 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Reward Barrier: Accelerating Tree-of-Thought Reasoning via Speculative Exploration
May 11, 2026Tree-of-Thought (ToT) reasoning structures Large Language Model (LLM) inference as a tree-based search, demonstrating strong potential for solving complex mathematical and programming tasks. However, its efficiency is constrained by the reward dependency barrier -- a synchronization bottleneck caused by sequential reward-guided exploration that limits search parallelism and introduces substantial latency. Prior system optimizations, mainly designed for linear Chain-of-Thought (CoT) reasoning, cannot address these challenges, leaving the efficiency of ToT underexplored. To enhance ToT reasoning efficiency, we observe that the reasoning paths can be explored speculatively to break the reward synchronization barrier. Therefore, in this paper, we propose SPEX and introduce three key techniques: (i) intra-query speculative path selection to predict and expand high-potential branches of ToT, (ii) inter-query budget allocation to balance speculative resource allocation across queries dynamically, and (iii) adaptive early termination to prune deep and redundant branches for a skewed search tree. We implement SPEX on top of the SGLang framework and evaluate it across diverse ToT algorithms and LLMs. Extensive experiments show that SPEX achieves $1.2 \sim 3 \times$ speedup for different ToT reasoning algorithms. Moreover, SPEX synergizes with token-level speculative decoding, achieving cumulative speedups of up to $4.1\times$. Ablation studies further confirm the contributions of each technique. Overall, SPEX represents a significant step toward efficient and scalable ToT reasoning, unlocking the parallelism required for high-performance inference-time scaling for LLMs.
HyPER: Bridging Exploration and Exploitation for Scalable LLM Reasoning with Hypothesis Path Expansion and Reduction
Feb 06, 2026Scaling test-time compute with multi-path chain-of-thought improves reasoning accuracy, but its effectiveness depends critically on the exploration-exploitation trade-off. Existing approaches address this trade-off in rigid ways: tree-structured search hard-codes exploration through brittle expansion rules that interfere with post-trained reasoning, while parallel reasoning over-explores redundant hypothesis paths and relies on weak answer selection. Motivated by the observation that the optimal balance is phase-dependent and that correct and incorrect reasoning paths often diverge only at late stages, we reformulate test-time scaling as a dynamic expand-reduce control problem over a pool of hypotheses. We propose HyPER, a training-free online control policy for multi-path decoding in mixture-of-experts models that reallocates computation under a fixed budget using lightweight path statistics. HyPER consists of an online controller that transitions from exploration to exploitation as the hypothesis pool evolves, a token-level refinement mechanism that enables efficient generation-time exploitation without full-path resampling, and a length- and confidence-aware aggregation strategy for reliable answer-time exploitation. Experiments on four mixture-of-experts language models across diverse reasoning benchmarks show that HyPER consistently achieves a superior accuracy-compute trade-off, improving accuracy by 8 to 10 percent while reducing token usage by 25 to 40 percent.
RelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
Serving Large Language Models on Huawei CloudMatrix384
Jun 15, 2025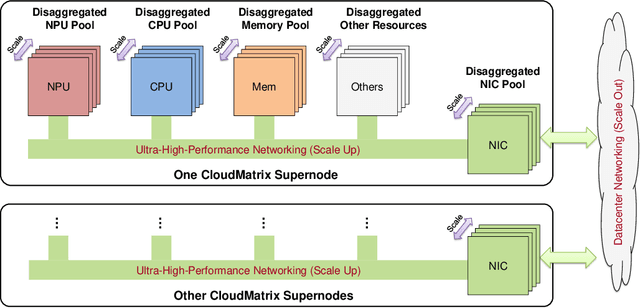
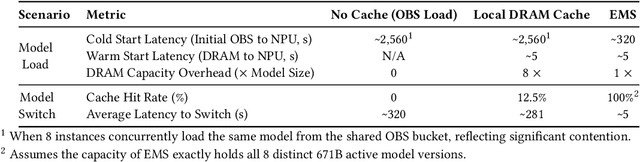
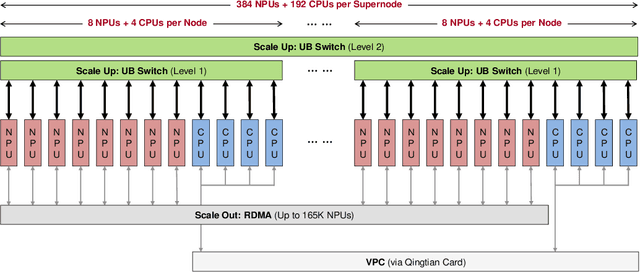
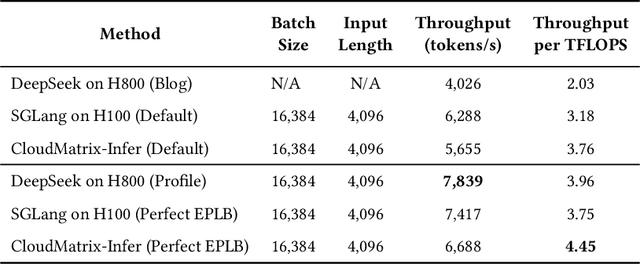
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
Efficient Unified Caching for Accelerating Heterogeneous AI Workloads
Jun 14, 2025Modern AI clusters, which host diverse workloads like data pre-processing, training and inference, often store the large-volume data in cloud storage and employ caching frameworks to facilitate remote data access. To avoid code-intrusion complexity and minimize cache space wastage, it is desirable to maintain a unified cache shared by all the workloads. However, existing cache management strategies, designed for specific workloads, struggle to handle the heterogeneous AI workloads in a cluster -- which usually exhibit heterogeneous access patterns and item storage granularities. In this paper, we propose IGTCache, a unified, high-efficacy cache for modern AI clusters. IGTCache leverages a hierarchical access abstraction, AccessStreamTree, to organize the recent data accesses in a tree structure, facilitating access pattern detection at various granularities. Using this abstraction, IGTCache applies hypothesis testing to categorize data access patterns as sequential, random, or skewed. Based on these detected access patterns and granularities, IGTCache tailors optimal cache management strategies including prefetching, eviction, and space allocation accordingly. Experimental results show that IGTCache increases the cache hit ratio by 55.6% over state-of-the-art caching frameworks, reducing the overall job completion time by 52.2%.
Injecting Adrenaline into LLM Serving: Boosting Resource Utilization and Throughput via Attention Disaggregation
Mar 26, 2025In large language model (LLM) serving systems, executing each request consists of two phases: the compute-intensive prefill phase and the memory-intensive decoding phase. To prevent performance interference between the two phases, current LLM serving systems typically adopt prefill-decoding disaggregation, where the two phases are split across separate machines. However, we observe this approach leads to significant resource underutilization. Specifically, prefill instances that are compute-intensive suffer from low memory utilization, while decoding instances that are memory-intensive experience low compute utilization. To address this problem, this paper proposes Adrenaline, an attention disaggregation and offloading mechanism designed to enhance resource utilization and performance in LLM serving systems. Adrenaline's key innovation lies in disaggregating part of the attention computation in the decoding phase and offloading them to prefill instances. The memory-bound nature of decoding-phase attention computation inherently enables an effective offloading strategy, yielding two complementary advantages: 1) improved memory capacity and bandwidth utilization in prefill instances, and 2) increased decoding batch sizes that enhance compute utilization in decoding instances, collectively boosting overall system performance. Adrenaline achieves these gains through three key techniques: low-latency decoding synchronization, resource-efficient prefill colocation, and load-aware offloading scheduling. Experimental results show that Adrenaline achieves 2.28x higher memory capacity and 2.07x better memory bandwidth utilization in prefill instances, up to 1.67x improvements in compute utilization for decoding instances, and 1.68x higher overall inference throughput compared to state-of-the-art systems.
AdaSkip: Adaptive Sublayer Skipping for Accelerating Long-Context LLM Inference
Jan 04, 2025



Long-context large language models (LLMs) inference is increasingly critical, motivating a number of studies devoted to alleviating the substantial storage and computational costs in such scenarios. Layer-wise skipping methods are promising optimizations but rarely explored in long-context inference. We observe that existing layer-wise skipping strategies have several limitations when applied in long-context inference, including the inability to adapt to model and context variability, disregard for sublayer significance, and inapplicability for the prefilling phase. This paper proposes \sysname, an adaptive sublayer skipping method specifically designed for long-context inference. \sysname adaptively identifies less important layers by leveraging on-the-fly similarity information, enables sublayer-wise skipping, and accelerates both the prefilling and decoding phases. The effectiveness of \sysname is demonstrated through extensive experiments on various long-context benchmarks and models, showcasing its superior inference performance over existing baselines.
AttentionStore: Cost-effective Attention Reuse across Multi-turn Conversations in Large Language Model Serving
Mar 23, 2024Interacting with humans through multi-turn conversations is a fundamental feature of large language models (LLMs). However, existing LLM serving engines for executing multi-turn conversations are inefficient due to the need to repeatedly compute the key-value (KV) caches of historical tokens, incurring high serving costs. To address the problem, this paper proposes AttentionStore, a new attention mechanism that enables the reuse of KV caches (i.e., attention reuse) across multi-turn conversations, significantly reducing the repetitive computation overheads. AttentionStore maintains a hierarchical KV caching system that leverages cost-effective memory/storage mediums to save KV caches for all requests. To reduce KV cache access overheads from slow mediums, AttentionStore employs layer-wise pre-loading and asynchronous saving schemes to overlap the KV cache access with the GPU computation. To ensure that the KV caches to be accessed are placed in the fastest hierarchy, AttentionStore employs scheduler-aware fetching and eviction schemes to consciously place the KV caches in different layers based on the hints from the inference job scheduler. To avoid the invalidation of the saved KV caches incurred by context window overflow, AttentionStore enables the saved KV caches to remain valid via decoupling the positional encoding and effectively truncating the KV caches. Extensive experimental results demonstrate that AttentionStore significantly decreases the time to the first token (TTFT) by up to 88%, improves the prompt prefilling throughput by 8.2$\times$ for multi-turn conversations, and reduces the end-to-end inference cost by up to 56%. For long sequence inference, AttentionStore reduces the TTFT by up to 95% and improves the prompt prefilling throughput by 22$\times$.
A Scalable Learned Index Scheme in Storage Systems
May 08, 2019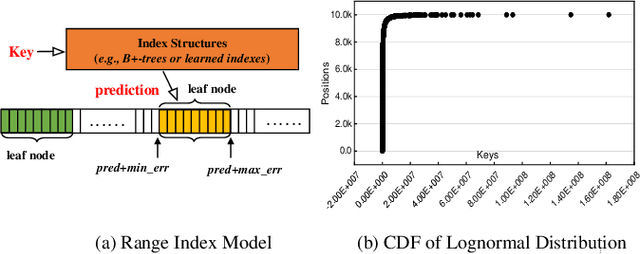


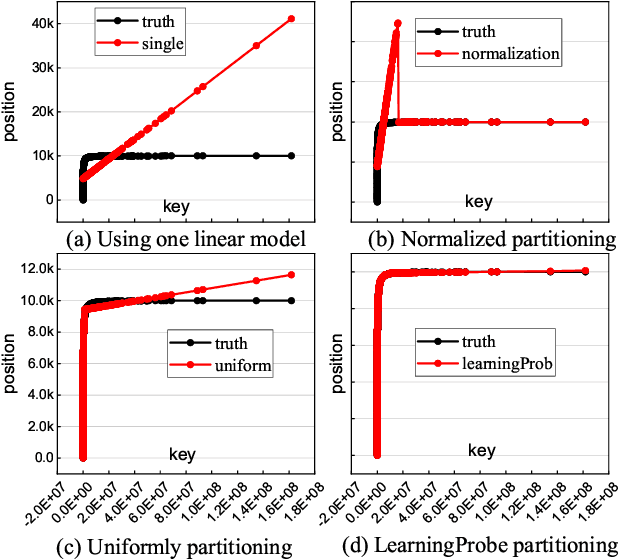
Index structures are important for efficient data access, which have been widely used to improve the performance in many in-memory systems. Due to high in-memory overheads, traditional index structures become difficult to process the explosive growth of data, let alone providing low latency and high throughput performance with limited system resources. The promising learned indexes leverage deep-learning models to complement existing index structures and obtain significant memory savings. However, the learned indexes fail to become scalable due to the heavy inter-model dependency and expensive retraining. To address these problems, we propose a scalable learned index scheme to construct different linear regression models according to the data distribution. Moreover, the used models are independent so as to reduce the complexity of retraining and become easy to partition and store the data into different pages, blocks or distributed systems. Our experimental results show that compared with state-of-the-art schemes, AIDEL improves the insertion performance by about 2$\times$ and provides comparable lookup performance, while efficiently supporting scalability.