feb 09, 2024



Simulation-to-reality (sim-to-real) transfer is a fundamental problem for robot learning. Domain Randomization, which adds randomization during training, is a powerful technique that effectively addresses the sim-to-real gap. However, the noise in observations makes learning significantly harder. Recently, studies have shown that employing a teacher-student learning paradigm can accelerate training in randomized environments. Learned with privileged information, a teacher agent can instruct the student agent to operate in noisy environments. However, this approach is often not sample efficient as the experience collected by the teacher is discarded completely when training the student, wasting information revealed by the environment. In this work, we extend the teacher-student learning paradigm by proposing a sample efficient learning framework termed Learn to Teach (L2T) that recycles experience collected by the teacher agent. We observe that the dynamics of the environments for both agents remain unchanged, and the state space of the teacher is coupled with the observation space of the student. We show that a single-loop algorithm can train both the teacher and student agents under both Reinforcement Learning and Inverse Reinforcement Learning contexts. We implement variants of our methods, conduct experiments on the MuJoCo benchmark, and apply our methods to the Cassie robot locomotion problem. Extensive experiments show that our method achieves competitive performance while only requiring environmental interaction with the teacher.
Infer and Adapt: Bipedal Locomotion Reward Learning from Demonstrations via Inverse Reinforcement Learning
Sep 28, 2023



Enabling bipedal walking robots to learn how to maneuver over highly uneven, dynamically changing terrains is challenging due to the complexity of robot dynamics and interacted environments. Recent advancements in learning from demonstrations have shown promising results for robot learning in complex environments. While imitation learning of expert policies has been well-explored, the study of learning expert reward functions is largely under-explored in legged locomotion. This paper brings state-of-the-art Inverse Reinforcement Learning (IRL) techniques to solving bipedal locomotion problems over complex terrains. We propose algorithms for learning expert reward functions, and we subsequently analyze the learned functions. Through nonlinear function approximation, we uncover meaningful insights into the expert's locomotion strategies. Furthermore, we empirically demonstrate that training a bipedal locomotion policy with the inferred reward functions enhances its walking performance on unseen terrains, highlighting the adaptability offered by reward learning.
MovieChat: From Dense Token to Sparse Memory for Long Video Understanding
Jul 31, 2023



Recently, integrating video foundation models and large language models to build a video understanding system overcoming the limitations of specific pre-defined vision tasks. Yet, existing systems can only handle videos with very few frames. For long videos, the computation complexity, memory cost, and long-term temporal connection are the remaining challenges. Inspired by Atkinson-Shiffrin memory model, we develop an memory mechanism including a rapidly updated short-term memory and a compact thus sustained long-term memory. We employ tokens in Transformers as the carriers of memory. MovieChat achieves state-of-the-art performace in long video understanding.
Inverse Reinforcement Learning with the Average Reward Criterion
May 24, 2023

We study the problem of Inverse Reinforcement Learning (IRL) with an average-reward criterion. The goal is to recover an unknown policy and a reward function when the agent only has samples of states and actions from an experienced agent. Previous IRL methods assume that the expert is trained in a discounted environment, and the discount factor is known. This work alleviates this assumption by proposing an average-reward framework with efficient learning algorithms. We develop novel stochastic first-order methods to solve the IRL problem under the average-reward setting, which requires solving an Average-reward Markov Decision Process (AMDP) as a subproblem. To solve the subproblem, we develop a Stochastic Policy Mirror Descent (SPMD) method under general state and action spaces that needs $\mathcal{{O}}(1/\varepsilon)$ steps of gradient computation. Equipped with SPMD, we propose the Inverse Policy Mirror Descent (IPMD) method for solving the IRL problem with a $\mathcal{O}(1/\varepsilon^2)$ complexity. To the best of our knowledge, the aforementioned complexity results are new in IRL. Finally, we corroborate our analysis with numerical experiments using the MuJoCo benchmark and additional control tasks.
Stochastic first-order methods for average-reward Markov decision processes
May 19, 2022
We study the problem of average-reward Markov decision processes (AMDPs) and develop novel first-order methods with strong theoretical guarantees for both policy evaluation and optimization. Existing on-policy evaluation methods suffer from sub-optimal convergence rates as well as failure in handling insufficiently random policies, e.g., deterministic policies, for lack of exploration. To remedy these issues, we develop a novel variance-reduced temporal difference (VRTD) method with linear function approximation for randomized policies along with optimal convergence guarantees, and an exploratory variance-reduced temporal difference (EVRTD) method for insufficiently random policies with comparable convergence guarantees. We further establish linear convergence rate on the bias of policy evaluation, which is essential for improving the overall sample complexity of policy optimization. On the other hand, compared with intensive research interest in finite sample analysis of policy gradient methods for discounted MDPs, existing studies on policy gradient methods for AMDPs mostly focus on regret bounds under restrictive assumptions on the underlying Markov processes (see, e.g., Abbasi-Yadkori et al., 2019), and they often lack guarantees on the overall sample complexities. Towards this end, we develop an average-reward variant of the stochastic policy mirror descent (SPMD) (Lan, 2022). We establish the first $\widetilde{\mathcal{O}}(\epsilon^{-2})$ sample complexity for solving AMDPs with policy gradient method under both the generative model (with unichain assumption) and Markovian noise model (with ergodic assumption). This bound can be further improved to $\widetilde{\mathcal{O}}(\epsilon^{-1})$ for solving regularized AMDPs. Our theoretical advantages are corroborated by numerical experiments.