 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Mirror Descent for Reinforcement Learning
Apr 07, 2026Value iteration-type methods have been extensively studied for computing a nearly optimal value function in reinforcement learning (RL). Under a generative sampling model, these methods can achieve sharper sample complexity than policy optimization approaches, particularly in their dependence on the discount factor. In practice, they are often employed for offline training or in simulated environments. In this paper, we consider discounted Markov decision processes with state space S, action space A, discount factor $γ\in(0,1)$ and costs in $[0,1]$. We introduce a novel value optimization method, termed value mirror descent (VMD), which integrates mirror descent from convex optimization into the classical value iteration framework. In the deterministic setting with known transition kernels, we show that VMD converges linearly. For the stochastic setting with a generative model, we develop a stochastic variant, SVMD, which incorporates variance reduction commonly used in stochastic value iteration-type methods. For RL problems with general convex regularizers, SVMD attains a near-optimal sample complexity of $\tilde{O}(|S||A|(1-γ)^{-3}ε^{-2})$. Moreover, we establish that the Bregman divergence between the generated and optimal policies remains bounded throughout the iterations. This property is absent in existing stochastic value iteration-type methods but is important for enabling effective online (continual) learning following offline training. Under a strongly convex regularizer, SVMD achieves sample complexity of $\tilde{O}(|S||A|(1-γ)^{-5}ε^{-1})$, improving performance in the high-accuracy regime. Furthermore, we prove convergence of the generated policy to the optimal policy. Overall, the proposed method, its analysis, and the resulting guarantees, constitute new contributions to the RL and optimization literature.
Stochastic Auto-conditioned Fast Gradient Methods with Optimal Rates
Apr 07, 2026Achieving optimal rates for stochastic composite convex optimization without prior knowledge of problem parameters remains a central challenge. In the deterministic setting, the auto-conditioned fast gradient method has recently been proposed to attain optimal accelerated rates without line-search procedures or prior knowledge of the Lipschitz smoothness constant, providing a natural prototype for parameter-free acceleration. However, extending this approach to the stochastic setting has proven technically challenging and remains open. Existing parameter-free stochastic methods either fail to achieve accelerated rates or rely on restrictive assumptions, such as bounded domains, bounded gradients, prior knowledge of the iteration horizon, or strictly sub-Gaussian noise. To address these limitations, we propose a stochastic variant of the auto-conditioned fast gradient method, referred to as stochastic AC-FGM. The proposed method is fully adaptive to the Lipschitz constant, the iteration horizon, and the noise level, enabling both adaptive stepsize selection and adaptive mini-batch sizing without line-search procedures. Under standard bounded conditional variance assumptions, we show that stochastic AC-FGM achieves the optimal iteration complexity of $O(1/\sqrt{\varepsilon})$ and the optimal sample complexity of $O(1/\varepsilon^2)$.
Actor-Accelerated Policy Dual Averaging for Reinforcement Learning in Continuous Action Spaces
Mar 10, 2026Policy Dual Averaging (PDA) offers a principled Policy Mirror Descent (PMD) framework that more naturally admits value function approximation than standard PMD, enabling the use of approximate advantage (or Q-) functions while retaining strong convergence guarantees. However, applying PDA in continuous state and action spaces remains computationally challenging, since action selection involves solving an optimization sub-problem at each decision step. In this paper, we propose \textit{actor-accelerated PDA}, which uses a learned policy network to approximate the solution of the optimization sub-problems, yielding faster runtimes while maintaining convergence guarantees. We provide a theoretical analysis that quantifies how actor approximation error impacts the convergence of PDA under suitable assumptions. We then evaluate its performance on several benchmarks in robotics, control, and operations research problems. Actor-accelerated PDA achieves superior performance compared to popular on-policy baselines such as Proximal Policy Optimization (PPO). Overall, our results bridge the gap between the theoretical advantages of PDA and its practical deployment in continuous-action problems with function approximation.
One-Sided Matrix Completion from Ultra-Sparse Samples
Jan 18, 2026Matrix completion is a classical problem that has received recurring interest across a wide range of fields. In this paper, we revisit this problem in an ultra-sparse sampling regime, where each entry of an unknown, $n\times d$ matrix $M$ (with $n \ge d$) is observed independently with probability $p = C / d$, for a fixed integer $C \ge 2$. This setting is motivated by applications involving large, sparse panel datasets, where the number of rows far exceeds the number of columns. When each row contains only $C$ entries -- fewer than the rank of $M$ -- accurate imputation of $M$ is impossible. Instead, we estimate the row span of $M$ or the averaged second-moment matrix $T = M^{\top} M / n$. The empirical second-moment matrix computed from observed entries exhibits non-random and sparse missingness. We propose an unbiased estimator that normalizes each nonzero entry of the second moment by its observed frequency, followed by gradient descent to impute the missing entries of $T$. The normalization divides a weighted sum of $n$ binomial random variables by the total number of ones. We show that the estimator is unbiased for any $p$ and enjoys low variance. When the row vectors of $M$ are drawn uniformly from a rank-$r$ factor model satisfying an incoherence condition, we prove that if $n \ge O({d r^5 ε^{-2} C^{-2} \log d})$, any local minimum of the gradient-descent objective is approximately global and recovers $T$ with error at most $ε^2$. Experiments on both synthetic and real-world data validate our approach. On three MovieLens datasets, our algorithm reduces bias by $88\%$ relative to baseline estimators. We also empirically validate the linear sampling complexity of $n$ relative to $d$ on synthetic data. On an Amazon reviews dataset with sparsity $10^{-7}$, our method reduces the recovery error of $T$ by $59\%$ and $M$ by $38\%$ compared to baseline methods.
* 41 pages
Global Solutions to Non-Convex Functional Constrained Problems with Hidden Convexity
Nov 13, 2025Constrained non-convex optimization is fundamentally challenging, as global solutions are generally intractable and constraint qualifications may not hold. However, in many applications, including safe policy optimization in control and reinforcement learning, such problems possess hidden convexity, meaning they can be reformulated as convex programs via a nonlinear invertible transformation. Typically such transformations are implicit or unknown, making the direct link with the convex program impossible. On the other hand, (sub-)gradients with respect to the original variables are often accessible or can be easily estimated, which motivates algorithms that operate directly in the original (non-convex) problem space using standard (sub-)gradient oracles. In this work, we develop the first algorithms to provably solve such non-convex problems to global minima. First, using a modified inexact proximal point method, we establish global last-iterate convergence guarantees with $\widetilde{\mathcal{O}}(\varepsilon^{-3})$ oracle complexity in non-smooth setting. For smooth problems, we propose a new bundle-level type method based on linearly constrained quadratic subproblems, improving the oracle complexity to $\widetilde{\mathcal{O}}(\varepsilon^{-1})$. Surprisingly, despite non-convexity, our methodology does not require any constraint qualifications, can handle hidden convex equality constraints, and achieves complexities matching those for solving unconstrained hidden convex optimization.
Can SGD Handle Heavy-Tailed Noise?
Aug 06, 2025Stochastic Gradient Descent (SGD) is a cornerstone of large-scale optimization, yet its theoretical behavior under heavy-tailed noise -- common in modern machine learning and reinforcement learning -- remains poorly understood. In this work, we rigorously investigate whether vanilla SGD, devoid of any adaptive modifications, can provably succeed under such adverse stochastic conditions. Assuming only that stochastic gradients have bounded $p$-th moments for some $p \in (1, 2]$, we establish sharp convergence guarantees for (projected) SGD across convex, strongly convex, and non-convex problem classes. In particular, we show that SGD achieves minimax optimal sample complexity under minimal assumptions in the convex and strongly convex regimes: $\mathcal{O}(\varepsilon^{-\frac{p}{p-1}})$ and $\mathcal{O}(\varepsilon^{-\frac{p}{2(p-1)}})$, respectively. For non-convex objectives under H\"older smoothness, we prove convergence to a stationary point with rate $\mathcal{O}(\varepsilon^{-\frac{2p}{p-1}})$, and complement this with a matching lower bound specific to SGD with arbitrary polynomial step-size schedules. Finally, we consider non-convex Mini-batch SGD under standard smoothness and bounded central moment assumptions, and show that it also achieves a comparable $\mathcal{O}(\varepsilon^{-\frac{2p}{p-1}})$ sample complexity with a potential improvement in the smoothness constant. These results challenge the prevailing view that heavy-tailed noise renders SGD ineffective, and establish vanilla SGD as a robust and theoretically principled baseline -- even in regimes where the variance is unbounded.
Projected gradient methods for nonconvex and stochastic optimization: new complexities and auto-conditioned stepsizes
Dec 18, 2024We present a novel class of projected gradient (PG) methods for minimizing a smooth but not necessarily convex function over a convex compact set. We first provide a novel analysis of the "vanilla" PG method, achieving the best-known iteration complexity for finding an approximate stationary point of the problem. We then develop an "auto-conditioned" projected gradient (AC-PG) variant that achieves the same iteration complexity without requiring the input of the Lipschitz constant of the gradient or any line search procedure. The key idea is to estimate the Lipschitz constant using first-order information gathered from the previous iterations, and to show that the error caused by underestimating the Lipschitz constant can be properly controlled. We then generalize the PG methods to the stochastic setting, by proposing a stochastic projected gradient (SPG) method and a variance-reduced stochastic gradient (VR-SPG) method, achieving new complexity bounds in different oracle settings. We also present auto-conditioned stepsize policies for both stochastic PG methods and establish comparable convergence guarantees.
Auto-conditioned primal-dual hybrid gradient method and alternating direction method of multipliers
Oct 02, 2024Line search procedures are often employed in primal-dual methods for bilinear saddle point problems, especially when the norm of the linear operator is large or difficult to compute. In this paper, we demonstrate that line search is unnecessary by introducing a novel primal-dual method, the auto-conditioned primal-dual hybrid gradient (AC-PDHG) method, which achieves optimal complexity for solving bilinear saddle point problems. AC-PDHG is fully adaptive to the linear operator, using only past iterates to estimate its norm. We further tailor AC-PDHG to solve linearly constrained problems, providing convergence guarantees for both the optimality gap and constraint violation. Moreover, we explore an important class of linearly constrained problems where both the objective and constraints decompose into two parts. By incorporating the design principles of AC-PDHG into the preconditioned alternating direction method of multipliers (ADMM), we propose the auto-conditioned alternating direction method of multipliers (AC-ADMM), which guarantees convergence based solely on one part of the constraint matrix and fully adapts to it, eliminating the need for line search. Finally, we extend both AC-PDHG and AC-ADMM to solve bilinear problems with an additional smooth term. By integrating these methods with a novel acceleration scheme, we attain optimal iteration complexities under the single-oracle setting.
Strongly-Polynomial Time and Validation Analysis of Policy Gradient Methods
Sep 28, 2024
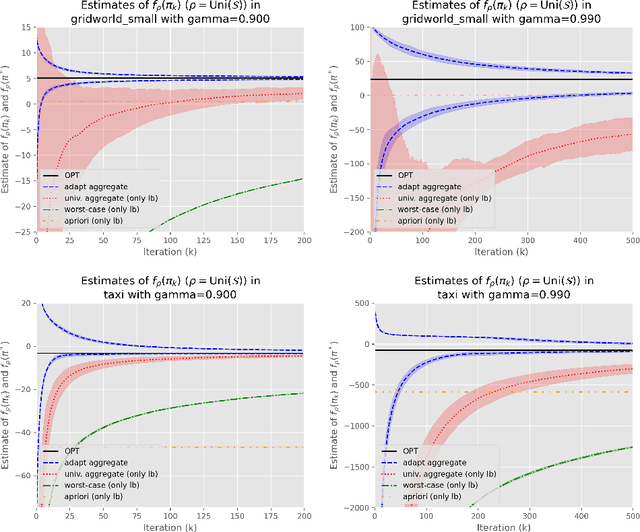

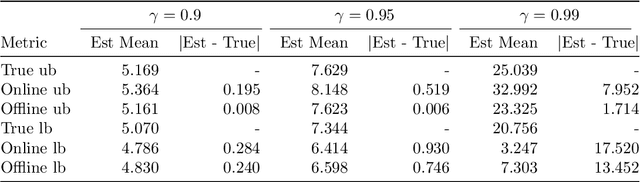
Reinforcement learning lacks a principled measure of optimality, causing research to rely on algorithm-to-algorithm or baselines comparisons with no certificate of optimality. Focusing on finite state and action Markov decision processes (MDP), we develop a simple, computable gap function that provides both upper and lower bounds on the optimality gap. Therefore, convergence of the gap function is a stronger mode of convergence than convergence of the optimality gap, and it is equivalent to a new notion we call distribution-free convergence, where convergence is independent of any problem-dependent distribution. We show the basic policy mirror descent exhibits fast distribution-free convergence for both the deterministic and stochastic setting. We leverage the distribution-free convergence to a uncover a couple new results. First, the deterministic policy mirror descent can solve unregularized MDPs in strongly-polynomial time. Second, accuracy estimates can be obtained with no additional samples while running stochastic policy mirror descent and can be used as a termination criteria, which can be verified in the validation step.
A simple uniformly optimal method without line search for convex optimization
Oct 27, 2023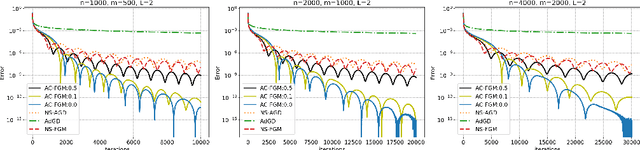
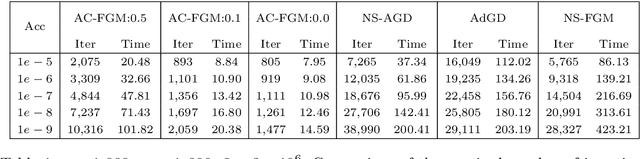
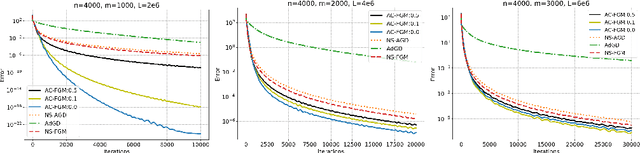
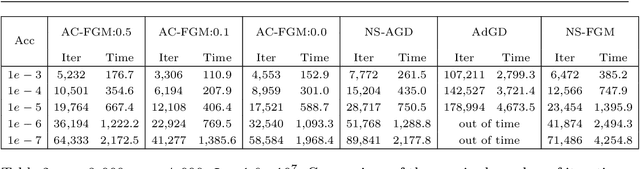
Line search (or backtracking) procedures have been widely employed into first-order methods for solving convex optimization problems, especially those with unknown problem parameters (e.g., Lipschitz constant). In this paper, we show that line search is superfluous in attaining the optimal rate of convergence for solving a convex optimization problem whose parameters are not given a priori. In particular, we present a novel accelerated gradient descent type algorithm called auto-conditioned fast gradient method (AC-FGM) that can achieve an optimal $\mathcal{O}(1/k^2)$ rate of convergence for smooth convex optimization without requiring the estimate of a global Lipschitz constant or the employment of line search procedures. We then extend AC-FGM to solve convex optimization problems with H\"{o}lder continuous gradients and show that it automatically achieves the optimal rates of convergence uniformly for all problem classes with the desired accuracy of the solution as the only input. Finally, we report some encouraging numerical results that demonstrate the advantages of AC-FGM over the previously developed parameter-free methods for convex optimization.